Вопрос 18. Понятие интеллектуального анализа данных. Системы DataMining
Целью интеллектуального анализа данных (англ. Datamining, другие варианты перевода «добыча данных», «раскопка данных») является обнаружение неявных закономерностей в наборах данных.
Классическим считается определение, данное одним из основателей направления Григорием Пятецким-Шапиро.
DataMining – исследование и обнаружение «машиной» (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интеграции.
Неочевидных - это значит, что найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем.
Объективных - это значит, что обнаруженные закономерности будут полностью соответствовать действительности, в отличие от экспертного мнения, которое всегда является субъективным.
Практически полезных - это значит, что выводы имеют конкретное значение, которому можно найти практическое применение.
ПО интеллектуального анализа
Интеллектуальный анализ может проводиться с помощью программных продуктов следующих классов:
· Специализированных «коробочных» программных продуктов для интеллектуального анализа;
· Математических пакетов;
· Электронных таблиц (и различного рода надстроек над ними);
· Средств, интегрированных в системы управления базами данных (СУБД);
· Иных программных продуктов.
В ходе проведения интеллектуального анализа данных проводится исследование множества объектов (или вариантов). В большинстве случаем его можно представить в виде таблицы, каждая строка которой соответствует одному из вариантов, а в столбцах содержатся значения параметров, его характеризующих.
Зависимая переменная – параметр, значение которого рассматривается как зависящее от других параметров (независимых переменных). Именно эту зависимость и необходимо определить, используя методы интеллектуального анализа данных.
Задачи интеллектуального анализа данных:
· Задача классификации;
· Задача регрессии;
· Задача прогнозирования;
· Задача кластеризации;
· Задача поиска ассоциативных правил;
· Задача анализа последовательностей;
· Задача анализа отклонений.
Примеры применения интеллектуального анализа данных.
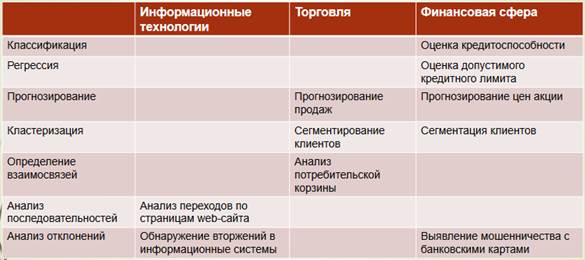
Вопрос 19. Классы систем DataMining
DM - Data Mining - является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории БД и др. Отсюда обилие методов, алгоритмов и математических правил, реализованных в различных действующих системах DM, среди них можно выделить:
Статистические системы
Включают регрессионный, дисперсионный и корреляционный анализ. Реализованы в большинстве современных статистических пакетов, в частности в продуктах компаний SAS Institute, StatSoft и др.
Фильтрация
Необходимость в фильтрации возникает, когда нужно отделить полезную информацию от искажающего его шума за счет сглаживания, очистки, редактирования аномальных значений, устранения незначащих факторов, понижения размерности информации и т.д. Применение фильтрации в системах анализа данных относится к первичной обработке данных и позволяет повысить качество исходных данных, а, следовательно, и точность результата анализа.
Анализ эмпирических моделей
Анализ эмпирических моделей конкретной предметной области, часто применяемые, например, в недорогих средствах финансового анализа.
Кластерный анализ
Кластерный анализ подразделяет гетерогенные данные на гомогенные или полугомогенные группы для объединения сходных событий в группы на основании сходных значений нескольких полей в наборе данных. Метод позволяет классифицировать наблюдения по ряду общих признаков. Кластеризация расширяет возможности прогнозирования. Кластерные модели (иногда также называемые моделями сегментации) весьма популярны при создании систем прогнозирования.
Нейронные сети
Нейросетевые алгоритмы, идея которых основана на аналогии с функционированием нервной ткани и заключается в том, что исходные параметры рассматриваются как сигналы, преобразующиеся в соответствии с имеющимися связями между «нейронами», а в качестве ответа, являющегося результатом анализа, рассматривается отклик всей сети на исходные данные. Здесь для предсказания значения целевого показателя используется наборы входных переменных, математических функций активации и весовых коэффициентов входных параметров. Нейронные сети реализуют алгоритмы на основе сетей обратного распространения ошибки, самоорганизующихся карт Кохонена, RBF-сетей, сетей Хэмминга и других подобных алгоритмов анализа данных.
Ассоциативные правила
Ассоциативные правила выявляют причинно-следственные связи и определяют вероятности или коэффициенты достоверности, позволяя делать соответствующие выводы. Примером такого правила служит утверждение, что в том случае, если произошло событие А, то произойдет и событие В с вероятностью C. Их можно использовать для прогнозирования или оценки неизвестных параметров (значений). Впервые это задача была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis).
Деревья решений
Иерархическая структура, базирующаяся на наборе вопросов, подразумевающих ответ «Да» или «Нет». Позволяют представлять правила в последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Под правилом понимается логическая конструкция, представленная в виде "если... то...". Определяют естественные "разбивки" в данных, основанные на целевых переменных. Деревья решений применяются при решении задач поиска оптимальных решений на основе описанной модели поведения.
Системы рассуждений на основе аналогичных случаев
(Memory-based Reasoning, MBR/ Case-Based Reasoning, CBR) – выбор близкого аналога исходных данных из уже имеющихся исторических данных. Эти алгоритмы основаны на обнаружении некоторых аналогий в прошлом, наиболее близких к текущей ситуации, с тем чтобы оценить неизвестное значение или предсказать возможные результаты (последствия). Называются также методом «ближайшего соседа».