Практическое занятие №3
«Даталогическое проектирование базы данных»
Цель: приобретение практических навыков по проектированию логической модели БД, минимизация избыточности данных на основе принципов нормализации
Время выполнения: 2 часа
Общие теоретические сведения
Часть 1. Построение реляционной схемы
Результатом этапа даталогического (логического) проектирования является логическая схема БД, включающая определение всех информационных единиц и связей, в том числе задание типов, характеристик и имен. Основная задача этого этапа - преобразование ER-диаграммы в реляционную схему.
Получение реляционной схемы из ER-диаграммы:
1. Каждая простая сущность превращается в таблицу (отношение). Имя сущности становится именем таблицы.
2. Каждый атрибут становится возможным столбцом с тем же именем. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам, — не могут. Если атрибут является множественным, то для него строится отдельное отношение.
3. Компоненты уникального идентификатора сущности превращаются в первичный ключ. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, то к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
4. Связи «многие к одному» и «один к одному» становятся внешними ключами. Т.е. создается копия уникального идентификатора с конца связи «один», и соответствующие столбцы составляют внешний ключ.
5. Индексы создаются для первичного ключа (уникальный индекс), а также внешних ключей и тех атрибутов, которые будут часто использоваться в запросах.
6. Если остающиеся внешние ключи все принадлежат одному домену, т. е. имеют общий формат, то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи. Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей.
Пример
Рассмотрим следующую задачу: пусть необходимо обеспечить сбор и обработку данных по результатам сдачи экзаменов и зачетов студентами факультета. Организация данных должна поддерживать:
• выполнение текущего учебного плана;
• формирование ведомостей по отдельным дисциплинам для групп студентов;
• формирование листов зачетных книжек студентов;
• формирование сводной ведомости курса;
• расчет среднего балла по дисциплинам и т. п.
Рассмотрим этап построения даталогической модели (реляционной схемы) на основе имеющейся ER-диаграммы) для решения задачи.
ER-диаграмма рассматриваемой задачи представлена на рис.2.

Рис 2. ER-диаграмма предметной области
На данном этапе проектирования необходимо построить даталогическую модель. В рассматриваемом случае задача этого этапа — преобразование ER-диаграммы в реляционную схему.
Первые шаги преобразования состоят в превращении каждой сущности в отношение (таблицу). Связь типа М:М, которую называют «сущность — связь», тоже превращается в отдельное отношение. Каждое свойство становится атрибутом — столбцом соответствующей таблицы.
После реализации этих шагов получаем реляционную схему, изображенную на рис. 3, где представлены таблицы «Студенты», «Сводная ведомость», «Учебный план» и «Кадровый состав», отображающие соответственно сущности «Студент», «Сводная ведомость», «Дисциплина учебного плана» и «Преподаватель».

Рис. 3. Реляционная схема после первого шага проектирования
Далее необходимо преобразовать связи во внешние ключи. Связь «многие ко многим», реализуемая отношением «Сводная ведомость», должна содержать уникальные идентификаторы сущностей — участников связи. При этом, если для однозначной идентификации студента достаточно добавить в таблицу столбец ID Студент, то однозначная идентификация дисциплины потребует добавления в таблицу столбцов Наименование, Семестр и Форма отчетности. Хранение всей этой информации явно приведет к избыточности данных и их потенциальной противоречивости (например, если при переносе дисциплины на другой семестр обновить только строку таблицы «Учебный план», то содержимое таблицы «Сводная ведомость» станет неактуальным).
Для ликвидации избыточности и потенциальной противоречивости данных добавим в таблицу «Учебный план» столбец ID_План, содержимое которого будет однозначно идентифицировать каждую строку таблицы. Теперь этот новый столбец станет первичным ключом, и одноименный столбец должен быть добавлен в таблицу «Сводная ведомость».
Связь «Читает» предполагает добавление в таблицу «Учебный план» столбца ID_ Преподаватель. Реляционная схема со связями представлена на рис.4

Рис. 4. Реляционная схема со связями
Часть 2. Нормализация таблиц
Данные могут группироваться в таблицы (отношения) разными способами. При проектировании БД в качестве отправной точки может использоваться одно универсальное отношение, в которое включаются все необходимые атрибуты. Оно может содержать все данные, которые предполагается размещать в БД.
В качестве примера рассмотрим универсальное отношение сотрудники, содержащее информацию о сотрудниках предприятия (табл. 1). Таблица 1

При использовании универсального отношения возникают две проблемы:
· избыточность данных;
· потенциальная противоречивость (аномалии).
Под избыточностью понимают повторение данных в разных строках одной таблицы или в разных таблицах БД. Так, для каждого сотрудника отдела 128 повторяются данные «128, Отдел проектирования».
Аномалии – это проблемы, возникающие в данных из-за дефектов проектирования БД.
Существуют три вида аномалий: вставки, удаления и модификации.
Аномалии вставки проявляются при вводе данных в дефектную таблицу. Добавляя информацию о новом сотруднике, мы должны добавить номер и название отдела. Если ввести данные, не соответствующие имеющимся в таблице (например, 42, отдел проектирования), будет не ясно, какая из строк БД содержит правильную информацию.
Аномалии удаления возникают при удалении данных из дефектной схемы. Предположим, что все сотрудники отдела 128 уволились в один и тот же день. После удаления записей этих сотрудников в БД больше не будет ни одной записи, содержащей информацию об отделе 128.
Аномалии модификации возникают при изменении данных дефектной схемы. Предположим, что отдел 128 решили переименовать в отдел передовых технологий. Необходимо изменить соответствующие данные о каждом сотруднике отдела. Если мы пропустим хотя бы одну запись, возникнет аномалия модификации.
Решение перечисленных проблем состоит в разделении данных и связей, что обеспечивается процедурой нормализации. Концепции и методы нормализации были разработаны Э. Ф. Коддом.
Нормализация отношений – это формальный аппарат ограничений на формирование отношений, который позволяет устранить дублирование и потенциальную противоречивость хранимых данных, уменьшает трудозатраты на ведение БД. Процесс нормализации заключается в декомпозиции исходных отношений на более простые отношения. Цель нормализации –устранение избыточности и дублирования информации. В идеале при нормализации надо добиться, чтобы любое значение хранилось в базе в одном экземпляре, причем значение это не должно быть получено расчетным путем из других данных, хранящихся в базе.
Теория нормализации основана на наличии зависимостей между атрибутами отношения.
Основными видами зависимостей являются:
· функциональные;
· многозначные;
· транзитивные.
Базовым является понятие функциональной зависимости, поскольку на его основе формируются определения всех остальных видов зависимостей. Атрибут В функционально зависит от атрибута А, если каждому значению А соответствует в точности одно значение В (ВàA). Это означает, что во всех кортежах с одинаковым значением атрибута А атрибут В будет иметь также одно и то же значение. При этом А и В могут быть составными, то есть состоять из двух и более атрибутов.
Зависимость, при которой каждый неключевой атрибут зависит от всего составного ключа и не зависит от его частей, называется полной функциональной зависимостью. Если атрибут А зависит от атрибута В, а атрибут В зависит от атрибута С (С à В à А), но обратная зависимость отсутствует, то зависимость А от С называется транзитивной.
Многозначная зависимость. Говорят, что один атрибут отношения многозначно определяет другой атрибут того же отношения, если для каждого значения первого атрибута существует множество соответствующих значений второго атрибута. Многозначные зависимости могут быть:
· один-ко-многим (1:М);
· многие-к-одному (М:1);
· многие-ко-многим (М:М).
Каждая ступень процесса нормализации приводит схему отношений в последовательные нормальные формы. Для каждой ступени имеются наборы ограничений. Выделяют следующую последовательность нормальных форм:
· первая нормальная форма (1НФ);
· вторая нормальная форма (2НФ);
· третья нормальная форма (3НФ);
· усиленная 3НФ или нормальная форма Бойса-Кодда (БКНФ);
· четвертая нормальная форма (4НФ);
· пятая нормальная форма (5НФ).
База данных считается нормализованной, если ее таблицы (по крайней мере, большинство таблиц) представлены как минимум в третьей нормальной форме.
Отношение находится в первой нормальной форме (1НФ), когда каждая строка содержит только одно значение для каждого атрибута (столбца), то есть все атрибуты отношения имеют единственное значение (являются атомарными).
В столбце Квалификация ненормализованной табл. 1 содержатся списки значений (С, Java и т. д.). Чтобы привести схему к 1НФ, необходимо разместить в этом столбце атомарные значения. Самый простой способ заключается в выделении по одной строке на каждый элемент квалификации (табл. 2).
Таблица 2

Такое решение далеко от идеального, поскольку порождает очевидную избыточность данных – для каждой комбинации сотрудник-квалификация приходится хранить все характеристики сотрудника.
Отношение находится во второй нормальной форме (2НФ), если оно находится в 1НФ, и каждый неключевой атрибут полностью функционально зависит от всех составляющих первичного ключа. Если атрибут не зависит полностью от первичного ключа, то он внесен ошибочно и должен быть удален. Нормализация производится путем нахождения существующего отношения, к которому относится данный атрибут, или созданием нового отношения, в который атрибут должен быть помещен.
Таблица Квалификации_сотрудников (табл. 2) находится в 1НФ, но не удовлетворяет 2НФ. Первичный ключ должен уникальным образом идентифицировать каждую строку. Единственным вариантом является использование в качестве первичного ключа комбинации Код сотрудника и Квалификация. Это порождает схему: Квалификации_сотрудников (Код сотрудника, ФИО, Должность, Номер отдела, Наименование отдела, Квалификация).
Одной из имеющихся здесь функциональных зависимостей будет:
Код сотрудника, Квалификация à ФИО, Должность, Номер отдела, Наименование отдела.
Но, кроме того, мы также имеем:
Код сотрудникаàФИО, Должность, Номер отдела, Наименование отдела.
Другими словами, можно определить имя, должность и отдел, используя только код сотрудника. Это значит, что указанные атрибуты функционально зависимы только от части первичного ключа, а не от всего первичного ключа. Следовательно, указанная схема не находится в 2НФ.
Для приведения этой схемы в 2НФ необходимо декомпозировать исходное отношение на два, в которых все неключевые атрибуты будут полностью функционально зависеть от ключа: сотрудники (Код сотрудника, ФИО, Должность, Номер отдела, Наименование отдела) и Квалификации_сотрудников (Код сотрудника, Квалификация) (табл. 3-4).
Таблица 3
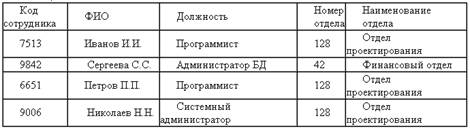
Таблица 4

Отношение находится в третьей нормальной форме (ЗНФ), если оно находится во 2НФ и ни один из его неключевых атрибутов не связан функциональной зависимостью с любым другим неключевым атрибутом. Атрибуты, зависящие от других неключевых атрибутов, нормализуются путем перемещения зависимого атрибута и атрибута, от которого он зависит, в новое отношение.
Формально, для приведения схемы в 3НФ необходимо исключить все транзитивные зависимости. Схема отношения сотрудники (табл. 3) содержит следующие функциональные зависимости:
Код сотрудника àФИО, Должность, Номер отдела, Наименование отдела и
Номер отделаàНаименование отдела
Первичным ключом является Код сотрудника, и все атрибуты полностью функционально зависимы от него (первичный ключ определяется единственным атрибутом). При этом Номер отдела ключом не является.
Функциональная зависимость Код сотрудника à Наименование отдела является транзитивной, поскольку содержит промежуточный шаг (зависимость Номер отдела à Наименование отдела). Для приведения в 3НФ необходимо исключить эту транзитивную зависимость, декомпозируя отношение на два:
сотрудники (Код сотрудника, ФИО, Должность, Номер отдела) и
отделы (Номер отдела, Наименование отдела) (табл. 5-6). Таблица 5
 Таблица 6
Таблица 6

Нормальная форма Бойса-Кодда (БКНФ) является развитием ЗНФ и требует, чтобы в отношении были только такие функциональные зависимости, левая часть которых является потенциальным ключом отношения. Потенциальный ключ представляет собой атрибут (или множество атрибутов), который может быть использован для данного отношения в качестве первичного ключа. Фактически первичный ключ – это один из потенциальных ключей, назначенный в качестве первичного. Детерминантом называется левая часть функциональной зависимости. Отношение находится в БКНФ тогда и только тогда, когда каждый детерминант отношения является потенциальным ключом.
На практике построение 3НФ в большинстве случаев является достаточным и приведением к ней процесс построения реляционной БД заканчивается. Нормальные формы высших порядков (4НФ и 5НФ) представляют больший интерес для теоретических исследований, чем для практики проектирования БД. В них учитываются многозначные зависимости между атрибутами.
Пример
Рассмотрим процедуру приведения таблиц рассмотренного выше примера к НФБК.
Все построенные таблицы (Рис.4) находятся в первой нормальной форме, так как каждый столбец таблицы неделим и в рамках одной таблицы нет столбцов с одинаковыми по смыслу значениями.
Ø Таблица «Сводная ведомость» через столбцы ID Студент и ID План связывает информацию о студенте с информацией о конкретной дисциплине и фиксирует оценку, полученную студентом, Оценка и дата сдачи экзамена (зачета) однозначно зависят от содержимого столбцов ID Студент и ID План, которые представляют собой составной первичный ключ. Таким образом, все таблицы имеют первичные ключи, которые однозначно определяют строки и не избыточны, и можно говорить о том, что таблицы находятся во второй нормальной форме.
Ø Рассмотрим подробнее таблицу «Учебный план», которая содержит перечень дисциплин текущего учебного плана. Первичным ключом таблицы служит столбец ID План, который однозначно характеризует каждую дисциплину учебного плана с точностью до семестра, т. е. для дисциплин, протяженность изучения которых более одного семестра, в таблице будет отведено столько строк, сколько семестров длится изучение дисциплины. Тогда хранение наименований дисциплин в таблице «Учебный план» становится избыточным: например, если изучение английского языка длится шесть семестров, то наименование «Английский язык» будет повторено в шести записях и есть вероятность сделать шесть различных ошибок при вводе одного и того же наименования. Чтобы избежать этого, проведем декомпозицию отношения «Учебный план», выделив наименования дисциплин в отдельное отношение. В результате получим дополнительную таблицу «Дисциплины» со столбцами ID Дисциплина и Наименование, а столбец Наименование в таблице «Учебный план» заменим столбцом Дисциплина, сформировав тем самым вторичный ключ, связывающий новую таблицу с таблицей «Учебный план».
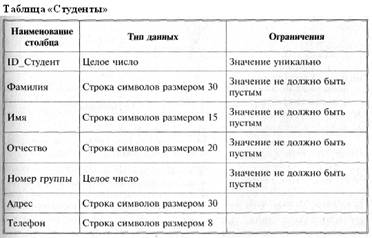
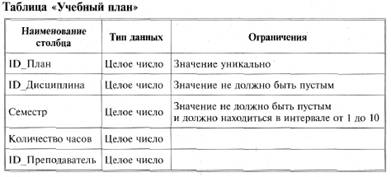
Теперь можно говорить о базе данных «Сессия», реляционная схема которой представлена следующими пятью таблицами:
• «Студенты» — содержит по одной строке для каждого из студентов;
• «Учебный план» — содержит по одной строке для отдельной дисциплины отдельного семестра;
• «Дисциплины» — содержит по одной строке для наименования дисциплины;
• «Сводная ведомость» — содержит по одной строке для каждого результата сдачи отдельным студентом отдельной дисциплины;
• «Кадровый состав» — содержит по одной строке для каждого из преподавателей.
На рис. 2 в графической форме изображены перечисленные таблицы, их столбцы, первичные и внешние ключи. Задание первичных и внешних ключей сопровождается построением дополнительных структур — индексов, обеспечивающих быстрый доступ к данным через значение ключа.

Рис. 2. Структура базы данных «Сессия»
Все таблицы базы данных «Сессия» находятся в третьей нормальной форме:
• каждый столбец таблицы неделим, и в рамках одной таблицы нет столбцов с одинаковыми по смыслу значениями (1НФ);
• первичные ключи однозначно определяют запись и не избыточны, все поля каждой из таблиц зависят от ее первичного ключа (2НФ);
• значение любого поля, не входящего в первичный ключ, не зависит от значения другого поля, тоже не входящего в первичный ключ (ЗНФ).
Следующий этап — определение доменов (типов) данных, хранящихся в столбцах таблиц. Параллельно с заданием типа необходимо сформулировать ограничения целостности, связанные с типом, — перечень допустимых значений типа.
Исходя из особенностей данных и их функционального назначения, требуется задать способ представления и границы возможных изменений для каждого из столбцов таблиц. При этом необходимо ответить на вопрос: данные каких типов должны храниться в столбцах и какова их максимальная длина (например, если в столбце предполагается хранить процентные значения, то достаточно будет целого типа данных длиной 1 байт, так как диапазон возможных значений — от 0 до 255; если для данных столбца выбирается тип «строка символов», то желательно указать максимальный размер данных столбца и т. п.).
Далее, в каждой таблице должны быть выделены столбцы, которые обязательно должны быть заполнены при создании отдельной строки таблицы. Задание такого ограничения целостности не позволит, например, ввести в таблицу «Студенты» строку, в которой не указан номер группы. Если подобные ограничения целостности не будут заданы, в таблице могут появиться строки, которые не будут учтены при выполнении функций по обработке данных: появление в таблице «Студенты» строки без номера группы приведет к ошибке при формировании ведомости.
Следующий важный момент — задание для столбцов значений по умолчанию. Значение по умолчанию впоследствии будет автоматически вводиться в указанный столбец для каждой строки таблицы. Например, в столбец Дата сдачи таблицы «Сводная ведомость» при заполнении очередной строки может автоматически заноситься текущая дата.
Ниже, на рис. 3 представлены таблицы базы данных «Сессия» с типами данных столбцов и предлагаемыми ограничениями целостности.



ЗАДАНИЕ НА практическую РАБОТУ:
1. Изучите методические указания к практической работе.
2. Выполните упражнения:
· из концептуальной ER- модели для своей задачи получите реляционную схему
· выполните нормализацию отношений
3. Оформите отчет по практической работе, описав выполнение упражнений и дав краткие ответы на контрольные вопросы.
Содержание отчета:
1. Название и цель работы
2. Выполненные упражнения
3. Ответы на контрольные вопросы
4. Выводы по работе
Контрольные вопросы:
1. Основные этапы получения реляционной схемы из ER-диаграммы
2. С чем связаны избыточность данных и потенциальная противоречивость (аномалии)? Дайте определение данным явлениям.
3. В чем заключается процесс нормализации?
4. Дать определение 1, 2, 3 НФ