Давайте сравним четыре сообщения.
Первое:
«Для того чтобы добраться из Москвы до села Васино, нужно сначала долететь на самолёте до города Ивановска. Затем на электричке доехать до Ореховска. Там на пароме переправиться через реку Слоновую в посёлок Ольховка, и оттуда ехать в село Васино на попутной машине».
Второе:
«Как ехать в Васино:
1. На самолёте из Москвы до г. Ивановска.
2. На электричке из г. Ивановска до г. Ореховска.
3. На пароме из г. Ивановска через р. Слоновую в пос. Ольховка.
4. На попутной машине из пос. Ольховка до с. Васино».
Третье:
 Откуда Куда Транспорт
Откуда Куда Транспорт
Москва г. Ивановск Самолёт
г. Ивановен г. Ореховск Электричка
г. Ореховск пос. Ольховка Паром(р. Слоновая)
пос. Ольховка с. Васино Попутная машина
Четвёртое:

Можно считать, что все эти (такие разные по форме!) сообщения содержат одну и ту же информацию. Какие из них проще воспринимать? Очевидно, что человеку «вытащить» полезную информацию из сплошного текста (первое сообщение) сложнее всего. Во втором случае мы сразу видим все этапы поездки и понимаем, в каком порядке они следуют друг за другом. Третье сообщение (таблицу) и четвёртое (схему) можно понять сразу, с первого взгляда. Второй, третий и четвёртый варианты воспринимаются лучше и быстрее первого, потому что в них выделена структура информации, в которой самое главное — этапы поездки в Васино.
Структурирование — это выделение важных элементов в информационных сообщениях и установление связей между ними.
Цели структурирования для человека — облегчение восприятия и поиска информации, выявление закономерностей. При компьютерной обработке структурирование ускоряет поиск нужных данных.
Структуры данных
С некоторыми структурами данных вы уже знакомы. Например, на уроках математики вы изучали множество — некоторый набор элементов. Чтобы определить множество, мы должны перечислить все его элементы (например, множество, состоящее из Васи, Пети и Коли) или определить характерный признак, по которому элементы включаются в это множество (например, множество драконов с пятью зелёными хвостами или множество точек, в которых функция принимает положительные значения).
В документах множество часто оформляют в виде маркированного списка, например:
• процессор;
• память;
• устройства ввода;
• устройства вывода.
В таком списке порядок элементов не важен, от перестановки элементов множество не меняется.
Линейный список состоит из конечного числа элементов, которые должны быть расположены в строго определённом порядке. В отличие от множества элементы в списке могут повторяться. Список обычно упорядочен (отсортирован) по какому-то правилу, например по алфавиту, по важности, по последовательности действий и т. д. В тексте он часто оформляется как нумерованный список, например:
1) надеть носки;
2) надеть ботинки;
3) выйти из дома.
Ещё одна знакомая вам структура — таблица. С помощью таблиц устанавливается связь между несколькими элементами. Элементы в каждой строке связаны между собой — это свойства некоторого объекта (человека).
 Фамилия Имя Рост, см Вес, кг Год рождения
Фамилия Имя Рост, см Вес, кг Год рождения
Иванов Иван 175 67 1996
Петров Пётр 164 70 1998
Сидоров Сидор 168 63 2000
Именно так хранится информация в базах данных: строка таблицы, содержащая информацию об одном объекте, называется записью, а столбец (название свойства) — полем.
Иерархия (дерево)
Линейных списков и таблиц иногда недостаточно для того, чтобы представить все связи между элементами. Например, в некоторой фирме есть директор, ему подчиняются главный инженер и главный бухгалтер, у каждого из них есть свои подчинённые. Если мы захотим нарисовать схему управления этой фирмы, она получится многоуровневой.
Такая структура, в которой одни элементы «подчиняются» другим, называется иерархией. В информатике иерархическую структуру называют деревом.

|
Дерево состоит из узлов и связей между ними (они называются дугами). Самый первый узел, расположенный на верхнем уровне (в него не входит ни одна стрелка-дуга), — это корень дерева. Конечные узлы, из которых не выходит ни одна дуга, называются листьями. Все остальные узлы, кроме корня и листьев, — промежуточные.
Из двух связанных узлов тот, который находится на более высоком уровне, называется родителем, а другой — сыном. Корень — это единственный узел, у которого нет родителя; у листьев нет сыновей. Используются также понятия предок и потомок. Потомок какого-то узла — это узел, в который можно перейти по стрелкам от узла-предка. Соответственно, предок какого-то узла — это узел, из которого можно перейти по стрелкам в данный узел.
Графы
Подумайте, как можно структурировать такую информацию:
«От посёлка Васюки три дороги идут в посёлки Солнцево, Грибное и Ягодное. Между Солнцевым и Грибным и между Грибным и Ягодным также есть дороги. Кроме того, есть дорога, которая идет из Грибного в лес и возвращается обратно в Грибное».
Можно, например, нарисовать схему дорог. Населённые пункты для краткости обозначены латинскими буквами.
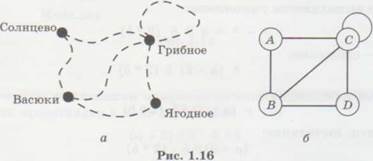
Для исследования таких схем используют графы.
Граф — это набор вершин и связей между ними (рёбер).
Для хранения информации о вершинах и связях графа, соответствующего схеме, можно использовать таблицу (матрицу):
| А | В | С | D | |
| А | ||||
| В | ||||
| С | ||||
| D |
Единица на пересечении строки А и столбца В означает, что между вершинами А и В есть связь. Ноль указывает на то, что связи нет. Такая таблица называется матрицей смежности. Она симметрична относительно главной диагонали (серые клетки в таблице).
На пересечении строки С и столбца С стоит единица, которая говорит о том, что в графе есть петля — ребро, которое начинается и заканчивается в одной и той же вершине.
Можно поступить иначе: для каждой вершины перечислить все вершины, с которыми связана данная вершина. В этом случае мы получим список смежности. Для рассмотренного графа список смежности выглядит так:
(А (В, С), В (А, С, D), С (А, В, С, D), D (В, С))
Если в первом примере с дорогами нас интересуют ещё и расстояния между поселками, каждой связи нужно сопоставить число (вес)
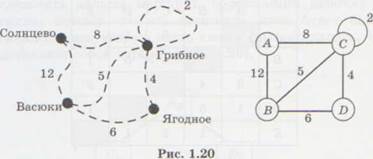
|
Такой граф называется взвешенным, поскольку каждое ребро имеет свой вес. Весом может быть не только расстояние, но и, например, стоимость проезда или другая величина.
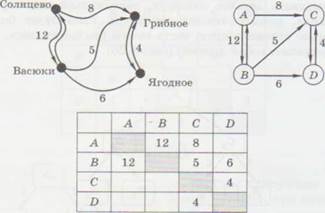
Как хранить информацию о таком графе? Ответ напрашивается сам собой — нужно в таблицу записывать не 1 или 0, а вес ребра. Если связи между двумя вершинами нет, на бумаге можно оставить ячейку таблицы пустой, а при хранении в памяти компьютера записывать в неё условный код, например -1. Такая таблица называется весовой матрицей, потому что содержит веса рёбер. В данном случае она выглядит так:
| А | В | С | D | |
| А | ||||
| В | ||||
| С | ||||
| D |
| А | В | С | D | Е | |
| А | |||||
| В | |||||
| С | |||||
| D | |||||
| Е |
Найдём наилучший путь из А в В — такой, при котором общая стоимость поездки минимальная. Сначала видим, что из пункта А напрямую в В ехать нельзя, а можно ехать только в С и D. Изобразим это на схеме.
 Числа около рёбер показывают стоимость поездки по этому участку, а индексы у названий вершин показывают общую стоимость проезда в данную вершину из вершины А.
Числа около рёбер показывают стоимость поездки по этому участку, а индексы у названий вершин показывают общую стоимость проезда в данную вершину из вершины А.

|
Таким образом, оптимальный (наилучший) маршрут —ADEB, его стоимость — 3. Маршрут ADEC, не дошедший до вершины В, далее проверять не нужно, он не улучшит результат.
Наверное, вы заметили, что при изображении деревьев, которые описывают иерархию (подчинение), мы ставили стрелки от верхних уровней к нижним. Это означает, что для каждого ребра указывается направление, и двигаться можно только по стрелкам, но не наоборот. Такой граф называется ориентированным (или коротко орграфом). Он может служить, например, моделью системы дорог с односторонним движением. Матрица смежности и весовая матрица для орграфа уже не обязательно будут симметричными.
На схеме на всего две дороги с двусторонним движением, по остальным можно ехать только в одну сторону.
Рёбра в орграфе называют дугами. Дуга, в отличие от ребра, имеет начало и конец.
|
Рассмотрим следующую задачу: определить количество возможных путей из вершины А в вершину К для ориентированного графа, показанного на рисунке:

|

|

|

|

|