Процедура распознования
Выделим наиболее важные шаги в процедуре распознования:
1. Восприятие образа. На этом этапе производят получение значений характеристических свойств объекта (измерения линейных замеров, фотографирование, оцифровка звука).
2. Предварительная обработка (удаление шумов, представление изображения в черно-белом варианте, обрезание ненужных частей изображения).
3. Выделение характеристик (индексация). На этом этапе измеряются характеристический свойства объекта (измеряем длину рыбы и ее цвет).
4. Классификация (принятие решения).
Разработка системы распознавания
1. Достать тренировочную коллекцию Тренировочная коллекция - коллекция объектов для которых заведомо известны их образы. Например коллекция аудио записей для каждого звука, или коллекция изображений каждой буквы латинского алфавита.
2. Выбрать модель представления объектов
3. Выбрать значимые характеристики Один из самых важных этапов разработки системы распознавания. Например, если в случае идентификации рыбы окунь/лосось в качестве характеристики выбрать только длину рыбы, то никакое классифицируещее правило не сможет точно определить тип рыбы, посколько весьма вероятно встретить лосося и окуня одинаковой длины.
4. Разработать классифицирующее правило
Классифицирующее правило - правило, которое по значениям характеристических свойств объекта отнесет его к одному из образов.
5. Обучение алгоритма. На этом этапе алгоритм "собирает опыт"на основе респознавания тренировочной коллекции. Для того, чтобы правильно выставить коэффициенты (параметры) алгоритма его прогоняют на тренировочной коллекции контролируя результат работы алгоритма.
6. Проверить качество. Вернуться к шагу 2 (3, 4)... Если частота ошибок алгоритма не устраивает решаемую задачу, то необходимо вернуться к п. 2 (3, 4). Интуитивно понятно, что увеличение количества характеристических свойств, увеличение тренировочной коллекции улучшают качество работы алгоритма.
7. Оптимизация алгоритма После того, как качество работы алгоритма подходит под условие рассматриваемой задачи, иногда приходится произвести его оптимизацию. Изначальный алгоритм может быть слишком долгим или ресурсоемким. Ускорить алгоритм распознавания можно уменьшив количество характеристических свойств объекта, выбрав другие характеристические свойства, используя другое классифицирущее правило.
Методы распознавания Выделяют 4 группы методов разпознавания:
1. Сравнение с образцом.Применяем геометрическую нормализацию и считаем расстояние до прототипа. Наиболее наглядно применение этого метода в распознавании теста. Задача. У нас есть изображение сканированного символа и коллекция изображений образцов (всех букв алфавита), мы хотим определить, какой букве алфавита соответствует отсканированое изображение. Решение. Смасштабируем изображение символа до размеров образцов и выберем тот, до которого растояние минимально.
2. Статистические методы.Строим распределение для каждого класса и классифицируем по правилу Байеса. Распределение можно построить используя тренировочную коллекцию.
3. Нейронные сети.Выбираем вид сети и настраиваем коэффициенты. На рисунке представлена простейшая нейронная сеть. На вход нейронной сети подается распознаваемый объект. Слева на рисунке расположена группа рецепторов, каждый из которых отвечает за прием своего характеристического свойства распознаваемых объектов. Справа на рисунке расположенна группа эффекторов, каждый из которых соответствуею 3 одному из образов. Выбирается тот из эффекторов, значение в котором максимально. Настройка коэффицентов является фазой обучения алгоритма. На этом этапе мы настраиваетм коэффициенты таким образом, чтобы алгоритм правильно работал на образцах. Чем больше образцов, тем больше вероятность того, что алгоритм примет верное решение на остальных данных.
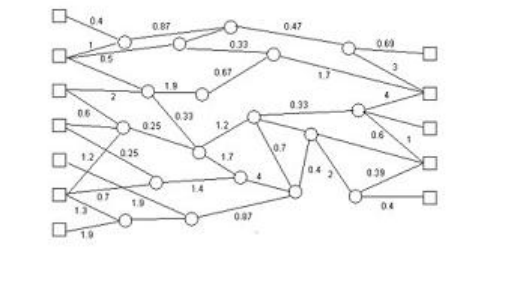
4. Структурные и синтаксические методы.Разбираем объект на элементы. Строим правило, в зависимости от вхождения/невхождения отдельных элементов и их последовательностей
Теоре́маБа́йеса (или фо́рмулаБа́йеса) — одна из основных теорем элементарной теории вероятностей, которая позволяет определить вероятность какого-либо события при условии, что произошло другое статистически взаимозависимое с ним событие. Другими словами, по формуле Байеса можно более точно пересчитать вероятность, взяв в расчёт как ранее известную информацию, так и данные новых наблюдений.
Формула Байеса:
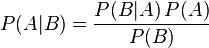 ,
,
где
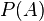 — априорная вероятность гипотезы A;
— априорная вероятность гипотезы A;
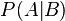 — вероятность гипотезы A при наступлении события B (апостериорная вероятность);
— вероятность гипотезы A при наступлении события B (апостериорная вероятность);
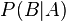 — вероятность наступления события B при истинности гипотезы A;
— вероятность наступления события B при истинности гипотезы A;
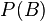 — полная вероятность наступления события B.
— полная вероятность наступления события B.
Формула Байеса позволяет «переставить причину и следствие»: по известному факту события вычислить вероятность того, что оно было вызвано данной причиной.
События, отражающие действие «причин», в данном случае называют гипотезами, так как они — предполагаемые события, повлёкшие данное. Безусловную вероятность справедливости гипотезы называют априорной (насколько вероятна причина вообще), а условную — с учётом факта произошедшего события — апостериорной (насколько вероятна причина оказалась с учётом данных о событии).
Пример 1
Событие 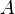 — в баке нет бензина, событие
— в баке нет бензина, событие  — машина не заводится. Заметим, что вероятность того, что машина не заведётся, если в баке нет бензина, равняется единице. Тем самым, вероятность того, что в баке нет бензина, равна произведению вероятности того, что машина не заводится, на вероятность того, что причиной события стало именно отсутствие бензина (событие ), а не, к примеру, разряженный аккумулятор.
— машина не заводится. Заметим, что вероятность того, что машина не заведётся, если в баке нет бензина, равняется единице. Тем самым, вероятность того, что в баке нет бензина, равна произведению вероятности того, что машина не заводится, на вероятность того, что причиной события стало именно отсутствие бензина (событие ), а не, к примеру, разряженный аккумулятор.