Модель обмена сообщениями. Модели обмена данными в распределенных системах настолько важны, что зачастую та или иная модель параллельных вычислений ассоциируется с конкретным способом взаимодействия процессов или нитей (легковесных процессов). Нить, в отличие от полновесного процесса, не имеет защищенной области памяти, хотя может обладать своими локальными переменными, и разделяет с другими нитями общий ресурс, например, оперативную память. Каждая из нитей управляется своим потоком команд. Далее понятие "процесс" будет использоваться тогда, когда деление на полновесные и легковесные процессы не является существенным. Основные способы взаимодействия процессов в масштабируемых параллельных системах это – обмен сообщениями, разделение общей памяти и прямой доступ к удаленной памяти (RDMA – remote direct memory access).
Модель обмена сообщениями, посредством которых передаются данные, как уже говорилось, применима к различным архитектурам – без единого адресного пространства (мультикомпьютерам и кластерам) и с общей памятью (SMP, DSM). Модели распределенной обработки традиционно использовали механизм передачи сообщений. Так, удаленный вызов процедуры (RPC – remote procedure call) является, по сути, одним из способов передачи сообщений. В средах DCOM (Distributed Component Object Model) и CORBA (Common Object Request Broker) вызов метода представляет собой объектный вариант RPC. При этом RPC реализует схему передачи сообщений, в соответствии с которой в распределенном приложении взаимодействуют процедура-клиент и процедура-сервер. Технологии InfiniBand и RapidIO предусматривают операции передачи сообщений, хотя и предполагают реализацию концепции общей разделяемой памяти.
Разновидности модели обмена сообщениями, главным образом, определяются реализацией механизмов и организацией среды для взаимодействия процессов. Сначала поясним, что понимается под механизмом взаимодействия. Прежде всего, это – режимы и характер передачи / приема сообщений. Различают неблокирующий и блокирующий режимы обмена. При неблокирующем обмене ни один из взаимодействующих процессов не приостанавливается, дожидаясь завершения приема (receive) или передачи (send) сообщения. Если обмен блокирующий, то передающий процесс (source) и/или принимающий процесс (destination) продолжают работу лишь после подтверждения получения сообщения. Характер обмена сообщениями может быть синхронным, асинхронным либо асинхронно/синхронным. При синхронном обмене один из взаимодействующих процессов, достигая некоторого состояния, в котором он готов к обмену, переходит в режим ожидания до тех пор, пока другой процесс не достигнет соответствующего состояния. В этом смысле такой обмен можно назвать блокирующим.
Классические примеры синхронной передачи сообщений – механизмы рандеву в моделях Ч. Хоара (CSP – communicating sequential processes) и Р. Милнера (CCS – calculus of communicating systems). Рандеву представляют собой атомарные, мгновенные акции, или события, соответствующие взаимодействию процессов. Атомарность рандеву означает, что оба процесса одновременно вовлекаются в обмен сообщениями, который является одним непрерывным действием. Механизмы рандеву поддерживаются такими языками, как Occam, Lotos, Ada. В модели CSP механизм взаимодействия поддерживается командой ввода
<input command>:=<source>?<target variable>
и командой вывода
<output command>:=<destination>!<expression>,
где target variable – входная (принимаемая) переменная, а expression – выходное (передаваемое) выражение.
При асинхронном взаимодействии возврат из процедуры обмена осуществляется сразу же после передачи сообщения без ожидания завершения приема. Такой обмен можно охарактеризовать как неблокирующий. В случае асинхронно/синхронного обмена операция передачи сообщения является асинхронной (процесс-отправитель не блокируется), а операция приема – синхронной (процесс-получатель блокируется). В литературе иногда блокирующий обмен называют обменом с синхронизацией, а неблокирующий обмен – асинхронным. Используя понятия "синхронный", "асинхронный", мы будем придерживаться несколько иной точки зрения. Дело в том, что для организации асинхронного обмена необходимо наличие так называемых буферов, которые упорядочивают сообщения в соответствии с некоторой дисциплиной, как правило, FIFO (first in first out), т.е. "первым вошел – первым вышел". Например, при асинхронной передаче сообщения оно может копироваться в буфер процесса-отправителя, который продолжает работу одновременно с пересылкой сообщения процессу-получателю. Буферизованный обмен сообщениями произвольных размеров поддерживается в ОС UNIX и Windows NT. В системе UNIX процессы взаимодействуют через каналы – специальный вид буфера, не сохраняющего границы сообщений. В ОС NT, помимо каналов, механизмы взаимодействия реализуются почтовыми ящиками, сокетами, RPC и общими файлами. Буферные прием/передача специфицируются также средствами системы программирования MPI. Механизм рандеву не требует никакой буферизации. В дальнейшем под синхронным и асинхронным взаимодействием процессов мы будем понимать соответственно безбуферный или буферизованный обмен сообщениями.
Назначение среды взаимодействия – обеспечение парных и коллективных обменов сообщениями между процессами, которые могут объединяться в группы. Когда говорят о парном взаимодействии процессов, иногда используют понятие канала – своего рода, виртуальной однонаправленной коммуникационной линии, связывающей процессы. Каналы можно создавать и удалять. При отправке сообщения достаточно указать идентификатор канала без указания имени принимающего процесса. В соответствии с механизмами взаимодействия процессов различают синхронные, асинхронные и асинхронно/синхронные каналы. Так, при асинхронном обмене сообщение посылается в канал, связывающий передающий и принимающий процессы, причем работа передающего процесса не блокируется. В некоторых моделях с каналами ассоциируются очереди (потоки) сообщений.
Подобный механизм, в частности, описывает взаимодействие процессов в модели Г. Кана и взаимодействие акторов (процессов) в потоковых моделях (dataflow), например, в модели Дж. Денниса, посредством пересылки токенов (атомарных значений данных).
Пример описания канала (channel) и процесса (Process) в модели Кана:
Integer channel X, Y, Z, T1, T2;
Process f (integer in U, V; integer out W);
Здесь X, Y, Z, T1, T2 – каналы для передачи целочисленных переменных между взаимодействующими процессами (тип переменных может быть произвольным – булевым, вещественным и т.д.). Процесс f связан с другими процессами двумя входными каналами, по которым передаются целочисленные переменные U, V, и одним выходным каналом для передачи целочисленной переменной W.
В модели Кана рассматриваются бесконечные потоки сообщений, а в таком разрешимом случае акторных моделей, как SDF (Synchronous Data Flow), емкость буфера FIFO ограничивается. При этом говорят о реализуемости модели SDF с ограниченным размером памяти токенов.
На рис. 1.8 показан простейший информационный граф модели SDF: вершины обозначают акторы, дуги – информационные связи, маркировка начал и концов дуг соответствует числу потребляемых и производимых токенов при однократном "срабатывании" соответствующего актора.
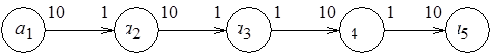
Рис. 1.8. Пример информационного графа SDF-модели
Так, актор 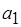 однократно производит 10 токенов, актор
однократно производит 10 токенов, актор  однократно потребляет один токен. Размер выходного буфера должен быть не менее 10 токенов, а входного буфера – не менее одного токена. Возникает следующий вопрос: можно ли так организовать итеративное выполнение процессов в модели, заданной SDF-графом, чтобы размеры буферов были ограничены и априори заданы.
однократно потребляет один токен. Размер выходного буфера должен быть не менее 10 токенов, а входного буфера – не менее одного токена. Возникает следующий вопрос: можно ли так организовать итеративное выполнение процессов в модели, заданной SDF-графом, чтобы размеры буферов были ограничены и априори заданы.
Для разрешимых случаев, подобных тому, который показан на рис. 1.8, на этот вопрос можно ответить утвердительно. Чтобы определить необходимый размер памяти токенов и, соответственно, число "срабатываний" каждого актора, решают так называемое уравнение баланса 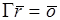 , где
, где 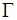 – топологическая матрица,
– топологическая матрица, 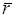 – вектор-столбец числа повторений выполнения каждого из акторов, а
– вектор-столбец числа повторений выполнения каждого из акторов, а  – вектор-столбец, элементы которого равны нулю. Элемент
– вектор-столбец, элементы которого равны нулю. Элемент 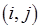 топологической матрицы (
топологической матрицы (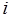 – номер строки,
– номер строки, 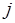 – номер столбца) равен целому положительному числу
– номер столбца) равен целому положительному числу 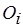 , если -й актор производит токенов, передаваемых по -й дуге. Элемент равен целому отрицательному числу –
, если -й актор производит токенов, передаваемых по -й дуге. Элемент равен целому отрицательному числу – 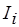 , если -й актор потребляет токенов по входящей -й дуге. Так, для SDF-графа, показанного на рис. 1.8, топологическая матрица и решение уравнения баланса имеют следующий вид:
, если -й актор потребляет токенов по входящей -й дуге. Так, для SDF-графа, показанного на рис. 1.8, топологическая матрица и решение уравнения баланса имеют следующий вид:
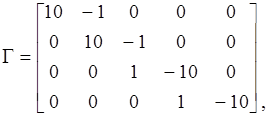
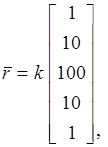
где 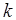 – произвольный целочисленный коэффициент не меньший 1.
– произвольный целочисленный коэффициент не меньший 1.
Возможны и такие виды SDF-графов, когда нетривиального решения уравнения баланса, с отличными от 0 элементами вектора , не существует (соответствующие примеры рассматриваются в п. 2.3 раздела 2). Под разрешимостью модели SDF понимается возможность получения ответа на вопрос, существует или нет нетривиальное решение уравнения баланса.
Чтобы локализовать взаимодействие параллельных процессов, используются группы процессов, каждой из которых предоставляется отдельная коммуникационная среда – коммуникатор. Эти понятия относятся к числу основных в стандарте интерфейса передачи сообщений MPI. Группа – совокупность процессов, любой из которых имеет уникальный номер в соответствующем коммуникаторе. Процесс, одновременно входящий в разные коммуникаторы, характеризуется различными номерами. В MPI параллельные процессы порождаются лишь однажды после инициализации параллельной части программы с помощью функции MPI_Init. Число процессов в ходе выполнения программы не изменяется.
После инициализации коммуникатор MPI_COMM_WORLD задает стандартную среду с номерами процессов от 0 до 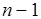 ,
, 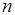 – число процессов в группе. Над группами определены такие теоретико-множественные операции, как пересечение, объединение и т.д.
– число процессов в группе. Над группами определены такие теоретико-множественные операции, как пересечение, объединение и т.д.
MPI позволяет реализовать как блокирующий, так и неблокирующий обмен сообщениями. Заметим, что и в том, и в другом случаях осуществляется прием/передача сообщений через буферы. Функции передачи (Send) и приема (Recv) с блокировкой имеют следующий вид:
MPI_Send (buf, count, datatype, dest, tag, comm),
MPI_Recv (buf, count, datatype, source, tag, comm, status).
Здесь buf – начальный адрес буфера передающего/принимающего процесса; count – число элементов данных в посылаемом/принимаемом сообщении; datatype – тип передаваемых/принимаемых данных; dest/source – номер принимающего/передающего процесса; tag – тег сообщения; comm – идентификатор коммуникатора; status – параметры принятого сообщения.
При организации среды взаимодействия процессов необходимо учитывать опасность возникновения тупиковых ситуаций (дедлоков), заключающихся во взаимной блокировке обменивающихся сообщениями процессов. Простейшее проявление дедлока состоит в том, что один процесс не может передать сообщение другому процессу, поскольку этот, другой процесс ждет, когда первый процесс примет сообщение от него. Например, тупик может возникнуть при использовании блокирующих функций MPI_Send и MPI_Recv. Для предотвращения подобной ситуации можно воспользоваться соответствующими неблокирующими функциями:
MPI_Isend (buf, count, datatype, dest, tag, comm, request),
MPI_Irecv (buf, count, datatype, source, tag, comm, request),
где request – идентификатор неблокирующей (асинхронной) операции передачи/приема.
При передаче/приеме с помощью функций MPI_Isend/ MPI_IRecv возврат из функций происходит сразу после начала процесса передачи/приема без ожидания пересылки/получения всего сообщения буфера buf. Окончание процессов передачи/приема, когда можно повторно воспользоваться соответствующим буфером, например, записать в него новое сообщение, определяется параметром request и специальными функциями MPI_Wait, MPI_Test.
Избежать возможного тупика позволяет также функция совмещенных передачи и приема сообщений
MPI_Sendrecv (sbuf, scount, stype, dest, stag, rbuf, rcount, rtype, source, rtag, comm, status),
где sbuf – начальный адрес буфера передающего процесса; scount – число передаваемых элементов сообщения; stype – тип передаваемых данных; dest – номер принимающего процесса; stag – тег посылаемого сообщения; rbuf – начальный адрес буфера принимающего процесса; rcount – число принимаемых элементов сообщения; rtype – тип принимаемых данных; source – номер передающего процесса; rtag – тег принимаемого сообщения; comm – идентификатор коммуникатора; status – параметры принятого сообщения.
Эта функция совмещает в одном запросе и посылку, и прием сообщения, что гарантирует предотвращение тупиковых ситуаций.
Существуют и сильные, и слабые стороны в синхронном и асинхронном обменах сообщениями. Так, CSP и CCS адекватно представляют недетерминизм, необходимый в приложениях, связанных с разделением ресурсов: модели баз данных типа "клиент-сервер", мультизадачные системы, интерливинг в использовании аппаратных средств и т.д. Однако попытки использования CSP и CCS для описания распределенных систем со "слабосвязанными" процессорами, а также для моделирования детерминированных приложений вызывают серьезные трудности. Здесь необходимы модели, основанные либо на асинхронной передаче сообщений, либо на разделении переменных общей памяти. Модель Кана допускает асинхронный обмен сообщениями между процессами, однако является сугубо детерминированной моделью вычислений с преобладанием потоков данных.
Понятие среды и, в частности, канала используется, главным образом, для описания событий, называемых взаимодействиями совместно протекающих процессов. Заметим, что механизм взаимодействия объектов приложения на основе неструктурированных, не упорядоченных особым образом событий поддерживается такими средами, как DCOM, CORBA и JavaBeans. Вычисления в этих средах базируются на вызовах метода, не требующих какого-либо упорядочения. Поскольку при этом нет необходимости во встроенных механизмах синхронизации, программист может просто реализовать асинхронные взаимодействия объектов без всякого риска возникновения дедлока. Попытки же синхронизации, например, для упорядочения передачи данных, принуждают программиста заботиться о предотвращении тупиков и обеспечении однозначности вычислительного процесса. В ОС UNIX тупики исключаются путем специальной организации взаимодействия процессов и буферизации сообщений в каналах (pipes), откуда байты считываются в порядке записи. Сообщения можно считывать порциями произвольных размеров. Еще один способ взаимодействия, основанный на объявлении событий, получил название "издавай и подписывайся" (publish and subscribe). Какой-либо компонент приложения декларирует заинтересованность в наступлении некоторых событий ("подписывается"), другой обуславливает наступление событий ("издает"). Примером одного из наиболее сложных воплощений этого принципа в системе параллельного программирования Linda может служить среда JavaSpaces компании Sun Microsystems, надстраиваемая над распределенной компонентной технологией Jini. Более простая версия может быть реализована на основе прикладного программного интерфейса службы событий в среде CORBA. Механизм "издавай и подписывайся" хорошо подходит для описания распределенных недетерминированных взаимодействий: "издателю" не нужно знать, кто "подписчики", состав которых может изменяться во времени.
Основные достоинства модели обмена сообщениями заключаются в следующем. Во-первых, снимаются проблемы разделяемой памяти, связанные с согласованным состоянием данных. Во-вторых, уделяется внимание обмену данными, который требует существенных затрат времени даже при использовании высокоскоростных сетей. В-третьих, учитываются такие аспекты, как произвольная структура (длина) сообщений и, возможно, различные последовательности (недетерминизм) формирования составных частей сообщений, что характерно для распределенных систем с коммутацией пакетов.
Последний тезис находит отражение и в стандарте MPI. В нем предусматривается возможность формирования сообщений из разнотипных данных с помощью специального механизма – введения производных типов данных. Далее, функции сборки MPI_Gatterv и раздачи MPI_Scatterv данных позволяют процессам коммуникатора обмениваться порциями данных различных размеров. Наконец, при передаче нескольких сообщений разными процессами таким образом, что эти сообщения соответствуют одной и той же функции MPI_Recv, последовательность их получения принимающим процессом заранее не определена.
Модель общей памяти. Разделение общей памяти для организации взаимодействия процессов предполагает, что один процесс размещает данные в известную область памяти, а другой может их считывать. Сложность реализации такого взаимодействия обуславливается необходимостью обеспечения безопасности записи (удаления) и считывания данных. Два основных подхода к решению этой проблемы – взаимное исключение критических интервалов и координация (условная синхронизация) процессов. В критическом интервале лишь один процесс имеет исключительный доступ к общей переменной. Для установки критических интервалов используются операции синхронизации, реализуемые, например, с помощью семафоров, блокирования процессов или битов "занято/свободно", присоединяемых к разделяемым словам общей памяти.
Так, в стандарте OpenMP критический интервал программы оформляется с помощью специальных директив:
!$OMP CRITICAL [имя интервала]
код программы
!$OMP END CRITICAL [имя интервала]
Известно, что программа, разработанная с помощью OpenMP, делится на последовательные и параллельные области. Параллельные области выполняются набором нитей, которые могут работать с общими и локальными переменными, обозначаемыми соответственно как SHARED и PRIVATE. В критическом интервале лишь одна нить может исполнять код программы. Все остальные нити ждут, пока эта нить не выполнит директиву END CRITICAL и не выйдет из критического интервала. Существует также директива, гарантирующая неделимый доступ к памяти и корректную работу с общей переменной, следующей за оператором ATOMIC.
Координация действий процессов может быть осуществлена с помощью барьерной синхронизации, поддерживаемой, в частности, стандартом OpenMP. Барьер определяет такое состояние программы, при достижении которого каждый процесс задерживается до тех пор, пока все остальные процессы не достигнут барьера. В OpenMP для этого существует директива
!$OMP BARRIER
Координация нитей, т.е. упорядочение исполнения параллельных областей программы, может быть реализована следующим образом:
!$OMP ORDERED
код программы
!$OMP END ORDERED
При этом ни одна из нитей не может начать выполнение кода программы, если не завершены предшествующие ему последовательные области программы.
Выбор той или иной системы синхронизации зависит от особенностей решаемой задачи. При этом известно, что переусложнение и избыточность затрат при реализации синхронизации процессов ведет к потере эффективности вычислений. Поэтому внимание исследователей уже давно привлекают принципы асинхронного программирования, в частности, на основе событийного, потокового и динамического управления процессами. Известны также примеры аппаратной поддержки синхронизации, например, барьеров в компьютерах Cray T3D/3E. Стандарт OpenMP, предоставляющий богатый выбор средств синхронизации, исходит из того, что синхронизация в каждой конкретной задаче должна быть минимально необходимой.
Модель общей памяти чаще всего используется в SMP- и DSM-архитектурах. Ее достоинства обусловлены следующими факторами. Во-первых, имеется единое адресное пространство, что упрощает программирование и отладку. Во-вторых, нет необходимости явного задания операций посылки и приема сообщений, когда необходимо обеспечивать своевременную смену данных в буферах. В-третьих, программы, разработанные для SMP-систем, могут быть перенесены на DSM-системы.
Главная проблема, как уже отмечалось, поддержание непротиворечивого, согласованного состояния памяти в соответствии с принимаемой моделью. Кратко, на качественном уровне рассмотрим некоторые способы обеспечения согласованности памяти, имеющие, прежде всего, практическое значение.
Будем использовать следующую символику. Обозначим через 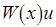 операцию записи в переменную
операцию записи в переменную 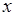 некоторого значения
некоторого значения 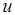 , а через
, а через 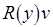 – операцию чтения из переменной
– операцию чтения из переменной 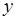 значения
значения 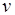 .
.
Историю выполнения операций записи и чтения будем представлять диаграммами следующего вида:
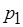 :
: 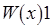

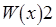
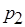 :
: 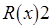
Смещение операции записи , выполняемой процессом , вправо относительно , а операции чтения , которую осуществляет процесс , вправо относительно вдоль горизонтальной линии означает, что предшествует , а последняя, в свою очередь, предшествует . Отсутствие смещения операций вдоль горизонтальной линии говорит о том, что они выполняются параллельно либо одна из них начинается, когда другая еще может быть не закончена.
Строгая согласованность предписывает: операция чтения должна возвращать значение данных, соответствующее последней по времени операции записи. Выше приведен пример строгой согласованности: операция чтения возвращает значение 2, присвоенное переменной последней из операций записи, а именно, .
Пример нарушения этого правила:
:
: 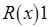
В однопроцессорных системах или системах с одним модулем памяти, обслуживающим запросы в порядке поступления, соблюдение этого принципа вполне естественно. Что же касается распределенных систем, то здесь все осложняется отсутствием "единого времени", которое позволило бы полностью упорядочить действия процессоров, но неминуемо привело бы к снижению производительности. Поэтому необходимы модели с более слабыми требованиями к согласованности.
В модели последовательной согласованности (Л. Лэмпорт, 1979 г.) все процессы наблюдают одну и ту же последовательность обращений к памяти. Практически это означает, что процессор, выполняющий запись, ожидает от других процессоров подтверждения модификации или объявления модифицируемых копий данных несостоятельными. Это обеспечивает единый порядок записей, видимый всеми процессами. Тем не менее последовательная согласованность не гарантирует, что операция чтения возвратит значение, записанное чуть раньше другим процессом. Ниже приводится история обращения к памяти в соответствии с моделью последовательной согласованности:
:
: 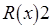
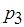 :
:
Процессы и считывают одни и те же значения, причем процесс считывает значение, которое еще не записано. Технически это, конечно, невозможно, однако не противоречит модели последовательной согласованности и демонстрирует ее гибкость по отношению к строгой согласованности. Пример нарушения правила последовательной непротиворечивости данных:
:
:
:
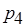 :
:
Последовательно согласованная память не позволит процессу получить значения 1, 2, если процесс считал значения 2, 1.
Модель причинной согласованности характеризуется тем, что последовательность потенциально причинно-зависимых операций записи должна наблюдаться всеми процессами одинаково, другие же, например, параллельно выполняемые операции записи, могут наблюдаться в разных последовательностях.
Понятие потенциальной причинной зависимости может трактоваться следующим образом. Положим, один процесс модифицирует значение некоторой переменной, затем другой процесс считывает его и модифицирует значение этой же или другой переменной. Тогда эти модификации переменных потенциально зависимы. Пример допустимой последовательности операций в соответствии с моделью причинной согласованности:
: 
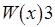
:
: 
:
Здесь операции записи и являются причинно-зависимыми, а и – нет. Процессы и наблюдают вторую пару операций записи в разных последовательностях.
Следующая модель согласованности применима в так называемой конвейеризованной памяти (PRAM – pipelined random access memory). Она характеризуется тем, что операции записи, выполняемые одним процессом, наблюдаются остальными процессами одинаково, в том порядке, в котором они производились, а операции записи, осуществляемые разными процессами, могут быть видны в разных последовательностях:
:
:
:
:
Здесь процессы и наблюдают записи со стороны процессов и по-разному, хотя операции и являются потенциально причин<