SOUL OF SPAIN
In the rain in the rain in the rain in the rain in Spain.
Does it rain in Spain?
Oh yes my dear on the contrary and there are no bull fights.
The dancers dance in long white pants
It isn't right to yence your aunts
Come Uncle, let's go home.
Home is where the heart is, home is where the fart is.
Come let us fart in the home.
There is no art in a fart.
Still a fart may not be artless.
Let us fart an artless fart in the home.
Democracy.
Democracy.
Bill says democracy must go.
Go democracy.
Go
Go
Go
Bill's father would never knowingly sit down at table with a Democrat.
Now Bill says democracy must go.
Go on democracy.
Democracy is the shit.
Relativity is the shit.
Dictators are the shit.
Menken is the shit.
Waldo Frank is the shit.
The Broom is the shit.
Dada is the shit.
Dempsey is the shit.
This is not a complete list.
They say Ezra is the shit.
But Ezra is nice.
Come let us build a monument to Ezra.
Good a very nice monument.
You did that nicely
Can you do another?
Let me try and do one.
Let us all try and do one.
Let the little girl over there on the corner try and do one.
Come on little girl.
Do one for Ezra.
Good.
You have all been successful children.
Now let us clean the mess up.
The Dial does a monument to Proust.
We have done a monument to Ezra.
A monument is a monument.
After all it is the spirit of the thing that counts.
Задание
Используя формулы Шеннона (H =-ΣPi log2 Pi), и Хартли (Н = log2N):
1. рассчитать частоту появления слов по начальной букве русского алфавита (Pi);
2. рассчитать количественную меру информации для данного произведения (H);
3. построить график дискретной функции Pi = Pi(x);
4. рассчитать математическое ожидание (c) и среднее квадратичное отклонение (σ) нормальной кривой распределения.
Методика выполнения работы
Предложенное задание выполняется с использованием программ Microsoft Word и Microsoft Excel.
Сохраните в новом текстовом файле текст стихотворения «Soul of spain».
Запустите программу Microsoft Word, откройте файл «Soul of spain».
Сохраняем стихотворение на диске.
1. Для дальнейшей работы с текстом необходимо заменить все пробелы символами конца строки. Для этого нужно в меню «Правка», выбрать команду «Заменить». В окне диалога «Заменить» после слова «Найти:» поставить пробел. Щелкнуть в белом поле после слов «Заменить на:». Нажать на кнопку «Больше» и затем на кнопку «Специальный». В открывшемся меню выбрать пункт «Разрыв строки», щелкнуть на кнопке «Заменить все», что позволит заменить все пробелы на символы конца абзаца.
Текст стихотворения расположится вертикально столбиком
2. Для переноса текста в программу Microsoft Excel копируем весь текст в буфер обмена (меню «Правка» команда «Выделить все»), затем на команде «Копировать» ()). Запускаем программу Microsoft Excel. Щелкаем в ячейке А1 и нажимаем кнопку «Вставить» (). Если все сделано правильно, то слова стихотворения расположатся в столбик в колонке А. Затем щелкнуть на надписи Microsoft Word, расположенной внизу экрана, после чего в категории «Файл» выбираем команду «Выход». На вопрос «Сохранить изменения в файле?» ответить «Нет.
3.После закрытия программы MicrosoftWord возвращаемся в программу Microsoft Excel и производим автоматический выбор первой буквы из всех слов текста. Для этого необходимо щелкнуть в ячейке В1 и затем на кнопке «Вставка функции» (). В окошке «Вставка функции» в окошке «Категории» выбрать «Текстовые», затем в окошке «Функция» выбрать «ЛЕВСИМВ» и щелкнуть на кнопке «ОК.
В появившемся окошке после слова «Текст» набрать «А1» (английский язык, без кавычек) и щелкнуть на кнопке «ОК». В ячейке В1 появится первая буква слова из ячейки А1. Размножить формулу из ячейки В1 вниз до конца слов в столбце А (рис.7). Проверить: если в ячейке в столбце А находится слово, то в той же строке в столбце В должна быть его первая буква. Если ячейка в столбце В пуста или в ней другой символ, необходимо щелкнуть на ячейке в столбце А и в строке формул стереть все символы слева от слова.
4. Теперь для подсчета числа слов, начинающихся на ту или иную букву, необходимо организовать подсчет количества конкретных букв в столбце В. С этой целью в ячейках D1:Н28 формируем таблицу. В строке 1 оформляем заголовок таблицы, введя в ячейку D1 текст № п/п, в ячейку Е1 - Буква, в ячейку F1 - Кол-во, в ячейку G1 - Рi, в ячейку Н1 - Pi*Log(Pi;2), причем индекс делается так: набираются оба символа, затем в строке формул выделяется только символ, который необходимо сделать индексом входим в меню «Формат», выбираем «Формат ячейки» и ставим галочку (щелкнув мышкой в квадратике рядом с надписью) «нижний индекс». Нажимаем «ОК». Далее заполняем колонку № п/п. Для этого в ячейку D2 вводим 1, в ячейку D2 2, затем выделяем ячейки D2:D3 и размножаем вниз до цифры 28. Затем заполняем колонку «Буква» латинскими буквами в порядке их традиционного расположения в алфавите. Следующая колонка «Количество». В ячейку F2 вставим формулу «СЧЕТЕСЛИ» из категории «Статистические». Диапазон указывается «В2:В276» (английский регистр), условие «Е2», затем размножается формула до конца таблицы. В ячейку Е28 вводится «N=», а в ячейку F28 вставляется формула суммы всех букв. Для этого щелкается на этой ячейке и затем по кнопке «Автосумма» () и нажимается клавиша «Enter», на клавиатуре.
Таблица 1
| № п/п | Буква | Количество | Pi | Pi*Log(Pi;2) |
| a | 0,103448 | 0,33858812 | ||
| b | 0,034483 | 0,167516586 | ||
| c | 0,042146 | 0,192541066 | ||
| d | 0,095785 | 0,324142702 | ||
| e | 0,019157 | 0,109309921 | ||
| f | 0,038314 | 0,180305667 | ||
| g | 0,045977 | 0,204273264 | ||
| h | 0,030651 | 0,154112061 | ||
| i | 0,10728 | 0,345499732 | ||
| j | ||||
| k | 0,003831 | 0,030758261 | ||
| l | 0,045977 | 0,204273264 | ||
| m | 0,049808 | 0,215544297 | ||
| n | 0,038314 | 0,180305667 | ||
| o | 0,042146 | 0,192541066 | ||
| p | 0,007663 | 0,053853686 | ||
| q | ||||
| r | 0,007663 | 0,053853686 | ||
| s | 0,065134 | 0,256657217 | ||
| t | 0,145594 | 0,404747825 | ||
| u | 0,02682 | 0,14001478 | ||
| v | 0,003831 | 0,030758261 | ||
| w | 0,02682 | 0,14001478 | ||
| x | ||||
| y | 0,019157 | 0,109309921 | ||
| z | ||||
| N= | H= | 4,028921829 |
В ячейку G2 вводим =F2/F$28, а затем размножаем до конца таблицы. В результате этого в столбце G получим значение pi.
В ячейку Н2 вводим =ЕСЛИ(G2=0; 0; -G2*Log(G2;2)), а затем размножаем до конца таблицы. В ячейку G28 вводим Н=.
В ячейку Н28 вставляется формула автосуммы. Затем таблица обрамляется. В результате получается Таблица 1 в которой энтропия информации Н оказывается равной 4,0289218.
5. Строим график дискретной функции pi = pi(х), где х – номер буквы в таблице 1. Для этого сначала переносим необходимые столбцы таблицы на Лист 2. Выделяем диапазон E1:E27, копируем его на Лист 2 в ячейку А1, затем возвращаемся на Лист 1 и копируем диапазон G1:G27, затем, щелкнув на ячейке С1, открываем на вкладке «Главная» меню «Вставить» и выбираем пункт «Вставить значения». Теперь щелкаем на вкладке «Вставка» Гистограмму обычную и щелкаем на кнопке «Далее». Получилась диаграмма.
6. Перестроение диаграммы в порядке возрастания частоты появления букв. Сначала необходимо скопировать таблицу и вставить ее рядом с уже имеющейся (выделяем диапазон В1:С27, копируем и, щелкнув в ячейку E1, вставляем). Скопированную таблицу необходимо пересортировать в порядке возрастания частоты появления букв. Для этого необходимо выделить диапазон Е1:F29 и открыть меню «Данные», выбрать пункт «Сортировка». В открывшемся окне «Сортировка диапазона» щелкаем на треугольнике выпадающего меню «Сортировать по» и выбираем там по «Кол-во», «Затем по» выбираем «Буква» и щелкаем мышью на «ОК. В результате получится таблица 2. Затем строим график так же, как и первый.
Таблица 2
| Буква | Pi |
| j | |
| q | |
| x | |
| z | |
| k | 0,003831 |
| v | 0,003831 |
| p | 0,007663 |
| r | 0,007663 |
| e | 0,019157 |
| y | 0,019157 |
| u | 0,02682 |
| w | 0,02682 |
| h | 0,030651 |
| b | 0,034483 |
| f | 0,038314 |
| n | 0,038314 |
| c | 0,042146 |
| o | 0,042146 |
| g | 0,045977 |
| l | 0,045977 |
| m | 0,049808 |
| s | 0,065134 |
| d | 0,095785 |
| a | 0,103448 |
| i | 0,10728 |
| t | 0,145594 |
Задание для самостоятельной работы:
Используя изученную технологию, провести частотный анализ поэтических текстов по начальной букве своего любимого поэта.
Лабораторная работа № 7 "Определение связи между энтропией информации и количеством слов в поэтическом тексте"
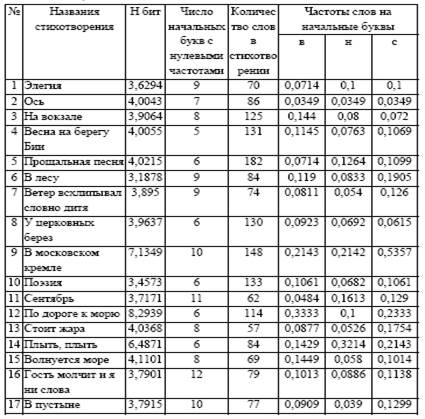
В данной работе необходимо изучить характер зависимости между количественной мерой информации и количеством слов на примере анализа творчества Николая Рубцова.
Задание
Рассчитать коэффициент корреляции для определения степени отличия реальной связи между количественной мерой информации (H) и количеством слов (N) от линейной зависимости.
Методика выполнения работы
1. Запустить MS Excel. Сформировать таблицу соответствия, состоящую из столбцов N и H. Заполнить их, используя данные приложения.
2. На основании сформированной таблицы на плоскости HN построить совокупность точек, отражающую зависимость указанных величин:
· выделить таблицу
· щелкнуть на кнопке Мастер диаграмм
· выбрать точечную диаграмму
· в шаге 3 дать название «Корреляция», ось x – N, ось y – H, убрать галочку. Добавить легенду
3. Чтобы проверить, связаны ли величины H и N линейной (функциональной) зависимостью щелкнуть правой кнопкой мыши на одной из точек диаграммы. В открывшемся меню выбрать пункт – Добавить линию тренда. На вкладке Параметры ставим галочку около слов Показывать уравнение на диаграмме и ОК.
4. Для вычисления коэффициента корреляции на листе с таблицей выделяем свободную ячейку. С помощью Мастера функций в категории Статистические выбрать функцию КОРРЕЛ и ОК. В открывшемся окне в поле Массив1 ввести – А2:А40, в поле Массив2 – В2:В40 (в английской раскладке) и ОК.
Контрольные вопросы:
1. Существует ли между величинами H и N линейная зависимость?
2. Что определяет в творчестве автора коэффициент корреляции?
Приложение