Объединение
Внутренними объединениями. Такие объединения связывают строки одной таблицы со строками другой таблицы (а может еще и третьей таблицы). Но бывают ситуации, когда необходимо, чтобы в результат были включены строки, не имеющие связанных.
Внешним объединением, позволяющим выводить все строки одной таблицы и имеющиеся связанные с ними строки из другой таблицы.
Если нам надо получить данные из двух таблиц, то Запросы, которые позволяют это сделать, в SQL называются Объединениями.
Синтаксис самого простого объединения следующий:
SELECT имена_столбцов_таблицы_1, имена_столбцов_таблицы_2 FROM имя_таблицы_1, имя_таблицы_2;
Такое объединение научно называется декартовым произведением, когда каждой строке первой таблицы ставится в соответствие каждая строка второй таблицы.
Чтобы результирующая таблица выглядела так, как мы хотели, необходимо указать условие объединения. Мы связываем наши таблицы по идентификатору автора, это и будет нашим условием. Т.е. мы укажем в запросе, что необходимо выводить только те строки, в которых значения поля id_author таблицы topics совпадают со значениями поля id_user таблицы users:
Т.е. мы в запросе сделали следующее условие: если в обеих таблицах есть одинаковые идентификаторы, то строки с этим идентификатором необходимо объединить в одну результирующую строку.
Обратите внимание на две вещи:
- Если в одной из объединяемых таблиц есть строка с идентификатором, которого нет в другой объединяемой таблице, то в результирующей таблице строки с таким идентификатором не будет. В нашем примере есть пользователь Oleg (id=5), но он не создавал тем, поэтому в результате запроса его нет.
- При указании условия название столбца пишется после названия таблицы, в которой этот столбец находится (через точку). Это сделано во избежание путаницы, ведь столбцы в разных таблицах могут иметь одинаковые названия, и MySQL может не понять, о каких конкретно столбцах идет речь.
Внешнее объединение
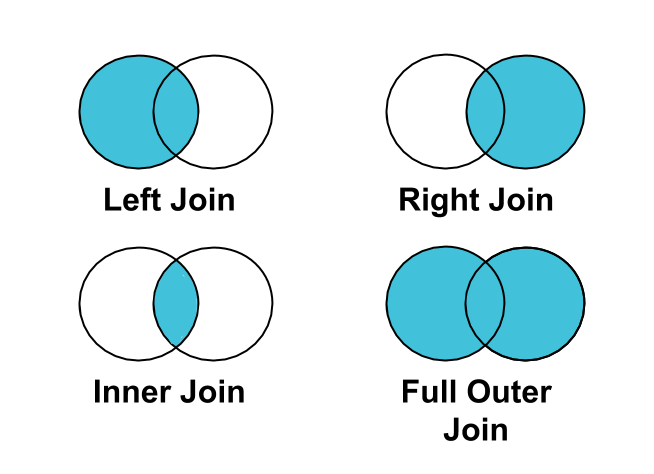
Inner Join
Если рассмотреть описание механизма работы этой конструкции, то получим следующую картину. Логика оператора в целом построена на возможности пересечения и выборки только тех данных, которые есть в каждой из входящих в запрос таблиц. Если рассмотреть такую работу с точки зрения графической интерпретации, то получим структуру оператора SQL Inner Join, пример которой можно показать с помощью следующей схемы:
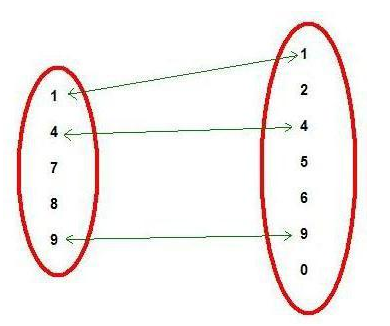
К примеру, мы имеем две таблицы, схема которых показана на рисунке. Они в свою очередь, имеют разное количество записей. В каждой из таблиц есть поля, которые связаны между собой. Если попытаться пояснить работу оператора исходя из рисунка, то возвращаемый результат будет в виде набора записей из двух таблиц, где номера связанных между собой полей совпадают. Проще говоря, запрос вернет только те записи (из таблицы номер два), данные о которых есть в таблице номер один. -

мы добавили в наш запрос ключевое слово - LEFT OUTER JOIN, указав тем самым, что из таблицы слева надо взять все строки, и поменяли ключевое слово WHERE на ON. Кроме ключевого слова LEFT OUTER JOIN может быть использовано ключевое слово RIGHT OUTER JOIN. Тогда будут выбираться все строки из правой таблицы и имеющиеся связанные с ними из левой таблицы. И наконец, возможно полное внешнее объединение, которое извлечет все строки из обеих таблиц и свяжет между собой те, которые могут быть связаны. Ключевое слово для полного внешнего объединения - FULL OUTER JOIN.
SELECT имя_таблицы_1.имя_столбца, имя_таблицы_2.имя_столбца
FROM имя_таблицы_1 ТИП ОБЪЕДИНЕНИЯ имя_таблицы_2
ON условие_объединения;
Группировка и COUNT()
Встроенной функция COUNT(). Эта функция подсчитывает число строк. Причем, если в качестве аргумента этой функции выступает *, то подсчитываются все строки таблицы. А если в качестве аргумента указывается имя столбца, то подсчитываются только те строки, которые имеют значение в указанном столбце.
В нашем примере оба аргумента дадут одинаковый результат, т.к. все столбцы таблицы имеют тип NOT NULL. Давайте напишем запрос, используя в качестве аргумента столбец id_topic:
SELECT COUNT(поле) FROM имя_таблицы;

если мы хотим узнать сколько сообщений имеется в каждой теме. Для этого нам понадобится сгруппировать наши сообщения по темам и вычислить для каждой группы количество сообщений. Для группировки в SQL используется оператор GROUP BY. Наш запрос теперь будет выглядеть так:
SELECT id_topic, COUNT(id_topic) FROM posts
GROUP BY id_topic;
Оператор GROUP BY указывает СУБД сгруппировать данные по столбцу id_topic (т.е. каждая тема - отдельная группа) и для каждой группы подсчитать количество строк
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator valueGROUP BY column_name фильтрацияПредположим, что нас интересуют только те группы, в которых больше двух сообщений. В обычном запросе мы указали бы условие с помощью оператора WHERE, но этот оператор умеет работать только со строками, а для групп те же функции выполняет оператор HAVING:
SELECT id_topic, COUNT(id_topic) FROM posts
GROUP BY id_topic
HAVING COUNT(id_topic) > 2;
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator valueGROUP BY column_name HAVING aggregate_function(column_name) operator value WHERE фильтрует строки, а HAVING - группы.Встроенные функции
Функции - это операции, позволяющие манипулировать данными. В MySQL можно выделить несколько групп встроенных функций:
Строковые функции. Используются для управления текстовыми строками, например, для обрезания или заполнения значений.
Числовые функции. Используются для выполнения математических операций над числовыми данными. К числовым функциям относятся функции возвращающие абсолютные значения, синусы и косинусы углов, квадратный корень числа и т.д. Используются они только для алгебраических, тригонометрических и геометрических вычислений. В общем, используются редко, поэтому рассматривать их мы не будем. Но вы должны знать, что они существуют, и в случае необходимости обратиться к документации MySQL.
Итоговые функции. Используются для получения итоговых данных по таблицам, например, когда надо просуммировать какие-либо данные без их выборки.
Функции даты и времени. Используются для управления значениями даты и времени, например, для возвращения разницы между датами.
Системные функции. Возвращают служебную информацию СУБД.
Итоговые функции
Итоговые функции еще называют статистическими, агрегатными или суммирующими. Эти функции обрабатывают набор строк для подсчета и возвращения одного значения. Таких функций всего пять:
- AVG() Функция возвращает среднее значение столбца.
- COUNT() Функция возвращает число строк в столбце.
- MAX() Функция возвращает самое большое значение в столбце.
- MIN() Функция возвращает самое маленькое значение в столбце.
- SUM() Функция возвращает сумму значений столбца.
Предположим, мы захотели узнать минимальную, максимальную и среднюю цену на книги в нашем магазине. Тогда из таблицы Цены (prices) надо взять минимальное, максимальное и среднее значения по столбцу price. Запрос простой:
SELECT MIN(price), MAX(price), AVG(price) FROM prices;
Еще операторы
Оператор EXISTS берет подзапрос, как аргумент, и оценивает его как верный, если подзапрос возвращает какие-либо записи и неверный, если тот не делает этого.
SQL оператор DISTINCT используется для удаления дубликатов из результирующего набора SELECT.
операторUNION используется для объединения наборов результатов из 2-х или более запросов SELECT. Он удаляет повторяющиеся строки между различными запросами SELECT.
Каждый запрос SELECT внутри оператора UNION должен иметь одинаковое количество полей в результирующих наборах с одинаковыми типами данных.
Синтаксис
SELECT expression1, expression2, … expression_n
FROM tables
[WHERE conditions]
UNION
SELECT expression1, expression2, … expression_n
FROM tables
[WHERE conditions];
Параметры или аргументы
expression1, expression2, expression_n — Столбцы или расчеты, которые вы хотите получить.
tables — Таблицы из которых вы хотите получить записи.
WHERE conditions — Необязательный. Условия, которые должны быть выполнены для выбранных записей.
Примечание
- В обоих запросах SELECT должно быть одинаковое количество выражений.