Как было показано ранее, можно организовать
семантический поиск по S-тегам, если они выделены
из текстов книг. Рассмотрим способ автоматического
выделения S-тегов из текста.
Под ключевыми словами текста мы будем
понимать слова и словосочетания, которые передают
смысл текста и выделяют его среди других текстов в
коллекции.
Чтобы соответствовать содержанию текста, S-тег
должен содержать его ключевые слова. S-тег может
являться ключевым словом, предложением или
абзацем, в котором встретилось ключевое слово.
Таким образом, задача выделения S-тегов может
быть сведена к поиску ключевых слов в тексте.
Так как ключевое слово текста должно выделять
его среди других текстов, то ключевые слова зависят
как от текста, так и от коллекции текстов, которой
противопоставляется этот текст. Если разбить
множество текстов на группы похожих по смыслу
текстов, то можно рассматривать ключевое слово как
отличительный признак для текста,
характеризующий его группу.
С другой стороны, если для разбиения текстов
использовать в качестве признаков ключевые слова,
то можно существенно повысить скорость и качество
разбиения сокращением признакового пространства
и фильтрацией шума.
Таким образом, кластеризация, как процесс
разбиения коллекции текстов на группы, может
использовать выделенные ключевые слова, в то
время как алгоритм выделения ключевых слов может
использовать результаты кластеризации. С помощью
кластеризации можно разбить множество текстов на
группы (кластеры), после чего находить ключевые
слова для текстов относительно полученных групп.
Этот процесс можно повторять несколько раз,
чередуя выделение ключевых слов и кластеризацию.
В итоге получим иерархическую структуру
документов в коллекции и соответствующую ей
иерархию ключевых слов.
Выделение ключевых слов
Дано множество текстов D на множестве
терминов T. Под термином будем понимать слово
или словосочетание. Множество D разбито на
множество кластеров C. Нужно выделить в текстах из
множества D такие ключевые слова, которые
характерны для кластера этого текста.
Традиционно выделение ключевых слов делится
на два этапа. Первый этап представляет собой
выделение кандидатов в ключевые слова. На этом
этапе удаляются стоп-слова, могут фильтроваться
части речи или, например, фильтроваться кандидаты,
которые не содержатся в заголовках статей из
Wikipedia. Второй этап заключается в проверке
кандидатов на семантическую близость к данному
тексту. Для решения этой задачи используют
алгоритмы машинного обучения как с учителем, таки
без него [10].
Основной особенностью нашей задачи в отличие
от стандартной задачи выделения ключевых слов
является то, что ключевые слова должны зависеть не
только от самого документа, но и документов
близких к нему с точки зрения некоторой предметной
области. Предлагаемый подход к решению задач
может быть улучшен с помощью алгоритмов
решения стандартной задачи [10].
Рассмотрим простой подход к решению задачи.
Пусть выбран случайный текст d ∈ D. Для каждого
кластера c ∈ C и термина t ∈ T. Оценим вероятность
того, что d ∈ c при условии, что t ∈ d:
P(d ∈ c | t ∈ d) = |(t ∈ d ∧ d ∈ c)|
|(t ∈ d)|, где
• |(t ∈ d ∧ d ∈ c)| - количество документов
из кластера c, в которых встречается термин t.
• |(t ∈ d)| - количество документов из
кластера c, в которых встречается термин t.
Пусть задан некоторый порог N, тогда будем
считать, что термин t характеризует кластер c, если:
P(d ∈ c | t ∈ d) > 𝑁𝑁 ∗ max
с𝑖𝑖∈C
(P(d ∈ с𝑖𝑖 | t ∈ d)).
Таким образом, для каждого документа
выделяются все термины, которые характеризуют
кластер этого документа и включены в этот
документ, если оценка P(d ∈ c | t ∈ d) достаточно
велика.
Кластеризация
Дано множество документов D на множестве
ключевых слов K. Нужно определить наилучшее
число кластеров, на которые можно разбить
множество документов D и произвести разбиение.
Для решения задачи воспользуемся методом
кластеризации k-means++[11]. Он позволяет за
линейное время разбить множество документов на k
кластеров.
Критерием качества разбиения с параметром k
будем считать значение 𝑄𝑄𝑘𝑘, равное сумме
среднеквадратичных отклонений центров,
полученных кластеров за N итераций. Таким
образом, чем меньше 𝑄𝑄𝑘𝑘, тем более устойчивым и
качественным является разбиение.
Если k выбрано слишком большим или слишком
маленьким, то это скажется на качестве дальнейшего
выделения ключевых слов. Поэтому подбирая
параметр k, нужно задать верхнюю оценку k1 и
нижнюю оценку k2.
Наилучшее значение k находится перебором от k1
до k2. Выбирается такое значение k, при котором
значение 𝑄𝑄𝑘𝑘 за N итераций является минимальным.
Пример. Допустим k1 = 8, k2 =16, n =10. Тогда за
80 итераций может быть найдено наилучшее
разбиение с точки зрения устойчивости с
минимальным значением 𝑄𝑄𝑘𝑘.__

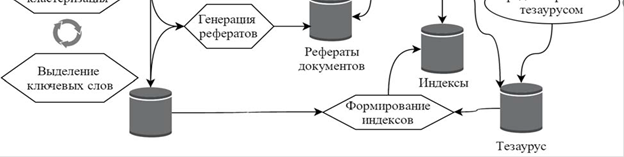
Рисунок 2 Схема взаимодействия
Реферирование
Реализовав семантический поиск по текстам книг,
мы столкнемся с проблемой отображения
результатов поиска. Можно использовать полный
текст книги, удовлетворяющий запросу, аннотацию
книги или заранее автоматически изготовленный
реферат. Более предпочтительным кажется вариант
генерации реферата книги по запросу пользователя.
Реферирование – процесс построения краткого
содержания (реферата) документа. Реферирование
используется для визуализации результатов поиска.
Рефераты бывают статические и динамические.
Статические рефераты используются для
предоставления краткой информации обо всем
документе. Статический реферат формируется один
раз и не зависит от поисковой потребности
пользователя.
Динамические рефераты генерируются в момент
выполнения поискового запроса пользователя и
представляют краткую информацию о релевантных
запросу частях текста.
В рамках работы был выбран простой алгоритм
генерации рефератов, заключающийся в
объединении всех выделенных S-тегов и их
контекста в случае статических рефератов. В случае
генерации динамических рефератов по запросу
находятся его сужения и объединяются вместе со
своим контекстом.
Предложенный алгоритм может быть улучшен с
помощью алгоритма, основанного на
доминантах[12]. Подобные подходы крайне
популярны.
Архитектура системы
На Рис. 2 продемонстрирована схема
взаимодействия внутри системы семантического
поиска по библиотечным данным.
Загрузка данных
Данные необходимо получать из двух
источников.
Источник метаданных поставляет
библиографические записи, Метаданные
попадают в RDF хранилище, откуда
пользователь может их получать с помощью
SPARQL запросов. RDF хранилище
реализовано на базе библиотеки Jena.
Источник документов поставляет тексты
книг, которые сохраняются в файловую
систему. И в индексы СУБД Postgres.