ЛЕКЦИЯ 6. Даталогические модели данных
Модель данных – фиксированная система понятий и правил для представления структуры данных, состояния и динамики проблемной области в базах данных. Как правило, задается языком определения данных и языком манипулирования данными. Примерами модели данных, получившими широкое распространение, являются модели данных сетевая, иерархическая, реляционная и др.
Модель данных состоит из трех компонент:
1. Структура данных для представления точки зрения пользователя на базу данных.
2. Допустимые операции, выполняемые на структуре данных. Они составляют основу языка данных рассматриваемой модели данных. Одной лишь хорошей структуры данных недостаточно. Необходимо иметь возможность работать с этой структурой при помощи различных операций языка определения данных и языка манипулирования данными. Богатая структура данных ничего не стоит, если нет возможности оперировать ее содержимым.
3. Ограничения для контроля целостности. Модель.данных должна быть обеспечена средствами, позволяющими сохранять ее целостность и защищать ее.
Схема – это средство, с помощью которого определяется модель данных приложения. В действительности схема содержит не только модель данных: в ней присутствует также некоторая семантическая информация, относящаяся к конкретному приложению.
В модели данных можно определить, например, что база данных будет хранить информацию об организациях и служащих. Однако, тот факт, что данный служащий не может работать более чем в одной организации, отражает семантику приложения. Это семантическое ограничение должно выполняться для каждого отдельного экземпляра записи базы данных об этом служащем.
Поддержка ограничений заданной модели данных в базе данных также является частью функций СУБД по обеспечению защиты и целостности.
Прежде, чем перейти к детальному и последовательному изучению реляционных систем БД, целесообразно ознакомиться с ранними СУБД.
В этом есть смысл по трем причинам:
1. эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников;
2. внутренняя организация реляционных систем во многом основана на использовании методов ранних систем;
3. некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Иерархическая модель
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи [11].
Пример типа дерева (схемы иерархической БД) представлен на рис. 7.1.

Рис. 7.1. Пример схемы иерархической БД
На рис. 7.1. ОТДЕЛ является предком для НАЧАЛЬНИК и СОТРУДНИКИ, а НАЧАЛЬНИК и СОТРУДНИКИ - потомки ОТДЕЛ. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (рис. 7.2, показан один экземпляр дерева).

Рис. 7.2. Реализация иерархической БД
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие.
§ Найти указанное дерево БД (например, отдел 42).
§ Перейти от одного дерева к другому.
§ Перейти от одной записи к другой внутри дерева (например, от отдела – к первому сотруднику).
§ Перейти от одной записи к другой в порядке обхода иерархии.
§ Вставить новую запись в указанную позицию.
§ Удалить текущую запись.
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается.
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть следующая иерархия (рис. 7.3).

Рис. 7.3. Пример схемы иерархической БД
Экземпляр дерева базы данных не обязательно должен содержать все свои сегменты. При необходимости можно добавлять или удалять экземпляры типов записей в соответствии с требованиями приложения.
Иерархическая структура реализует отношение ОДИН-КО-МНОГИМ между исходным и порожденным типами записей. Это отображение полностью функционально, т.к. дерево не может содержать порожденный узел без исходного узла (за исключением «корня»). Следовательно, отображения ОДИН-К-ОДНОМУ и ОДИН-КО-МНОГИМ могут непосредственно представляться иерархическими структурами. Однако для представления отображения МНОГИЕ-КО-МНОГИМ необходимо дублирование деревьев, а значит, реализация сложных связей требует больших затрат памяти.
Другой проблемой иерархий является невозможность хранения в БД порожденного узла без соответствующего исходного, т.е. в этом случае необходимо ввести пустой исходный узел. Соответственно удаление данного исходного узла влечет удаление всех порожденных узлов (поддеревьев), связанных в ним. Эти ограничения создают проблемы применения иерархической модели для некоторых приложений.
Сетевая модель
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. С точки зрения теории графов сетевой модели соответствует произвольный граф (возможно имеющий циклы и петли). В узлах графа помещаются типы записей, а ребра интерпретируются как связи между типами записей.
Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи [11].
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка Р и типом записи потомка С должны выполняться следующие два условия:
§ каждый экземпляр типа Р является предком только в одном экземпляре L;
§ каждый экземпляр С является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации [11].
А. Тип записи потомка в одном типе связи L 1 может быть типом записи предка в другом типе связи L 2 (как в иерархии).
B. Данный тип записи Р может быть типом записи предка в любом числе типов связи.
C. Дляный тип записи Р может быть типом записи потомка в любом числе типов связи.
D. Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L 1 и L 2 - два типа связи с одним и тем же типом записи предка Р и одним и тем же типом записи потомка С, то правила, по которым образуется родство, в разных связях могут различаться.
E. Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком - в другой.
F. Предок и потомок могут быть одного типа записи.
Простой пример сетевой схемы БД приведен на рис. 7.4.
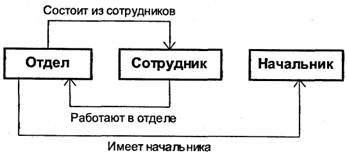
Рис. 7.4. Пример схемы сетевой БД
Примерный набор операций при использовании сетевой модели может быть следующим [11].
§ Найти конкретную запись в наборе однотипных записей (инженера Петрова).
§ Перейти от предка к первому потомку по некою рой связи (к первому сотруднику отдела 42).
§ Перейти к следующему потомку в некоторой связи (от Петрова к Иванову).
§ Перейти от потомка к предку по некоторой связи (найти отдел Петрова).
§ Создать новую запись.
§ Уничтожить запись.
§ Модифицировать запись.
§ Включить в связь.
§ Исключить из связи.
§ Переставить в другую связь и т.д.
Реляционная модель
В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных даталогических моделей данных, т.е. возможности использования привычных и естественных способов представления данных. Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Э. Кодда (Codd E.F., A Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), где, вероятно, впервые был применен термин «реляционная модель данных».
Будучи математиком по образованию Э. Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.) [4, 8, 10, 14].
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество атомарных значений одного и того же типа. Так, на рис. 7.5 домен пунктов отправления (назначения) – множество названий населенных пунктов, а домен номеров рейса – множество целых положительных чисел.
Смысл доменов состоит в следующем. Если значения двух атрибутов берутся из одного и того же домена, то, вероятно, имеют смысл сравнения, использующие эти два атрибута (например, для организации транзитного рейса можно дать запрос «Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву»). Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета?
Отношение на доменах D 1, D 2,..., Dn (не обязательно, чтобы все они были различны) состоит из заголовка и тела. На рис. 7.5 приведен пример отношения для расписания движения самолетов.
Заголовок состоит из такого фиксированного множества атрибутов A 1, A 2,..., An, что существует взаимно однозначное соответствие между этими атрибутами Аi и определяющими их доменами Di (i = l, 2,..., n).
Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Ai:Vi), (i = 1, 2,..., n), по одной такой паре для каждого атрибута А. в заголовке. Для любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Аi.

Рис. 7.5. Отношение в реляционной модели
Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным,..., а степени п – n -арным.
Кардинальное число или мощность отношения – это число его кортежей. Кардинальное число отношения изменяется во времени в отличие от его степени.
Изменение кардинального числа отношения связано с изменением состояния отношения.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R – отношение с атрибутами А 1, A 2 ,..., Ап. Говорят, что множество атрибутов К = (Аi, Аj,..., Аk) отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два независимых от времени условия.
1. Уникальность: в произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Аi, Аj,..., Ak.
2. Минимальность: ни один из атрибутов Аi, Аj,..., Ak не может быть исключен из К без нарушения уникальности.
Каждое отношение обладает хотя бы одним возможным ключом, поскольку, по меньшей мере, комбинация всех его атрибутов удовлетворяет условию уникальности. Один из возможных ключей (выбранный произвольным образом) принимается за его первичный ключ. Остальные возможные ключи, если они есть, называются альтернативными ключами.
Вышеупомянутые и некоторые другие математические понятия явились теоретической базой для создания реляционных СУБД, разработки соответствующих языковых средств и программных систем, обеспечивающих их высокую производительность, и создания основ теории проектирования баз данных. Однако для массового пользователя реляционных СУБД можно использовать неформальные эквиваленты этих понятий:
Отношение – Таблица (иногда Файл),
Кортеж – Строка (иногда Запись),
Атрибут - Столбец, Поле.
При этом принимается, что «запись» означает «экземпляр записи», а «поле» означает «имя и тип поля».
Математическое определение реляционной модели.
Отношение рассматривается как подмножество декартова произведения доменов.
Декартовым произведение доменов D 1, D 2,..., Dk
 (7.1)
(7.1)
где D 1 ={ d 1.1, d 1.2, …, d 1. i 1, …, d1. n 1}, D 2 = { d 2.1, d 2.2, …, d 2. i 2, …, d 2. n 2},…, Dk = { dk .1, dk. 2,..., dk.ik,..., dk.nk }, называется множество всех кортежей длины k, т.е. состоящих из k элементов – по одному из каждого домена Di.
Пример 1. Если D 1 = { A, 2}, D 2 = { B, С }, D 3 = {4, 5, D },то k = 3 и соответственно декартово произведение:
 (7.2)
(7.2)
Декартово произведение позволяет получить все возможные комбинации элементов исходных множеств – элементов рассматриваемых доменов.
Отношением R на множествах D 1, D 2 ,..., Dk называется подмножество декартова произведения D = = D 1 ´ D 2 ´... ´ Dk. Отношение R, определенное на множествах D 1, D 2,..., Dk (причем не обязательно, чтобы эти множества были различными), есть некоторое множество кортежей арности k: (d 1. i 1, d 2. i 2,..., di.ik), таких, что d 1. i 1принадлежит D 1, d 2. i 2 - D 2и т.д.:
 (7.3)
(7.3)
Элементами отношения являются кортежи. Арность кортежа определяет арность отношения. Поскольку отношение есть множество, то в нем не должны встречаться одинаковые кортежи и порядок кортежей в отношении несуществен.
Отношение может использоваться двояко:
1) для представления набора объектов;
2) для представления связей между наборами объектов.
Для представления набора объектов атрибуты интерпретируются столбцами отношения. Множество допустимых значений атрибута интерпретируется соответствующим доменом. Каждый кортеж отношения выполняет роль описания отдельного объекта из набора. Отношение выполняет роль описания всего набора объектов.
Отношение также используется для представления связей между наборами объектов. В этом случае кортеж в отношении R связь между объектами. Чтобы реализовать такую ситуацию, каждому столбцу отношения ставится в соответствие ключевой атрибут соответствующего набора объектов.
Список имен атрибутов отношения называется схемой отношения. Если отношение называется R и его схема имеет атрибуты с именами А 1, А 2 ,..., Ak, то схема отношения
 (7.4)
(7.4)
Реляционная база данных – это набор экземпляров конечных отношений. Схему реляционной БД можно представить в виде совокупности схем отношений
 (7.5)
(7.5)
Другими словами – реляционная база данных – это совокупность отношений, содержащих всю информацию, которая должна храниться в БД. Однако пользователи могут воспринимать такую базу данных как совокупность таблиц. Так на рис. 7.6 показаны таблицы базы данных, построенные по инфологической модели базы данных «Питание».
1. Каждая таблица состоит из однотипных строк и имеет уникальное имя.
2. Строки имеют фиксированное число полей (столбцов) и значений (множественные поля и повторяющиеся группы недопустимы). Иначе говоря, в каждой позиции таблицы на пересечении строки и столбца всегда имеется в точности одно атомарное значение или ничего.
3. Строки таблицы обязательно отличаются друг от друга хотя бы единственным значением, что позволяет однозначно идентифицировать любую строку такой таблицы.
4. Столбцам таблицы однозначно присваиваются имена, и в каждом из них размещаются однородные значения данных (даты, фамилии, целые числа или денежные суммы).
5. Полное информационное содержание базы данных представляется в виде явных значений данных, и такой метод представления является единственным. В частности, не существует каких-либо специальных «связей» или указателей, соединяющих одну таблицу с другой. Так, связи между строкой с БЛ = 2 таблицы «Блюда» на рис. 7.6 и строкой с ПР = 7 таблицы продукты (для приготовления Харчо нужен Рис), представляется не с помощью указателей, а благодаря существованию в таблице «Состав» строки, в которой номер блюда равен 2, а номер продукта – 7.
6. При выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию. Этому способствует наличие имен таблиц и их столбцов, а также возможность выделения любой их строки или любого набора строк с указанными признаками.

Рис. 7.6. База данных «Питание»
Достоинства и недостатки даталогических моделей
Сначала остановимся коротко на ранних (дореляционных) СУБД. Ограничимся рассмотрением только общих особенностей ранних систем, а именно, систем, основанных на иерархических и сетевых моделях.
1. Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
2. Все ранние системы не основывались на каких-либо абстрактных моделях. Как упоминалось, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
3. В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
4. Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
5. После появления реляционных систем большинство ранних систем было оснащено «реляционными» интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме (на низком физическом уровне).
Обобщая перечисленные особенности, можно сформулировать достоинства и недостатки ранних систем.
Достоинства:
§ развитые средства управления данными во внешней памяти на низком уровне;
§ возможность построения вручную эффективных прикладных программ;
§ возможность экономии памяти.
Недостатки:
§ сложность практического использования;
§ необходимость знания физической организации данных;
§ жесткая зависимость прикладных систем от физической организации данных;
§ логика перегружена деталями организации доступа к БД.
По сравнению с ранними моделями, реляционный подход обладает следующими особенностями.
Достоинства:
§ наличие относительно небольшого набора абстракций;
§ наличие простого, но мощного математического аппарата (в основе реляционного подхода – теория множеств);
§ возможность ненавигационного манипулирования данными без знания их конкретной физической организации.
Недостатки:
§ ограниченность использования в нетрадиционных предметных областях;
§ относительно неполная адекватность отражения семантики предметной области.
Самая сильная сторона реляционного подхода – математический аппарат для выполнения операций над отношениями реляционной модели.
Наличие простого, но мощного математического аппарата сыграло решающую роль в повсеместном переходе разработчиков СУБД на реляционную модель.