обучение
Гаврилюк Я.Д.
СУБД ACCESS
Учебно-практическое пособие
для студентов всех специальностей
 |
www.msta.ru
Москва - 2008
УДК 681.3.06
© Гаврилюк Я.Д. СУБД ACCESS. Учебно-практическое пособие.
– М.: МГУТУ, 2008.
Данный модуль предназначен, как одна из составных частей, для изучения дисциплин: «Информатика», «Базы данных», «Информационное обеспечение товароведения (товародвижения) и экспертизы товаров», «Информационные технологии управления», «Информационные системы в экономике», «Теория систем и системный анализ», «Системы искусственного интеллекта».
Автор: Гаврилюк Ярослав Дмитриевич
Рецензенты: проф. МГУПБТ Сапфиров С.Г.,
проф. МГУПБТ, д.т.н., начальник управления
информационных технологий Бородин А.В.
Редактор: Свешникова Н.И.
© Московский государственный университет технологий и управления, 2008.
109004, Москва, Земляной вал, 73
СОДЕРЖАНИЕ
Стр.
Введение 4
Глава 1 БАЗЫДАННЫХ 7
Классификация баз данных 7
Реляционная модель данных 7
Проектирование реляционных баз данных 9
Нормализация данных 10
Связывание таблиц 12
Типы связей между таблицами 12
Формирование запросов к базе данных 13
Оператор выбора SELECT 15
Тестовые задания к главе 1 16
Глава 2 СУБД ACCESS 18
Запуск программы 18
Элементы окна Microsoft Access 19
Создание базы данных с помощью мастера 23
Технология создания таблиц базы данных 28
Технология создания схемы данных 32
Технология построения многотабличной формы 35
Технология ввода данных 37
Тестовые задания к главе 2 39
Глава 3 Решение тренировочных заданий по практическому созданию баз данных 40
Задание № 1. Технология создания многотабличных баз данных на тему "Microsoft Access - универсальная система управления базами данных" 40
Задание № 2. Технология создания многотабличных баз данных на тему «Вычисления в Access 2000» 47
Тестовые задания к главе 3 54
Дополнительные тестовые задания 55
Ответы на тестовые задания 56
Список рекомендуемой литературы 57
Словарь основных понятий 58
ВВЕДЕНИЕ
В настоящее время основными направлениями использования средств вычислительной техники и программных продуктов для информационного обеспечения товароведения и экспертизы товаров являются следующие:
· использование существующих автоматизированных информационных систем и их конфигурирования с учетом определенного типа предприятия и класса решаемых задач;
· разработка новых информационных систем для решения конкретных задач.
Информационной системой называется программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
· надежное хранение информации в памяти компьютера
· выполнение специфических операций преобразования информации
· предоставление пользователю удобного интерфейса.
Эти задачи могут быть решены с помощью универсальной системы автоматизации деятельности предприятия 1С:Предприятие. Эта система может быть использована для автоматизации самых различных аспектов деятельности предприятия, таких, например, как оперативный учет товарных и материальных средств, учет складских и торговых операций, обслуживания отдела кадров, расчетов заработной платы и др.
Отличительной особенностью системы 1С:Предприятие является ее конфигурируемость.
Конфигурация представляет собой модель предметной области и создается штатными средствами системы. Средства конфигурирования позволяют описать структуры данных, характеризующие объекты предметной области, и алгоритмы их обработки с целью отражения особенностей учета.
Для описания алгоритмов решения прикладной задачи используется специальный предметно-ориентированный язык программирования, встроенный в систему 1С:Предприятие. Описание языка программирования 1С:Предприятие занимает примерно 900 страниц. Этот язык предназначен для специалистов, выполняющих кофигурирование системы для решения конкретной задачи автоматизации учета.
Одним из базовых объектов системы являются документы, которые предназначены для хранения основной информации о событиях, происходящих на складе, отделе, предприятии - объектах предметной области. Типовыми примерами документов являются такие, например, как "Приходная накладная", "Расходная накладная", "Накладная на внутреннее перемещение", "Платежное поручение", "Счет", "Протокол испытаний", акты экспертиз и др.
Для ввода информации используются экранные формы. Каждый документ отражает определенный тип событий. Структура документа и свойства событий описываются в конфигурации.
Конфигурация может быть поставлена фирмой "1С". Система 1С:Предприятие вместе с конфигурацией является готовым программным продуктом, ориентированным на определенные классы решаемых задач для конкретной предметной области.
Очевидно, недостатком системы 1С:Предприятие является ее некоторая консервативность, обусловленная тем, что модули системы и алгоритмы должны настраиваться в процессе ее конфигурации специалистами фирмы "1С". Следует также иметь ввиду, что изменение форм отчетности и условий функционирования предприятия каждый раз вызывает необходимость реконфигурирования системы 1С:Предприятие.
Другим более эффективным способом решения задач, которые сформулированы в определении информационной системы, являются базы данных (БД) и системы управления базами данных (СУБД).
База данных - это именованная совокупность структурированных данных, отражающая состояние объектов и их отношений в конкретной предметной области.
В узком смысле база данных представляет собой набор данных о конкретном объекте, организованных определенным образом.
В широком смысле база данных представляет собой совокупность сведений о конкретных объектах.
Целью базы данных является необходимость упорядочить фактические данные по различным признакам, так чтобы иметь возможность быстро извлекать требуемую информацию.
Как правило, с одной базой данных может работать несколько пользователей. Программы, с помощью которых пользователи работают с базой данных, называются приложениями.
Для работы с одной базой данных может использоваться несколько приложений. Например, если база данных моделирует предприятие, то одно приложение может обслуживать отдел складского учета товаров, другое приложение может учитывать движение материальных ценностей, третье приложение может обслуживать планирование технологических операций.
Создание базы данных, ее поддержка, управление, доступ пользователя к самим данным осуществляется с помощью СУБД.
СУБД представляет собой программные средства для создания, ведения и совместного использования базы данных многими пользователями.
СУБД обеспечивает корректную работу нескольких приложений с единой базой данных, так чтобы каждое приложение учитывало все изменения, вносимые в базу данных другими приложениями.
Среди наиболее доступных и широко известных СУБД следует отметить СУБД Microsoft Access 2000, которая объединяет сведения из разных источников в одной реляционной базе данных.
Создаваемые с помощью Microsoft Access 2000 формы, запросы и отчеты позволяют быстро и эффективно обновлять данные, получать ответы на вопросы, осуществлять поиск нужных данных, анализировать данные, выводить на печать структурированные данные в удобном для пользователя формате утвержденных форм и документов (различных накладных, платежных поручений и др.), печатать отчеты и диаграммы.
ГЛАВА 1
БАЗЫДАННЫХ
Классификация баз данных
В зависимости от принципов обработки данных базы данных делятся на следующие:
· централизованные базы данных (ЦБД)
· распределенные базы данных (РБД).
· В централизованной БД база данных размещается на одном компьютере, который может иметь или не иметь поддержки сети.
· Если компьютер не имеет поддержки сети, то в этом случае может быть реализован только локальный доступ.
· Если же компьютер включен в локальную сеть, то в этом случае может быть реализован централизованный доступ.
В настоящее время наиболее широко применяются централизованные базы данных с централизованным доступом. При такой технологии возможны два способа обработки данных:
· Файл-сервер
· Клиент-сервер
Для реализации технологии файл-сервер необходимо, чтобы один из компьютеров сети функционировал в качестве сервера, на котором хранятся файлы централизованной базы данных.
В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется обработка данных. По завершении работы с базой данных пользователи копируют файлы с обработанными данными обратно на сервер.
Возможности пользователей вычислительной сети определятся их правами доступа. При регистрации пользователя на рабочей станции возможны два уровня доступа к данным: администратор и рядовой пользователь.
Администратор получает возможность работать не только со всеми командами, доступными рядовому пользователю, но и с командами, которые определяют его привилегированное положение в сети и доступны только ему.
Рядовой пользователь получает только те права доступа, которые определяет администратор при создании пользователя или группы пользователей.
Для того чтобы войти в сеть и работать с сетевыми ресурсами. пользователь должен знать свой логин (сетевое имя) и пароль. Логин и пароль для пользователя устанавливает администратор. Пароль пользователя должен быть уникальным.
Основными недостатками технологии файл-сервер являются следующие:
· Между рабочими станциями пользователей и сервером по сети передаются большие объемы информации.
· При одновременном обращении к одним и тем же данным пользователи вынуждены дожидаться освобождения этих данных.
Технология клиент-сервер реализуется следующим образом.
Центральный сервер обеспечивает не только хранение файлов базы данных, но и выполняет основную часть обработки данных. Пользователи обращаются к центральному серверу с запросами, которые формулируют с помощью специального языка структурированных запросов - SQL. Запрос описывает действия и список задач, которые должен выполнить сервер. Запросы принимаются сервером и инициируют процессы обработки данных. В соответствии с полученными инструкциями сервер выполняет необходимые действия. В ответ пользователь получает по сети только обработанный набор данных.
При такой технологии между пользователем и сервером передается не весь объем данных, а только данные, необходимые пользователю.
Архитектура централизованной базы данных с централизованным доступом по технологии клиент-сервер имеет ряд преимуществ по сравнению с технологией файл-сервер, а именно:
По сети передается не весь объем информации, а только данные, необходимые пользователю.
Позволяет избежать конфликтов изменений одних и тех же данных множеством пользователей.
Организует согласованное изменение данных множеством пользователей, поддерживая автоматически целостность данных.
Недостатком этой технологии являются высокие требования к характеристикам центрального сервера.
Распределенная база данных может состоять из нескольких частей. хранимых в различных ЭВМ вычислительной сети. Для работы с такими базами данных используют системы управления распределенными базами данных (СУРБД).
В зависимости от характера информационных ресурсов, содержащихся в базе данных, базы данных делятся на документальные и фактографические.
Документальные базы данных представляют собой информационно-поисковые системы документов, отсортированных по какому-либо признаку.
Фактографические базы данных предназначены для решения задач обработки данных - задач, связанных с вводом, хранением, сортировкой, отбором по заданным критериям и группировкой записей данных однородной структуры. Характерной особенностью фактографических баз данных является то, что они содержат фактические сведения, представленные в виде совокупностей форматированных записей данных.
Реляционная модель данных
Центральным понятием в области баз данных является модель данных.
Модель представляет собой такое структурированное представление конкретных данных о свойствах объекта, которое позволяет разработчикам баз данных трактовать их как сведения, содержащие не только данные, но и взаимосвязь между ними.
В настоящее время среди различных моделей данных наиболее перспективной является реляционная модель данных, которая фактически является монополистом на рынке баз данных.
Реляционная модель данных была предложена американским математиком, сотрудником фирмы IBM Э. Коддом в 1970 году.
Теоретической основой реляционной модели данных стала теория отношений. Основной структурой данных в этой модели является отношение. Э. Кодд показал, что любое представление данных можно свести к совокупности двумерных таблиц особого вида, называемых отношением. В английской терминологии relation - это отношение. Поэтому модель данных получила название реляционной.
Каждый элемент отношения может быть представлен в формате
A[i,j],
где A - элемент данных, i - строка отношения, j - номер атрибута отношения
Количество атрибутов в отношении определяет степень этого отношения.
Отношение степени 1 называется унарным, отношение степени 2 - бинарным, отношение степени 3 - тернарным, а отношение степени n -
n-арным.
Множество всех значений A[i,j] при i = const и всех возможных j образует кортеж или строку таблицы.
Множество всех кортежей отношения образует тело отношения.
Реляционной считается такая база данных, в которой все данные представлены в виде двумерных таблиц и все операции над базой сводятся к манипуляциям с таблицами или отношениями (в терминологии баз данных отношение - это таблица или сущность).
Реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
· каждый элемент таблицы является минимальным элементом данных;
· все элементы в пределах одного столбца имеют одинаковый тип данных (текстовый, числовой, логический и т. д.);
· все столбцы должны иметь уникальное имя;
· в таблице нет совпадающих строк;
· порядок следования столбцов и строк может быть произвольным (см., например, таблицу Заказы на рис. 1.1).
 |
Рис. 1.1. Таблица Заказы
Каждый из атрибутов расположен в отдельном столбце. Каждая строка представляет собой набор атрибутов, описывающий конкретный экземпляр объекта - Заказы.
Каждое поле таблицы должно являться отдельным атомарным значением для конкретной предметной области. Это атомарное значение не должно разлагаться на более простые составляющие.
В некоторых случаях в качестве атомарного значения могут рассматриваться агрегированные объекты. Например, фамилия, имя и отчество или адрес и его атрибуты.
Между реляционными таблицами должны быть установлены связи. Связь между таблицами характеризует способ, которым информация одной таблицы связана с информацией в другой.
С этой целью необходимо установить идентификатор или ключ, который бы позволил уникально опознать любую строку таблицы.
Ключом называется множество атрибутов, задание значений которых позволяет однозначно определить значения остальных атрибутов таблицы.
В качестве ключа может выступать учебный шифр студента (номер зачетки), номер группы, код заказа, код клиента и др.
Один из возможных ключей отношения может быть выбран в качестве первичного ключа.
Проектирование реляционных баз данных
Реляционная база данных представляет собой совокупность двумерных реляционных таблиц, в которых хранится вся информация о конкретной предметной области и все операции над базой данных сводятся к манипуляциям. Кроме таблиц в базе данных могут хранится и другие объекты, а именно: экранные формы, отчеты, представления и др.
Таблицы реляционной базы данных должны быть взаимосвязаны между собой. В каждой связи одно отношение может выступать как главное, а другое - как подчиненное. Для поддержки этих отношений используются ключи.
Реляционная таблица состоит из строк (записей) и столбцов (полей) и имеет уникальное в пределах базы данных имя. Каждая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец или их комбинация называется первичным ключом. В таблице Заказы первичным ключом является комбинация столбцов Код клиента и Код заказа (один клиент может иметь несколько заказов). Первичный ключ должен содержать уникальные непустые значения.
Таблица отражает сущность (класс объектов) реального мира, а каждая ее строка - конкретный экземпляр этой сущности. Так, например, таблица Заказы (см. рис.) содержит всю необходимую информацию о регистрации и исполнении заказов.
Целью проектирования базы данных является сокращение избыточности хранимых данных. База данных должна обеспечить оптимальное использование оперативной и дисковой памяти, возможность изменения данных и обеспечить целостность данных.
К проекту реляционной базы данных предъявляются следующие требования.
· Каждая таблица должна иметь уникальное в пределах базы данных имя.
· Все строки таблицы должны быть однотипны.
· Каждая строка таблицы должна отличаться от любой другой строки хотя бы одним значением.
· Каждая строка таблицы не должна зависеть от значений, хранимых в другой строке.
· Каждому столбцу таблицы должно быть присвоено уникальное в пределах базы данных имя.
· Разрешается свободно обращаться к любой строке или столбцу.
Нормализация данных
Нормализацией называется процесс приведения структур данных в состояние, обеспечивающее лучшие условия выборки, включения, изменения и удаления данных. Это достигается разбиением одной большой таблицы на две или более мелких. Конечной целью нормализации является получение такого проекта базы данных, в котором каждый факт появляется лишь в одном месте.
Таблица, в которую включены все интересующие атрибуты, называется универсальным отношением. При использовании универсального отношения база данных будет состоять лишь из одной таблицы, в которой будет хранится вся информация о рассматриваемом объекте.
Таблицу, содержащую в одном или нескольких полях большое количество повторяющихся данных, можно разделить на две или более связанных таблиц. Такой способ, позволяющий более эффективно хранить данные, называют нормализацией таблиц.
В некоторых СУБД, например Access, предусмотрен мастер анализа таблиц, который позволяет нормализовать таблицы базы данных. При использовании мастера пользователь имеет возможность самостоятельно определить создаваемые таблицы или позволить мастеру провести нормализацию таблиц.
Мастер анализа таблиц преобразует таблицу, содержащую повторяющиеся данные, в набор связанных таблиц, где уже нет повторений. Это повышает эффективность работы с базой данных и уменьшает ее размер. После создания набора таблиц данные по-прежнему можно просматривать и обрабатывать вместе, создав для этого запрос.
Универсальное отношение порождает ряд проблем.
· Избыточность
· Аномалии обновления (потенциальная противоречивость)
· Аномалии включения
· Аномалии удаления
Большая часть проблем исчезнет, если данные из универсальной таблицы разнести в несколько более мелких таблиц. Эту задачу можно решить путем нормализации.
Процесс нормализации состоит из нескольких этапов. На каждом из этапов изменяют структуру данных так, чтобы она удовлетворяла определенным критериям - требованиям нормальной формы.
Нормализация представляет собой последовательное изменение структуры данных в соответствии с требованиями нормальных форм.
Всего существует шесть нормальных форм. Теория нормализации опирается на довольно сложный математический аппарат реляционной алгебры, изложение которого вытекает за рамки данного пособия.
Дадим определение первых трех нормальных форм.
1. Таблица находится в первой нормальной форме, если ни одно поле строки не содержит более одного значения и любое ключевое поле не является пустым. Как следует из определения, любая таблица реляционной базы данных автоматически удовлетворяет требованиям первой нормальной формы.
2. Таблица находится во второй нормальной форме, если она удовлетворяет требованиям первой нормальной формы, и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом. Как следует из этого определения, необходимо чтобы только первичный ключ однозначно идентифицировал значения полей в любом столбце и в то же время значения полей в столбцах не зависели от любой части составного ключа. Если первичный ключ состоит из одного столбца, то это требование удовлетворяется автоматически. Если же первичный ключ является составным, то есть состоит из двух и более столбцов, то такая таблица не обязательно будет находится во второй нормальной форме. если таблица не удовлетворяет требованиям второй нормальной формы, то она должна быть разбита на две или более таблиц так, чтобы первичный ключ однозначно идентифицировал значение в любом столбце.
3. Таблица находится в третьей нормальной форме тогда и только тогда, когда она удовлетворяет требованиям второй нормальной формы и ни одно из ее не ключевых полей не зависит функционально от любого не ключевого поля. Любое не ключевое поле должно зависеть только от первичного ключа.
Практически таблицы реляционной базы данных не обязательно должны удовлетворять всем требованиям нормальных форм.
Автор книги "Эффективная работа с Microsoft Access 2000" Д. Вейскас считает, что практически таблицы реляционной базы данных должны удовлетворять следующим требованиям:
· Каждое поле таблицы должно быть уникальным.
· Каждая таблица должна иметь первичный ключ, который может состоять из одного или нескольких полей.
· Для каждого значения первичного ключа должно быть одно и только одно значение любого из столбцов данных и это значение должно относится к объекту таблицы.
· Должна иметься возможность изменять значения любого не входящего в первичный ключ поля и это не должно повлечь за собой изменения другого поля.
Связывание таблиц
Пока данные хранятся в универсальном отношении можно сразу получить всю необходимую информацию. После нормализации доступ к данным усложняется, так как вместо одной таблицы имеется набор множества таблиц. Чтобы выбрать необходимую информацию необходимо рассмотреть несколько таблиц.
Для связывания данных в таблицах необходимо использовать ключи. Взаимосвязь таблиц поддерживается внешними ключами. Внешний ключ создается в таблице, поля которой ссылаются на строки главной таблицы. Каждому значению внешнего ключа должно быть сопоставлено значение первичного ключа. В отличие от первичного, внешний ключ не должен быть уникальным. В зависимой таблице могут быть строки, имеющие одинаковые значения внешнего ключа.
Группа связанных таблиц называется схемой данных. Пример схемы данных показан на рис..
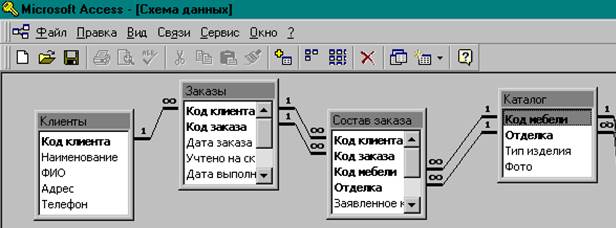 |
Рис. 1.2. Фрагмент схемы данных базы данных Товарная база
Типы связей между таблицами
Тип связи определяет правила сопоставления строк между двумя таблицами. Существуют следующие виды связей или отношений.
Один - к - одному (1:1). Такое отношение означает, что каждой строке первой таблицы соответствует только одна строка во второй таблице и, наоборот, каждой строке второй таблицы соответствует только одна строка в первой таблице. Таблицы. связанные отношением один к одному можно объединить в одну общую таблицу, состоящую из полей обоих таблиц. Отношение один к одному может использоваться для разделения таблиц, состоящих из большого числа полей. Такое разбиение может потребоваться, если некоторые поля таблицы содержат конфиденциальную информацию или требуется создать условия для ускоренного просмотра данных.
Один - ко - многим (1:оо). Такая связь определяет отношение между таблицами, когда одна из них является главной, а другая подчиненной. При этом каждой строке главной таблицы может соответствовать несколько строк в подчиненной таблице, а каждой строке в подчиненной таблице соответствует только одна в главной таблице. Примером такого отношения является связь между таблицами Клиенты и Заказы, устанавливаемая между полями Код клиента и Код клиента (см., например, схему данных базы данных Товарная база). В отношении один ‑ ко ‑ многим главной таблицей является таблица, которая содержит первичный ключ, который составляет часть один в отношении один ‑ ко ‑ многим (Код клиента в таблице Клиенты). Каждый клиент может иметь или один заказ, или несколько заказов, или не иметь их совсем. Каждый заказ в подчиненной таблице Заказы должен принадлежать только одному клиенту, разместившему этот заказ.
Многие - ко - многим. При такой связи каждой строке первой таблицы может соответствовать несколько строк во второй таблице и наоборот. Примером такой связи является связь между таблицами Заказы и Каталог. Один заказ может содержать много моделей мебели и каждая конкретная модель может быть включена во множество заказов. Такая связь может быть реализована только через третью таблицу, с которой исходные таблицы будут иметь связи один ‑ ко ‑ многим.
Для рассматриваемого примера такой таблицей является таблица Состав заказа, которая имеет внешние ключи, образованные из составных первичных ключей таблиц Заказы и Каталог (см. схему данных на рис).
Формирование запросов к базе данных
Доступ к данным осуществляется с помощью запросов к базе данных. Эти запросы формулируются на стандартном языке запросов. Для большинства СУБД таким языком является структурированный язык запросов -Structured Query Language (SQL).
Его появление и развитие связано с созданием теории реляционных баз данных. Первая версия языка была разработана в 1970 году фирмой IBM.
За прошедшие с момента появления этого языка годы SQL претерпел существенные изменения и стал более гибким. Вследствие конкуренции на рынке программных продуктов многие фирмы создавали различные модификации и диалекты языка. Эта ситуация негативно отражалась на совместимости программных продуктов, что и явилось объективной необходимостью стандартизации языков доступа к данным, применяемых в различных СУБД. В 1992 году американским национальным институтом стандартов (ANSI) был разработан стандарт языка, названный ANSI SQL-92.
Действующим в настоящее время стандартом языка SQL для большинства реляционных СУБД является принятая Американским национальным институтом стандартов (ANSI) версия SQL 3.
Однако производители СУБД продолжают модернизировать и улучшать возможности языка доступа к данным. Так, например, фирма Microsoft разработала свою версию языка доступа к данным, назвав его Transact-SQL. Этот язык, удовлетворяя требованиям стандарта ANSI SQL-92, предлагает ряд дополнительных возможностей для более эффективного доступа к данным. Transact-SQL и используется для доступа к данным в SQL Server 7.0.
Язык SQL имеет унифицированный набор инструкций. Он также имеет графическую версию - это Query-By Example (QBE). Используя специальный бланк запроса QBE, запросы формулируются посредством графического представления.
Язык SQL не является языком программирования в традиционном понимании. Он не содержит операторы, управляющие ходом выполнения программы. Он содержит только набор стандартных операторов доступа к данным, хранящимся в базе данных. На нем формулируются только запросы к базе данных. С помощью языка SQL можно сформулировать, что необходимо получить в базе данных. Кроме оператора выбора SELECT, язык SQL содержит операторы определения и администрирования данных, операторы манипулирования данными и другие средства.
Наиболее важные операторы, которые входят в стандарт ANSI SQL, приведены в таблице 1.1
Таблица 1.1
| Оператор | Действие |
| Оператор выбора SELECT | |
| SELECT | Оператор, формирующий в соответствии с SQL-запросом результирующее отношение |
| Операторы определения данных | |
| CREATE TABLE | Создает новую |
| DROP TABLE | Удаляет таблицу из базы данных |
| ALTER TABLE | Изменяет структуру существующей таблицы |
| CREATE VIEW | Создает виртуальную таблицу, соответствующую SQL-запросу |
| DROP VIEW | Удаляет ранее созданное представление |
| ALTER VIEW | Изменяет ранее созданное представление |
| CREATE INDEX | Создает индекс для обеспечения быстрого доступа |
| DROP INDEX | Удаляет ранее созданный индекс |
| Продолжение таблицы 1.1 | |
| Операторы манипулирования данными | |
| DELETE | Удаляет в соответствии с условиями фильтрации строки из таблицы |
| INSERT | Вставляет строку в базовую таблицу |
| UPDATE | Обновляет в соответствии с условиями значения одного или нескольких столбцов |
| Операторы администрирования данных | |
| ALTER PASSWORD | Изменить пароль для доступа к базе данных |
| CREATE DATEBASE | Создать новую базу данных |
| DROP DATEBASE | Удалить существующую базу данных |
| GRANT | Предоставить права доступа на ряд действий с объектом базы данных |
| REVOKE | Лишить прав доступа к некоторому объекту |
Оператор выбора SELECT
Одним из основных инструментов обработки данных в СУБД является выборка данных с помощью запросов. Запрос строится на основе одной или нескольких таблиц. Запрос позволяет выбрать необходимые данные из одной или нескольких таблиц, произвести вычисления и получить результат в виде таблицы. Через запрос можно производить обновление данных в таблицах, создать новую таблицу, используя данные из существующих объектов базы данных. Результатом запроса на выборку является таблица.
Ключевое слово SELECT сообщает СУБД, что эта команда - запрос.
Все запросы начинаются этим словом с последующим пробелом.
Синтаксис оператора (команды) выбора SELECT имеет вид:
SELECT [ALL / DISTINCT] (<список полей>/*)
FROM (<список таблиц>)
[WHERE <предикат - условие выборки или соединения>]
[ GROUP BY < список полей группировки>]
[ HEVING < предикат - условие для группы>]
[ ORDER BY < список полей, определяющих порядок сортировки>]
Звездочка в операторе SELECT означает выбор всех столбцов из таблицы.
Ключевое слово ALL означает, что результат выборки включает все строки, возвращаемые запросом. Указание параметра ALL не является обязательным, так как он включается в конструкцию оператора выбора SELECT по умолчанию.
Ключевое слово DISTINCT позволяет исключить из результата выборки повторяющиеся строки и тем самым обеспечить уникальность каждой строки результата. Если параметр DISTINCT не указывается, то будет использоваться ALL
Раздел FROM должен быть представлен в каждом запросе. В этом разделе FROM указываются таблицы и представления, из которых будет производиться выборка данных.
Раздел WHERE предназначен для ограничения количества строк, включаемых в результат выборки в соответствии с логическим условием.
В выражении условий ключевого слова WHERE могут использоваться следующие основные предикаты:
· Предикаты сравнения (=, < >, >, <, >=, <=), имеющие традиционный смысл.
· Предикат Between A and B. Предикат принимает значение "истина", когда сравниваемое значение попадает в диапазон А-В, включая его границы.
· Предикат Not Between A and B. Предикат истинен тогда, когда сравниваемое значение не попадает в диапазон А-В, включая его границы.
· Предикат вхождения в множество IN (множество). Предикат принимает значение "истина", когда сравниваемое значение входит в множество, которое может быть задано простым перечислением. Существует также предикат NOT IN (множество), который принимает значение "истина", когда сравниваемое значение не входит в заданное множество.
· Предикаты сравнения с образцом LIKE и NOT LIKE. Предикат сравнения LIKE принимает значение "истина", когда сравниваемое значение соответствует заданному шаблону, в противном случае этот предикат принимает значение "ложь".
· Предикат NOT LIKE имеет противоположный смысл.
Тестовые задания к главе 1
1.1. Что означает SQL?
A. Стандартный язык запросов для работы с реляционными базами данных.
B. Программа.
C. Алгоритмический язык для работы с базой данных.
1.2. Что такое QBE?
A. Диалоговое окно базы данных.
B. Язык программирования.
C. Графическая версия языка SQL, бланк запроса по образцу.
1.3. Что является результатом выполнения запроса
SELECT КодКлинта, КодЗаказа
FROM Клиенты;
A. Набор данных
B. Таблица с двумя столбцами.
C. Таблица с двумя столбцами КодКлинта и КодЗаказа, выбранными из исходной таблицы Клиенты
1.4. Что является результатом выполнения запроса
SELECT *
FROM Заказы
WHERE Город = ”Москва”
A. Таблица, в которой выбраны все столбцы исходной таблицы Заказы итестроки в которых поле Город имеет значение Москва.
B. Таблица из одного столбца
C. Таблица, в которой имеются только те строки, поле Город в которых имеет значение Москва.
1.5 Что является результатом выполнения запроса
SELECT КодКлинта, КодЗаказа
FROM Заказы
WHERE Город = ”Москва”
AND Стоимость >= 1000
A. Таблица, в которой выбраны два столбца исходной таблицы Заказы итестроки в которых поле Город имеет значение Москва.
B. Таблица из 2-х столбцов КодКлинта и КодЗаказа, в которой отражены заказы стоимостью не менее 1000, рамещенные клиентами из Москвы.
C. Таблица, в которой имеются только те строки, поле Город в которых имеет значение Москва.
ГЛАВА 2
СУБД ACCESS
Запуск программы
Чтобы начать знакомство с СУБД ACCESS, необходимо запустить программу Microsoft Access из Windows 98 или Windows 2000 любым традиционным способом. Например, используя меню Пуск, выберите команду Программы, а затем активизируйте команду Microsoft Access.
После запуска программы на экране появляются окно приложения, а также диалоговое окно приглашения Microsoft Access (рис. 2.1). Как видно из рисунка, пользователю предлагается выбрать один из следующих вариантов продолжения работы: создание пустой базы данных, создание базы данных с помощью мастера или открыть одну из существующих на дисках компьютера баз данных. Для продолжения работы выберите соответ