Биномиальный закон распределения.
Определение: Случайная величина Х называется распределенной по биномиальному закону, если ее возможные значения 0,1,2, …, m, …,n, а соответствующие вероятности
 n. (1)
n. (1)
Где 0<p<1, q=1-p.
Закон распределения Пуассона.
Определение: Дискретная случайная величина Х имеет закон распределения Пуассона с параметром  =np>0, если она принимает значения 0,1,2,3,….,m,….(Бесконечное, но счетное множество значений) с вероятностями
=np>0, если она принимает значения 0,1,2,3,….,m,….(Бесконечное, но счетное множество значений) с вероятностями
 .
.
Непрерывной случайной величиной называется случайная величина Х, если ее функция распределения (интегральная функция распределения) представима в виде:

|
где f (x) – некоторая неотрицательная функция, такая что

|
Функция f (x) называется плотностью распределения вероятностей случайной величины X (дифференциальной функцией распределения).
Вероятность того, что непрерывная случайная величина X принимает значение в заданном промежутке, вычисляется следующим образом:

|
Примеры распределений вероятностей непрерывной случайной величины Х:
- равномерное распределение вероятностей непрерывной случайной величины;
- показательное распределение вероятностей непрерывной случайной величины;
- нормальное распределение вероятностей непрерывной случайной величины.
· Нормальный закон распределения (закон Гаусса)
·
· Плотность вероятности нормально распределённой случайной величины
· XX
· выражается формулой
·
· f(x)=1σ2π−−√exp(−(x−a)22σ2).
Он показал, что если случайная величина может рассматриваться как сумма большого числа малых слагаемых, то при достаточно общих условиях закон распределения этой случайной величины близок к нормальному независимо от того, каковы законы распределения отдельных слагаемых. А так как практически случайные величины в большинстве случаев бывают результатом действия множества причин, то нормальный закон оказывается наиболее распространённым законом распределения
Логарифмически нормальное распределение
Говорят, что случайная величина
YY
имеет логарифмически нормальное распределение (сокращённо логнормальное распределение), если её логарифм
lnY=XlnY=X
распределён нормально, то есть если
Y=eX,Y=eX,
где величина
XX
имеет нормальное распределение с параметрами
a,σ.a,σ.
Оно даёт распределение размеров частиц при дроблении, содержаний элементов в минералах в извержённых горных пародах, численности рыб в море и т.д. Встречается такое распределение во всех задачах, где логарифм рассматриваемой величины можно представить в виде суммы большого количества независимых равномерно малых величин:
Генеральная и выборочная совокупности
Генеральной совокупностью называется совокупность всех исследуемых в данном эксперименте элементов.
Выборочной совокупностью (или выборкой) называется конечная совокупность объектов, случайно отобранных из генеральной совокупности.
Вероятностная выборка:
1. Простая вероятностная выборка:
- простая повторная выборка. Использование такой выборки основывается на предположении, что каждый респондент с равной долей вероятности может попасть в выборку.
- простая бесповторная выборка.
2. Систематическая вероятностная выборка. Является упрощенным вариантом простой вероятностной выборки.
3. Серийная вероятностная выборка.
Невероятностные выборка (отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям- доступности, типичности, равного представительства и т.д.:
1.Квотная выборка- выборка строится как модель, которая воспроизводит структуру генеральной совокупности в виде квот изучаемых признаков.
2. Метод снежного кома.
3. Стихийная выборка.
Способы отбора:
1.Рандомизация или случайный отбор, используется для создания случайных выборок.
2.Попарный отбор- стратегия построения групп выборки, при котором составляются из субъектов, эквивалентных по значимым для эксперимента побочным параметрам.
3.Многоступенчатый способ построения выборки. При многоступенчатом отборе выборка строится в несколько этапов, причём на каждой стадии меняется единица отбора.
Функциональная зависимость - связь, при которой каждому значению независимой переменной х: соответствует точно определенное значение зависимой переменной у.
Статистическая зависимость -связь, при которой каждому значению независимой переменной х соответствует множество значений зависимой переменной у, причем неизвестно заранее, какое именно значение примет у
Частным случаем статистической зависимости является корреляционная зависимость - связь, при которой каждому значению независимой переменной х соответствует определенное математическое ожидание (среднее значение) зависимой переменной у.
Корреляционная связь является «неполной» зависимостью, которая проявляется не в каждом отдельном случае, а только в средних величинах при достаточно большом числе случаев.
Метод наименьших квадратов (МНК) — математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных. Он может использоваться для «решения» переопределенных систем уравнений (когда количество уравнений превышает количество неизвестных), для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений, для аппроксимации точечных значений некоторой функции.
Регрессио́нный анализ — статистический метод исследования влияния одной или нескольких независимых переменных {\displaystyle X_{1},X_{2},...,X_{p}}  на зависимую переменную {\displaystyle Y} . Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных (см. Ложная корреляция), а не причинно-следственные отношения.
на зависимую переменную {\displaystyle Y} . Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных (см. Ложная корреляция), а не причинно-следственные отношения.
Коэффициент корреляции - это мера линейной зависимости двух случайных величин в теории вероятностей и статистике
Случайным процессом называется семейство случайных величин  , заданных на вероятностном пространстве
, заданных на вероятностном пространстве 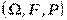 , где
, где  есть текущее время. Множество
есть текущее время. Множество  значений параметра называют областью определения случайного процесса, а множество
значений параметра называют областью определения случайного процесса, а множество  возможных значений
возможных значений  – пространством значений случайного процесса.
– пространством значений случайного процесса.
Случайный процесс, в отличие от детерминированного процесса, заранее предсказать невозможно. В качестве примеров случайных процессов можно рассмотреть броуновское движение частиц, работу телефонных станций, помехи в радиотехнических системах и т. д.
Если область определения случайного процесса представляет конечное или счетное множество отсчетов времени, то говорят, что  – случайный процесс с дискретным временем или случайная последовательность (цепь), а если область определения – континуум, то называют случайным процессом с непрерывным временем.
– случайный процесс с дискретным временем или случайная последовательность (цепь), а если область определения – континуум, то называют случайным процессом с непрерывным временем.
Статистической гипотезой называется любое предположение о виде или параметров неизвестного закона распределения В конкретной ситуации статистическую гипотезу формулируют как предположение на определенном уровне статистической значимости о свойствах генеральной совокупности по оценкам выборки
Статистическая гипотезу принято обозначать буквой Н (Hypothesis) Сформулированная гипотеза \"Н: а2 = 0,5 \"может читаться так:\" выдвинута статистическая гипотеза о том, что неизвестная дисперсия а2не отличается от значения 0,5 \"Гипотетическое утверждение или справедливым (истинным), или ложным (ошибочным), что требует его проверки
Нулевой (основной) называют выдвинутую гипотезу  .
.
Например, если нулевая гипотеза состоит в предположении, что математическое ожидание  нормального распределения равно 10, Коротко это записывают так: : =10;
нормального распределения равно 10, Коротко это записывают так: : =10;
Различают гипотезы, которые содержат только одно и более одного предположений.
Простой называют гипотезу, содержащую только одно предположение. Например, если 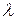 - параметр показательного распределения, то гипотеза : =5 – простая. Гипотеза : математическое ожидание нормального распределения равно 3 (
- параметр показательного распределения, то гипотеза : =5 – простая. Гипотеза : математическое ожидание нормального распределения равно 3 ( известно) – простая.
известно) – простая.
Сложной называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез. Например, сложная гипотеза  : >5 состоит из бесчисленного множества простых вида
: >5 состоит из бесчисленного множества простых вида  , где
, где 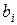 - любое число, большее 5. Гипотеза : математическое ожидание нормального распределения равно 3 ( неизвестно) – сложная.
- любое число, большее 5. Гипотеза : математическое ожидание нормального распределения равно 3 ( неизвестно) – сложная.
Ошибки первого рода и ошибки второго рода в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Ошибка первого рода состоит в том, что будет отвергнута нулевая гипотеза, хотя на самом деле она верна.
Ошибка второго рода состоит в том, что будет принята нулевая гипотеза, хотя в действительности верна конкурирующая.
Проверку выдвинутой гипотезы осуществляют статистическими методами, поэтому ее называют статистической проверкой гипотез. В итоге статистической проверки гипотезы может быть принято неправильное решение, т.е. могут быть допущены ошибки двух родов:
1) ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза;
2) ошибка второго рода состоит в том, что будет принята неправильная гипотеза.
Правильное решение может быть принято также в двух случаях:
1) гипотеза принимается, причем она и в действительности правильная;
2) гипотеза отвергается, причем она и в действительности неверна.