Объекты нечисловой природы появляются не только на "входе" статистической процедуры, но и в процессе обработки данных, и на "выходе" в качестве итога статистического анализа.
Рассмотрим простейшую прикладную постановку задачи регрессии. Данные имеют вид  . Цель состоит в том, чтобы с достаточной точностью описать
. Цель состоит в том, чтобы с достаточной точностью описать  как полином от
как полином от 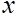 , т.е. модель имеет вид
, т.е. модель имеет вид
 , (5)
, (5)
где  - неизвестная степень полинома;
- неизвестная степень полинома;  - неизвестные коэффициенты многочлена;
- неизвестные коэффициенты многочлена;  ,
,  - погрешности, которые для простоты примем независимыми и имеющими одно и то же нормальное распределение. Распространенная процедура такова [102]: сначала пытаются применить модель (5) для линейной функции ( = 1), при неудаче переходят к многочлену второго порядка ( = 2), если снова неудача, то берут модель (5) с = 3 и т.д. (адекватность модели проверяют по F-критерию Фишера).
- погрешности, которые для простоты примем независимыми и имеющими одно и то же нормальное распределение. Распространенная процедура такова [102]: сначала пытаются применить модель (5) для линейной функции ( = 1), при неудаче переходят к многочлену второго порядка ( = 2), если снова неудача, то берут модель (5) с = 3 и т.д. (адекватность модели проверяют по F-критерию Фишера).
Обсудим свойства этой процедуры в терминах математической статистики. Если степень полинома задана ( =  ), то его коэффициенты оценивают методом наименьших квадратов, свойства этих оценок хорошо известны (см., например, [62, гл.26}). Однако в описанной выше реальной постановке тоже является неизвестным параметром и подлежит оценке. Таким образом, требуется оценить объект ,
), то его коэффициенты оценивают методом наименьших квадратов, свойства этих оценок хорошо известны (см., например, [62, гл.26}). Однако в описанной выше реальной постановке тоже является неизвестным параметром и подлежит оценке. Таким образом, требуется оценить объект ,  ., множество значений которого можно обозначить
., множество значений которого можно обозначить  Это - объект нечисловой природы, обычные методы оценивания его неприменимы, так как - дискретный параметр. В рассматриваемой постановке методы оценивания носят в основном эвристический характер {103, гл.12}. Свойства описанной выше распространенной процедуры рассмотрены в работе {104}; в которой показано, что m при этом оценивается несостоятельно (см. также.{14,18}).
Это - объект нечисловой природы, обычные методы оценивания его неприменимы, так как - дискретный параметр. В рассматриваемой постановке методы оценивания носят в основном эвристический характер {103, гл.12}. Свойства описанной выше распространенной процедуры рассмотрены в работе {104}; в которой показано, что m при этом оценивается несостоятельно (см. также.{14,18}).
В более общем случае линейной регрессии данные имеют вид  , где
, где  - вектор предикторов (объясняющих переменных), а модель
- вектор предикторов (объясняющих переменных), а модель
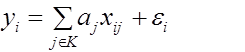 (6)
(6)
( - некоторое подмножество множества
- некоторое подмножество множества  ;
;  - те же, что и в модели (5);
- те же, что и в модели (5);  - неизвестные коэффициенты при предикторах с номерами из {103]). Модель (5) сводится к модели (6), если
- неизвестные коэффициенты при предикторах с номерами из {103]). Модель (5) сводится к модели (6), если
.  ,
,

В модели (5) есть естественный порядок ввода предикторов в рассмотрение - в соответствии с возрастанием степени, а в модели (6) естественного порядка нет, поэтому здесь стоит произвольное подмножество множества предикторов. Есть только частичный порядок - чем мощность подмножества меньше, тем лучше. Модель (6) особенно актуальна в задачах управления качеством продукции, в медицине и социологии, когда из большого числа факторов, предположительно влияющих на изучаемую переменную, надо отобрать по возможности наименьшее число значимых факторов и с их помощью сконструировать прогнозирующую формулу (6).
Задача оценивания модели (6) разбивается на две последовательные задачи: оценивание множества - подмножества множества всех предикторов, а затем - неизвестных параметров . Методы решения второй задачи хорошо известны и изучены. Гораздо хуже обстоит дело с оцениванием объекта нечисловой природы . Существующие методы [103] - в основном эвристические, они зачастую не являются даже состоятельными. Понятие состоятельности в данном случае требует определения. Пусть  - истинное подмножество предикторов, т.е. подмножество, для которого справедлива модель (6), а подмножество предикторов - его оценка. Оценка
- истинное подмножество предикторов, т.е. подмножество, для которого справедлива модель (6), а подмножество предикторов - его оценка. Оценка  является состоятельной, если
является состоятельной, если
 ,
,
где  - знак симметрической разности множеств;
- знак симметрической разности множеств;  означает число элементов в множестве , а предел понимается в смысле сходимости по вероятности.
означает число элементов в множестве , а предел понимается в смысле сходимости по вероятности.
Задача оценивания в моделях регрессии, таким образом, разбивается на две - оценивание структуры модели и параметров при заданной структуре. в модели (5) структура описывается неотрицательным целым числом , в модели (6) - множеством . Структура - объект нечисловой природы. Задача ее оценивания сложна, в то время как задача оценивания численных параметров при заданной структуре хорошо изучена, разработаны эффективные (в смысле математической статистики) методы.
Такова же ситуацию в факторном анализе (включая метод главных компонент) и многомерном шкалировании [38]. Ряд других примеров можно найти в списке оптимизационных постановок основных проблем прикладного многомерного статистического анализа [91].
Перейдем к объектам нечисловой природы на "выходе" статистической процедуры. Примеры многочисленны. Разбиения - итог работы многих алгоритмов классификации, в частности алгоритм кластер-анализа. Ранжировки - результат упорядочения профессий по привлекательности, автоматизированной обработки мнений экспертов - членов комиссии по подведению итогов конкурса научных работ [105] или итогов конкурса по решению задач в Вечерней математической школе [106]. (В двух последних случаях используются ранжировки со связями; так, в одну группу, наиболее многочисленную, попадают работы, не получившие наград.) Из всех объектов нечисловой природы, видимо, наиболее часты на "выходе" дихотомические данные - принять или не принять гипотезу, в частности принять или забраковать партию продукции [58]. Дихотомические данные используются научными исследованиями [46]. Результатом статистической обработка данных может быть множество, например зона наибольшего поражения [107], или последовательность множеств, например "среднемерное" описание распространения пожара [68]. Нечетким множеством Э.Борель [55] предлагал описывать представление людей о числе зерен, образующем "кучу". С помощью нечетких множеств формализуются значения лингвистических переменных, выступающих как итоговая оценка качества систем автоматизированного проектирования, сельскохозяйственных машин [108], бытовых газовых плит [109], надежности программного обеспечения [110, 111] или систем управления. Можно констатировать, что все виды объектов нечисловой природы могут появляться " на выходе" статистического исследования.
ЛИТЕРАТУРА
1. Орлов А.И. / Вестник статистики. 1986, № 8. С.52 - 56
2. Горский В.Г. - В сб.: Международная школа повышения квалификации "Инженерно-химическая наука для передовых технологий". Труды третьей сессии, 26-30 мая 1997. Казань, Россия / Под ред. В.А.Махлина. - М.: Научно-Исследовательский Физико-Химический Институт им.Карпова, 1997. С.261-293.
3. Гуда А.Н. Модели, методы и средства анализа данных в затрудненных условиях. Автореф. дисс. докт. технич. наук. - Таганрог: Таганрогский государственный радиотехнический университет, 1997. 38 с.
4. Налимов В.В. Применение математической статистики при анализе вещества. - М.: Физматгиз, 1960. - 430 с.
5. Налимов В.В., Чернова Н.Л. Статистические методы планирования экстремальных экспериментов. - М.: Физматгиз, 1965. - 340 с.
6. Налимов В.В. Канатоходец. Воспоминания. - М.: Издательская группа "Прогресс", 1994. - 456 с.
7. Гнеденко Б.В., Орлов А.И. / Заводская лаборатория. 1988. Т.54. № 1. С.1-4.
8. Горский В.Г. / Заводская лаборатория. 1992. Т.58. № 1. С.63-64.
9. Орлов А.И. / Заводская лаборатория. 1992. Т.58. № 1. С.67-74.