Оценивание параметров линейной модели множественной регрессии
Модель 1: МНК, использованы наблюдения 1-24
Зависимая переменная: Y
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | 60,4442 | 7,15865 | 8,4435 | <0,00001 | *** |
| X1 | 0,193684 | 0,398708 | 0,4858 | 0,63268 | |
| X2 | -0,0798086 | 0,0720325 | -1,1080 | 0,28171 | |
| X3 | 0,053812 | 0,208385 | 0,2582 | 0,79900 | |
| X4 | 0,639778 | 0,170594 | 3,7503 | 0,00136 | *** |
| Среднее зав. перемен | 76,08333 | Ст. откл. зав. перемен | 14,58980 | |
| Сумма кв. остатков | 2382,109 | Ст. ошибка модели | 11,19706 | |
| R-квадрат | 0,513441 | Испр. R-квадрат | 0,411008 | |
| F(4, 19) | 5,012443 | Р-значение (F) | 0,006266 | |
| Лог. правдоподобие | -89,22678 | Крит. Акаике | 188,4536 | |
| Крит. Шварца | 194,3438 | Крит. Хеннана-Куинна | 190,0162 |
Рисунок 1 – Окно с результатами вычислений
Проверка нормальности распределения регрессионных остатков
Для проверки значимости модели и значимости коэффициентов нужно убедиться, что остатки нормально распределены.
 : распределение регрессионных остатков не отличается от нормального.
: распределение регрессионных остатков не отличается от нормального.
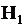 : распределение регрессионных остатков отличается от нормального.
: распределение регрессионных остатков отличается от нормального.

Рисунок 2 – Гистограмма регрессионных остатков при автоматическом разбиении на интервалы

Рисунок 3 – Интервальный ряд абсолютных и относительных частот
Таким образом, наблюдаемое значение статистики хи-квадрат составило 0,388 и вероятность того, что такое значение получилось случайно, если верна гипотеза , составляет всего 0,84. Если принять уровень значимости  , то мы должны принять нулевую гипотезу о нормальном распределении регрессионных остатков, так как p-значение 0,84>0,05. Известно, что необходимыми условиями применимости критерия хи-квадрат является достаточно большой объем выборки, а также величина абсолютной частоты в каждом интервале не меньше 5. В нашем случае выборка (N=24) невелика, и как видно из рисунка 2, не наблюдается нулевая частота. Поэтому распределение регрессионных остатков не отличается от нормального.
, то мы должны принять нулевую гипотезу о нормальном распределении регрессионных остатков, так как p-значение 0,84>0,05. Известно, что необходимыми условиями применимости критерия хи-квадрат является достаточно большой объем выборки, а также величина абсолютной частоты в каждом интервале не меньше 5. В нашем случае выборка (N=24) невелика, и как видно из рисунка 2, не наблюдается нулевая частота. Поэтому распределение регрессионных остатков не отличается от нормального.
Также для проверки согласия распределения с нормальным используются такие критерии, как критерий Дурника-Хансена, критерий Шапиро-Уилка, критерии Лиллифорса и Жака-Бера. Выполним проверку нормальности распределения регрессионных остатков на их основе.
В итоге получаем:

Рисунок 4 – Результаты проверки
По критериям Шапиро-Уилка, Лиллифорса и Жака-Бера на уровне значимости нулевая гипотеза о нормальности распределения регрессионных остатков отвергается (достигаемые уровни значимости равны 0,71,0,86 и 0,77соответственно).
Исследование построенной регрессионной модели
Так как можно считать, что регрессионные остатки имеют нормальное распределение, то есть смысл проводить дальнейший анализ построенного уравнения множественной регрессии. Вернемся к рисунку 1:
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | 60,4442 | 7,15865 | 8,4435 | <0,00001 | *** |
| X1 | 0,193684 | 0,398708 | 0,4858 | 0,63268 | |
| X2 | -0,0798086 | 0,0720325 | -1,1080 | 0,28171 | |
| X3 | 0,053812 | 0,208385 | 0,2582 | 0,79900 | |
| X4 | 0,639778 | 0,170594 | 3,7503 | 0,00136 | *** |
Оценка модели регрессии выглядит следующим образом:
ŷ = 60,44 + 0,19Х1 -0,08Х2 +0,05Х3 + 0,64Х4
(7,16) (0,40) (0,07) (0,21) (0,17)
В круглых скобках записаны стандартные ошибки оценки коэффициентов 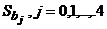 .
.
Проверка адекватности линейной модели множественной регрессии (ЛММР) выборочным данным
Общая вариация результативного признака складывается из вариации функции «регрессии», обусловленной варьированием значений объясняющих переменных 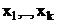 (факторной дисперсии), и из вариации случайной величины
(факторной дисперсии), и из вариации случайной величины 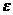 относительно функции «регрессии» (остаточной дисперсии), то есть:
относительно функции «регрессии» (остаточной дисперсии), то есть:

где 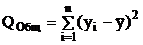 - общая сумма квадратов;
- общая сумма квадратов;
 - факторная сумма квадратов;
- факторная сумма квадратов;
 - остаточная сумма квадратов.
- остаточная сумма квадратов.
При этом, чем лучше построенное уравнение регрессии описывает исходные данные, тем больше будет факторная дисперсия  и тем меньше будет остаточная дисперсия
и тем меньше будет остаточная дисперсия  . Этот очевидный факт положен в основу критерия проверки адекватности (значимости) построенного уравнения регрессии. е будет факторен\а оно обхясняеплаты
. Этот очевидный факт положен в основу критерия проверки адекватности (значимости) построенного уравнения регрессии. е будет факторен\а оно обхясняеплаты
Выдвигается нулевая гипотеза о том, что ЛММР неадекватна выборочным данным (ни один из признаков не оказывает значимого влияния на y):

 .
.
Для проверки гипотезы Н0 используется статистика
 или
или 
которая при справедливости Н0 имеет распределение Фишера – Снедекора с числом степеней свободы 
Это означает, что можно указать такое число  , что если гипотеза Н0 верна, то указанная статистика будет принимать значения меньше этого числа с заранее заданной, близкой к 1 вероятностью
, что если гипотеза Н0 верна, то указанная статистика будет принимать значения меньше этого числа с заранее заданной, близкой к 1 вероятностью  , и с вероятностью
, и с вероятностью 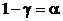 будет принимать значения больше . Следовательно, если наблюдаемое значение статистики
будет принимать значения больше . Следовательно, если наблюдаемое значение статистики  окажется больше, чем , то либо произошел один из тех
окажется больше, чем , то либо произошел один из тех 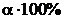 случаев, когда на самом деле Н0 верна и отвергая ее, мы ошибаемся, либо Н0 действительно неверна. Из описания ясно, что представляет собой квантиль уровня
случаев, когда на самом деле Н0 верна и отвергая ее, мы ошибаемся, либо Н0 действительно неверна. Из описания ясно, что представляет собой квантиль уровня  распределения Фишера-Снедекора с указанными степенями свободы, или, -ую критическую точку этого же распределения.
распределения Фишера-Снедекора с указанными степенями свободы, или, -ую критическую точку этого же распределения.
Из рисунка 1 видно:
R-квадрат 0,513441 Испр. R-квадрат 0,411008
F(4, 19) 5,012443 Р-значение (F) 0,006266
Наблюдаемое значение статистики F составило  . Найдем критическое значение:
. Найдем критическое значение:

Рисунок 5 – Результат расчета критического значения распределения Фишера-Снедекора
Существует еще один вариант процедуры проверки статистической гипотезы, реализованной в большинстве статистических пакетов. Для наблюдаемого значения рассчитывается вероятность того, что статистика примет значение больше него (так называемый «достигаемый уровень значимости»), которая сравнивается с заданным уровнем значимости. Если рассчитанная вероятность окажется меньше, что нулевая гипотеза отвергается. Вернемся к рисунку 1:
R-квадрат 0,513441 Испр. R-квадрат 0,411008
F(4, 19) 5,012443 Р-значение (F) 0,006266
Достигаемый уровень значимости (p-значение) составил 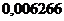 , что намного меньше , следовательно, Н0 отвергается, модель значима.
, что намного меньше , следовательно, Н0 отвергается, модель значима.
Поскольку нулевая гипотеза о незначимости уравнения регрессии была отвергнута, нужно проверить гипотезы о значимости коэффициентов уравнения регрессии.