1. Чтобы сформировать расчетную таблицу 1 (последовательно выполняя пункты 1-7 лабораторной работы), необходимо использовать Мастер формул MS Excel. В данном пункте достаточно заполнить столбцы Y, X0, X1, X2.
Таблица 1 – Подготовка данных для оценивания линейной регрессии с двумя регрессорами (множественной регрессии)
| i | Y | X0 | X1 | X2 | Yx | E | E^2 | (Y-Yсред)^2 | (Yx-Yсред)^2 |
| 17,81 | 5,19 | 26,91 | 102,68 | 234,72 | |||||
| 21,48 | -3,48 | 12,12 | 229,02 | 135,76 | |||||
| 23,71 | 3,29 | 10,84 | 37,62 | 88,84 | |||||
| 31,89 | -2,89 | 8,33 | 17,08 | 1,56 | |||||
| 44,82 | -1,82 | 3,30 | 97,35 | 136,51 | |||||
| 29,36 | -6,36 | 40,46 | 102,68 | 14,23 | |||||
| 52,28 | 2,72 | 7,42 | 478,15 | 366,42 | |||||
| 42,53 | 4,47 | 19,97 | 192,28 | 88,33 | |||||
| 30,56 | 4,44 | 19,69 | 3,48 | 6,61 | |||||
| 40,49 | -2,49 | 6,18 | 23,68 | 54,07 | |||||
| 14,26 | -0,26 | 0,07 | 366,08 | 356,07 | |||||
| 50,05 | 0,95 | 0,90 | 319,22 | 286,18 | |||||
| 20,04 | -0,04 | 0,00 | 172,48 | 171,49 | |||||
| 38,62 | 0,38 | 0,14 | 34,42 | 30,12 | |||||
| 39,10 | -4,10 | 16,84 | 3,48 | 35,64 | |||||
| Среднее | 33,13 | 32,4 | 47,53 | Сумма | 2179,73 | 2006,56 | |||
| СКО | 12,05 | 13,34 | 6,13 |
Суммы и средние по столбцам в расчетной таблице 1 необходимо определить с помощью функций СУММ(…) и СРЗНАЧ(…).
2. Чтобы провести корреляционный анализ, из расчетной таблицы 1 необходимо рядом скопировать столбцы Y, X1, X2, а затем применить инструмент КОРРЕЛЯЦИЯ надстройки Пакет анализа. Нажав на кнопку Анализ данных, следует выбрать опцию Корреляция (рис.1).
Рис. 1. Выбор корреляционного анализа в Excel
На экране появится новое окно с опциями корреляционного анализа (рис.2).

Рис.2. Окно параметров корреляции в Excel
В поле Входной интервал необходимо выбрать таблицу со всеми исходными для корреляционного анализа. Опция «Группирование» дает возможность группировать переменные в таблице по столбцам (как принято традиционно) или по строкам. Опция Метки, если в ней указать «галочку», трактует первую строку данных как названия переменных. В разделе Параметры вывода можно устанавливать, куда выводятся результаты корреляции (обычно выводят результаты на этот же лист, так как удобно держать данные и результаты корреляции на одном листе). Чтобы оценить корреляцию в Excel во входном интервале укажем диапазон переменных Y, X1, X2, укажем «галочку» в опции Метки, чтобы трактовать первую строку данных как названия переменных (рис.3).

Рис. 3. Окно параметров корреляции с введенными значениями в Excel
Далее, нажав на кнопку Ок, получаем результаты (рис.4).

Рис. 4. Вывод результатов оценивания корреляции в Excel
В столбце Y на пересечении со строками X1, X2 указаны линейные коэффициенты парной корреляции каждого регрессора (Х1, Х2) с регрессантом (Y). Наличие умеренной и тесной статистической взаимосвязи говорит о целесообразности включения регрессанта во множественную регрессию.
Комментарий: При наличии слабой взаимосвязи регрессанта с регрессором или ее практическом отсутствии коэффициент регрессии при таком регрессанте скорее всего будет незначим. Обычно из множественной регрессии исключают регрессоры (факторы), коэффициенты при которых незначимы, чтобы не терять эффективность оценок, но незначимую константу принято оставлять, чтобы избежать смещения оценок и иметь возможность интерпретировать R2.
Вывод 1: Согласно шкале Чеддока-Снедекора наблюдается умеренная обратная статистическая взаимосвязь между объемом продаж и ценой (Ryx1= -0,58), а также тесная прямая статистическая взаимосвязь между объемом продаж и расходами на рекламу (Ryx2= 0,75). В столбцах X1, X2 на пересечении со строками X1, X2 указан линейный коэффициент парной корреляции между регрессорами (Х1, Х2) – межфакторная корреляция. Согласно шкале Чеддока-Снедекора практически отсутствует статистическая взаимосвязь между факторами (Rx1x2 = 0,03), что показывает о соблюдении одного из требований к построению множественной регрессии: в уравнение включаются регрессоры, которые между собой не взаимосвязаны.
3. Чтобы оценить параметры линейного уравнения множественной регрессии  «вручную» матрично-векторным способом, необходимо пошагово применить формулу B=(X’X)-1 X’Y, используя встроенные в Excel функции для операций с матрицами.
«вручную» матрично-векторным способом, необходимо пошагово применить формулу B=(X’X)-1 X’Y, используя встроенные в Excel функции для операций с матрицами.
1 шаг: получение матрицы X’ путем транспонирования структурной матрицы X (диапазон переменных X0, X1, X2). Под расчетной таблицей 1 выделяем пустой массив ячеек размера 3 строки и 15 столбцов. Затем в Главном меню MS Excel выберем: Формулы – Вставить функцию – Ссылки и массивы – ТРАНСП (…). В окне параметров функции ТРАНСП (…) в поле Массив необходимо указать диапазон переменных (X0, X1, X2), которые надо транспонировать. Далее, нажав на кнопку Ок, важно правильно раскрыть результат транспонирования. Для этого необходимо нажать на клавишу F2 (или в Excel поместить курсор мыши в командную строку формул), а затем — на сочетание клавиш CTRL + SHIFT + ВВОД.
2 шаг: определение произведения матриц X’X. Под расчетной таблицей 1 выделяем пустой массив ячеек размера 3 строки и 3 столбца. Затем в Главном меню MS Excel выберем: Формулы – Вставить функцию – Математические – МУМНОЖ (…).В окне параметров функции МУМНОЖ (…) в поле Массив 1 необходимо указать диапазон матрицы X’, в поле Массив 2 необходимо указать диапазон матрицы Х (переменные X0, X1, X2). Далее, нажав на кнопку Ок, важно правильно раскрыть результат произведения матриц. Для этого необходимо нажать на клавишу F2 (или в Excel поместить курсор мыши в командную строку формул), а затем — на сочетание клавиш CTRL + SHIFT + ВВОД.
3 шаг: определение произведения X’Y. Под расчетной таблицей 1 выделяем пустой массив ячеек размера 3 строки и 1 столбец.Затем в Главном меню MS Excel выберем: Формулы – Вставить функцию – Математические – МУМНОЖ (…).В окне параметров функции МУМНОЖ (…) в поле Массив 1 необходимо указать диапазон матрицы X’, в поле Массив2 необходимо указать диапазон столбца Y. Далее, нажав на кнопку Ок, важно правильно раскрыть результат произведения. Для этого необходимо нажать на клавишу F2 (или в Excel поместить курсор мыши в командную строку формул), а затем — на сочетание клавиш CTRL + SHIFT + ВВОД.
4 шаг: определение обратной матрицы (X’X)-1. Под расчетной таблицей 1 выделяем пустой массив ячеек размера 3 строки и 3 столбца.Затем в Главном меню MS Excel выберем: Формулы – Вставить функцию – Математические – МОБР (…). В окне параметров функции МОБР (…) в поле Массив необходимо указать диапазон произведения матриц X’X, полученного на 2 шаге. Далее, нажав на кнопку Ок, важно правильно раскрыть результат обратной матрицы. Для этого необходимо нажать на клавишу F2 (или в Excel поместить курсор мыши в командную строку формул), а затем — на сочетание клавиш CTRL + SHIFT + ВВОД.
5 шаг: определение вектора коэффициентов B = (X’X)-1 X’Y. Под расчетной таблицей 1 выделяем пустой массив ячеек размера 3 строки и 1 столбец.Затем в Главном меню MS Excel выберем: Формулы – Вставить функцию – Математические – МУМНОЖ (…).В окне параметров функции МУМНОЖ (…) в поле Массив 1 необходимо указать диапазон обратной матрицы (X’X)-1, в поле Массив 2 необходимо указать диапазон произведения X’Y. Далее, нажав на кнопку Ок, важно правильно раскрыть результат произведения. Для этого необходимо нажать на клавишу F2 (или в Excel поместить курсор мыши в командную строку формул), а затем — на сочетание клавиш CTRL + SHIFT + ВВОД.
Результат «ручной» реализации матрично-векторного способа представлен на рисунке 5.

Рис. 5. МНК-оценки множественной регрессии, полученные «вручную»
4. Экономическая интерпретация МНК-оценок. Запишем линейное уравнение множественной регрессии 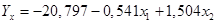 .
.
Вывод 2: Полученные МНК-оценки коэффициентов можно интерпретировать следующим образом: при увеличении цены на одну денежную единицу объем продаж при прочих равных условиях снизится на 0,541 денежных единиц, если расходы на рекламу возрастают на 1 ден. единицу, то объем продаж увеличивается на 1,503 ден. единиц.
5. Чтобы вычислить предсказанные моделью значения Yx в расчетной таблице 1, необходимо в уравнение множественной регрессии вместо x1 и х2 последовательно, начиная с первого, подставить исходные наблюдаемые значения переменных X1 и X2 из расчетной таблицы 1. Полученные предсказанные моделью значения Yx указать в соответствующем столбце расчетной таблицы 1.
6. Остаток регрессии – это ошибка, несвязка (discrepancy) между наблюдаемым значением зависимой переменной Yi и предсказанными моделью значениями Yx: Y-Yx. Чтобы вычислить остатки регрессии и их квадраты в расчетной таблице 1 необходимо заполнить столбцы: E = (Y-Yx), E^2 = (Y-Yx)^2.
7. Необходимо заполнить в таблице 1 столбцы (Y-Y_сред)^2, (Y_предск-Y_сред)^2. Чтобы вычислить суммы квадратов отклонений (TSS, ESS, RSS), необходимо в расчетной таблице 1 применить функцию СУММ(…) к столбцам (Y-Y_сред)^2, (Y_предск-Y_сред)^2, (Y-Yx)^2.
8. Чтобы рассчитать значения множественных коэффициентов детерминации и корреляции, скорректированного коэффициента детерминации, необходимо «вручную» ниже расчетной таблицы 1 использовать ссылки на необходимые ячейки согласно формулам:



Вывод 3: Коэффициент детерминации R2 показывает, что данная множественная регрессия объясняет 92% вариации объема продаж. Индекс множественной корреляции отражает наличие тесного совместного влияния цены и расходов на рекламу на регрессант - объем продаж. Скорректированный коэффициент детерминации R2adj всегда немного меньше обычного коэффициента детерминации, здесь он показывает, что с учетом «штрафа» за включение в модель дополнительного регрессора, данная множественная регрессия объясняет 91% вариации объема продаж.
Комментарий: Отметим, что регрессии с разными зависимыми переменными ни по R2, ни по R2adj сравнивать нельзя (из-за разных выборочных дисперсий зависимых показателей). Коэффициент R2adj является одним из показателей, с помощью которых можно сравнивать регрессии с одинаковыми зависимыми переменными и разным набором независимых. Обычно лучшей считается та модель, в которой R2adj наибольший. Однако при этом не следует увлекаться увеличением этого показателя в ущерб возможности дать модели осмысленную экономическую интерпретацию.
9. Чтобы рассчитать значения средних коэффициентов эластичности для каждого регрессора, необходимо «вручную» ниже расчетной таблицы 1 использовать ссылки на необходимые ячейки согласно формулам:

Вывод 4: Увеличение цены на 1 % приводит к снижению объема продаж на 0,53%, а увеличение расходов на рекламу на 1% приводит к увеличению объема продаж на 2,16%. Следовательно, расходы на рекламу сильнее, чем цена, влияют на изменение объема продаж.
10. Чтобы оценить нашу регрессию в Excel с помощью инструмента Регрессия надстройки Пакет анализа в главном меню программы Excel на вкладке Данные (в верхней строке) выберем опцию Анализ данных, а в списке Инструментов анализа выберем инструмент Регрессия. В качестве регрессанта выберем переменную Y – объем продаж, а в качестве регрессоров укажем диапазон переменных X1 – цена, Х2 – расходы на рекламу, укажем «галочку» в опции Метки, чтобы трактовать первую строку данных как названия переменных (рис.6).

Рис. 6. Окно параметров регрессии с введенными значениями в Excel
Далее, нажав на кнопку Ок, получаем результаты (рис.7).

Рис.7. Вывод результатов оценивания регрессии в Excel
Более подробно рассмотрим результаты, переведя их в обычные таблицы.
| Регрессионная статистика | |||||||
| Множественный R | 0,959454 | ||||||
| R-квадрат | 0,920551 | ||||||
| Нормированный R-квадрат | 0,90731 | ||||||
| Стандартная ошибка | 3,798873 | ||||||
| Наблюдения | |||||||
| Дисперсионный анализ | |||||||
| df | SS | MS | F | Значимость F | |||
| Регрессия | 2006,556 | 1003,278 | 69,52034 | 2,51E-07 | |||
| Остаток | 173,1772 | 14,43143 | |||||
| Итого | 2179,733 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | ||
| Y-пересечение | -20,797 | 7,975413 | -2,60764 | 0,022901 | -38,174 | -3,42009 | |
| X1 | -0,54132 | 0,073548 | -7,36014 | 8,73E-06 | -0,70157 | -0,38107 | |
| Х2 | 1,503558 | 0,16005 | 9,394324 | 7E-07 | 1,15484 | 1,852277 | |
В подтаблице «Регрессионная статистика» Множественный R – это индекс корреляции между регрессантом и регрессорами. Строкой ниже Excel выдает значение R2, равное 0,92. Чуть ниже можно увидеть значение нормированного (или, по-другому, скорректированного (adjusted) R2. Еще ниже указано значение Стандартной ошибки регрессии (MSE) – квадратного корня из остаточной дисперсии (пересечение столбца MS и строки Остаток по второй подтаблице), равное 3,799. В конце подтаблицы дано значение количества Наблюдений, равное 15.
В подтаблице «Дисперсионный анализ» во втором столбце df даны числа степеней свободы, в третьем столбце даны значения ESS, RSS и TSS (соответственно 2006,556;173,1772; 2179,733). Четвертый столбик содержит отношения ESS/dfESS, RSS/dfRSS соответственно. F – это значение F-статистики теста Фишера для проверки адекватности регрессии. В самом правом столбце дано значение p-value для этой статистики.
Комментарий: В модели парной регрессии, для того чтобы определить, есть ли линейная зависимость между переменными X и Y, достаточно проверить значимость коэффициента регрессии при переменной Х по тесту Стьюдента. Однако в случае множественной регрессии дело обстоит сложнее. Здесь возникает вопрос о совокупном влиянии нескольких переменных. Эта задача не сводится к проверке значимости каждого из коэффициентов регрессии. Каждый из коэффициентов регрессии в отдельности может быть незначим, но тем не менее включенные в уравнение регрессии регрессоры (факторы) в совокупности могут оказывать значимое влияние на зависимую переменную – регрессант. Для модели  проверка гипотезы
проверка гипотезы

при альтернативной гипотезе:
 ,
,
то есть когда хотя бы один коэффициент отличен от нуля, называется проверкой гипотезы об адекватности регрессии. Гипотеза об адекватности проверяется всеми статистическими пакетами. Выдается соответствующее значение F-статистики (тест Фишера) и p-value для этой F-статистики.
 Повторимся, что значение p-value позволяет провести тест (в данном случае тест Фишера), не пользуясь критическими значениями статистики. Если p-value для статистики меньше, чем α =0,1, то нулевая гипотеза отвергается с вероятностью 90%. Если p-value для статистики меньше, чем α =0,05, то нулевая гипотеза отвергается с вероятностью 95%. Если p-value для статистики меньше, чем α =0,01, то нулевая гипотеза отвергается с вероятностью 99%.
Повторимся, что значение p-value позволяет провести тест (в данном случае тест Фишера), не пользуясь критическими значениями статистики. Если p-value для статистики меньше, чем α =0,1, то нулевая гипотеза отвергается с вероятностью 90%. Если p-value для статистики меньше, чем α =0,05, то нулевая гипотеза отвергается с вероятностью 95%. Если p-value для статистики меньше, чем α =0,01, то нулевая гипотеза отвергается с вероятностью 99%.
Вывод 5: В нашем случае p-value для статистики Фишера составило 2,51Е-07, что меньше, чем α =0,01. Это означает, что с вероятностью 99% отвергается нулевая гипотеза о неадекватности уравнения регрессии. Согласно тесту Фишера регрессия адекватна, выбранный набор независимых переменных (X1 – цена, Х2 – расходы на рекламу) оказывает линейное влияние на зависимую переменную Y – объем продаж.
В нижней подтаблице в столбце «Коэффициенты» содержатся коэффициенты регрессии для регрессоров Х1 и Х2, равные -0,541 и 1,503 соответственно, а также свободный коэффициент, равный -20,797 на пересечении со строкой «Y-пересечение». В третьем столбце указаны стандартные ошибки коэффициентов, далее – значение t-статистики теста Стьюдента, затем дано значение p-value для этой статистики. Гипотезы о значимости коэффициента регрессии (тест Стьюдента) формулируются и проверяются для каждого коэффициента регрессии в отдельности аналогично случаю парной регрессии. Единственное отличие состоит в числе степеней свободы:

t-статистика и p-value для t -статистики Стьюдента для проверки гипотезы о значимости каждого из коэффициентов множественной регрессии выдаются статистическими пакетами.
Вывод 6: В нашем случае p-value для статистики Стьюдента для коэффициента регрессии при Х1 составило 8,73E-06, что меньше, чем α =0,01. Это означает, что коэффициент регрессии β1 является значимым с вероятностью 99%, между переменными X1 (цена) и Y (объем продаж) существует значимая линейная связь. Также p-value для статистики Стьюдента для коэффициента регрессии при Х2 составило 7E-07, что меньше, чем α =0,01. Это означает, что коэффициент регрессии β2 является значимым, между переменными X2 (расходы на рекламу) и Y (объем продаж) существует значимая линейная связь. p-value для статистики Стьюдента для свободного коэффициента составило 0,023, что меньше, чем α =0,05. Это означает, что свободный коэффициент α является значимым с вероятностью 95%. В двух самых правых столбцах даны доверительные границы коэффициентов. В нашем случае, границы значение «ноль» не включают, что еще раз подтверждает статистическую значимость (отличие от нуля) коэффициентов уравнения регрессии.