□ Признак команды
□ Время гола
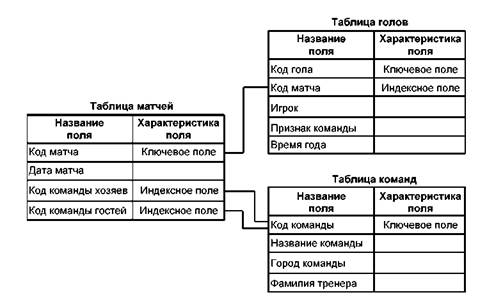
Таблицы связаны по полю "Код матча", которое для таблицы матча имеет уникальное значение. Чтобы обеспечить уникальность записей таблицы голов, в нее введено ключевое поле "Код гола".
Третья нормальная форма
Требования третьей нормальной формы:
П таблица должна удовлетворять требованиям второй нормальной формы;
□ ни одно из не ключевых полей не должно однозначно идентифицироваться
значением другого не ключевого поля (полей).
Приведение таблицы к третьей нормальной форме предполагает выделение в отдельную таблицу (таблицы) тех полей, которые не зависят от ключа. В таблице матчей такими являются поля с фамилиями тренеров команд, которые однозначно определяются значениями названия и города команды. (Предполагается,
50
Часть I. Основы работы с базами данных
что в течение сезона у команды тренер не меняется, на практике это часто не выполняется, но не относится к сути рассматриваемого вопроса.) Разобьем таблицу матчей на две таблицы: одну с данными о матчах и вторую — с данными о командах. Их структура будет такой:
Таблица матчей:
□ Код матча (уникальный ключ)
□ Дата матча
□ Код команды хозяев
□ Код команды гостей Таблица команд:
□ Код команды (уникальный ключ)
□ Название команды
□ Город команды
□ Фамилия тренера команды
Информация о команде хранится в строковых полях, которые имеют достаточно большой размер — в нашем случае приблизительно 60 символов. На практике о каждой команде необходимо запоминать больше данных, чем просто ее название, город приписки и фамилия тренера, что существенно увеличивает объем информации. Поэтому для уменьшения размера записей таблицы матчей не только фамилия тренера, но и вся подробная информация о командах вынесена в таблицу команд. Вместо этого команды хозяев и гостей в таблице матчей идентифицируются кодом команды, который является уникальным ключевым значением в таблице команд.
После приведения к третьей нормальной форме база данных с информацией о футбольном чемпионате страны будет иметь структуру, показанную на рис. 3.1, где кроме описания таблиц обозначены связи между ними.
Следование требованиям нормализованных форм не всегда является обязательным. Как уже отмечалось, с ростом числа таблиц структура БД усложняется и возрастает время доступа к данным. В ряде случаев для упрощения структуры БД можно позволить частичное дублирование данных, не допуская, однако, нарушения их целостности и сохраняя их непротиворечивость.
В рассмотренной БД это относится, например, к информации о счете матча. Чтобы исключить дублирование данных, для него не отведено отдельное поле. Узнать счет матча можно с помощью двух запросов к БД, возвращающих число мячей, забитых в указанном матче хозяевами и гостями соответственно. Запрос может иметь следующий вид:
SELECT COUNT(GJDwnerSign) FROM Goal
WHERE Goal.G_Match =:MatchCode
AND Goal.G_OwnerSign =:OwnerSign
Глава 3. Проектирование баз данных
51
|
| Номер матча и признак команды, игрок которой забил гол, передаются в запрос через параметры MatchCode и OwnerSign. |
Рис. 3.1. Структура БД "Чемпионат по футболу"
Поскольку процесс обработки данных усложнился, а время доступа к ним возросло, возможным вариантом для структуры рассмотренной БД является такой, когда счет матча запоминается в отдельном поле таблицы матчей. При этом необходимо обеспечить целостность данных при изменении БД с учетом того факта, что часть ее данных дублирована.
Средства CASE
В предыдущем разделе проектирование БД выполнено вручную. Разработчик сам осуществляет такие операции, как определение состава полей, распределение их по таблицам, а также установление связей между таблицами. Ручное проектирование применяется для разработки БД самого различного назначения и для относительно небольших БД вполне приемлемо. Однако с ростом размера базы данных, когда в нее включаются от нескольких десятков до сотен различных таблиц, возникает проблема сложности организации данных, в том числе установления взаимосвязей между таблицами. Для облегчения решения этой проблемы предназначены системы автоматизации разработки приложений, или средства CASE (Computer Aided Software Engineering).
Средства CASE представляют собой программы, поддерживающие процессы создания и/или сопровождения информационных систем, такие как анализ и
52
Часть I. Основы работы с базами данных
формулировка требований, проектирование БД и приложений, генерация кода, тестирование, обеспечение качества, управление конфигурацией и проектом. То есть средства CASE позволяют решать более масштабные задачи, чем просто проектирование БД. Кстати, согласно предлагаемой ниже классификации, система Delphi также относится к типу CASE, т. к. позволяет автоматизировать разработку приложений.
Систему CASE можно определить как набор средств CASE, имеющих определенное функциональное предназначение и выполненных в рамках единого программного продукта.
Классификация средств (систем) CASE, используемых для разработки баз данных, производится по следующим признакам:
□ ориентация на этапы жизненного цикла;
□ функциональная полнота;
□ тип используемых моделей;
□ степень независимости от СУБД;
□ платформа.
По ориентации на этапы жизненного цикла можно выделить следующие основные типы систем CASE (в скобках приведены названия фирм-разработчиков):
□ системы анализа, предназначенные для построения и анализа моделей предметной области, например, Design/IDEF (Meta Software) и BPWin (Logic Works);
□ системы анализа и проектирования, поддерживающие и обеспечивающие создание проектных спецификаций, например, Vantage Team Builder (Cayenne), Silverrun (Silverrun Technologies), PRO-I (McDonnell Douglas);
□ системы проектирования БД, обеспечивающие моделирование данных и разработку схем баз данных для основных СУБД, например, ERwin (Logic Works), SDesigner (SPD), DataBase Designer (Oracle);
□ системы разработки приложений, например, Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (Oracle), New Era (Informix), SQL Windows (Centura), Delphi (Borland).
По функциональной полноте системы CASE условно делятся на следующие группы:
□ системы, предназначенные для решения частных задач на одном или нескольких этапах жизненного цикла, например, ERwin (Logic Works), S-Designer (SPD), СА8Е.Аналитик (МакроПроджект) и Silverrun (Silverrun Technologies);
□ интегрированные системы, поддерживающие весь жизненный цикл информационной системы и связанные с общим репозиторием (хранилищем), например, система Vantage Team Builder (Cayenne) и система Designer/2000 с системой разработки приложений Developer/2000 (Oracle).
Глава 3. Проектирование баз данных
53
По типу используемых моделей системы CASE делятся на три разновидности: структурные, объектно-ориентированные и комбинированные.
Исторически первыми появились структурные системы CASE, которые основываются на методах структурного и модульного программирования, структурного анализа и синтеза, например, Vantage Team Builder (Cayenne).
Объектно-ориентированные системы CASE получили массовое распространение с начала 90-х годов XX века. Они позволяют сократить сроки разработки, а также повысить надежность и эффективность функционирования информационной системы. Примерами объектно-ориентированных систем CASE являются Rational Rose (Rational Software) и Object Team (Cayenne).
Комбинированные системы CASE поддерживают одновременно и структурное, и объектно-ориентированное программирование, например, Designer/2000 (Oracle).
По степени независимости от СУБД системы CASE делятся на две группы:
□ независимые системы;
□ встроенные в СУБД системы.
Независимые системы CASE поставляются в виде автономных систем, не входящих в состав конкретной СУБД. Обычно они поддерживают несколько форматов баз данных через интерфейс ODBC. К числу независимых систем относятся SDesigner (SDP, Powersoft), ERwin (LogicWorks), Silverrun (Silverrun Technologies).
Встроенные системы CASE обычно поддерживают главным образом формат базы данных, в состав системы управления которой они входят. При этом возможна поддержка форматов и других баз данных. Примером встроенной системы является система Designer/2000, входящая в состав СУБД Oracle.
Платформа определяет компьютер и операционную систему, на которых допускается использовать продукт, созданный с помощью данной системы CASE.
Перечислим средства CASE, которые можно применять при разработке БД и приложений с помощью Delphi.
□ ModelMaker — продукт, поставляемый вместе с Delphi 7. Служит для разработки классов и пакетов компонентов для Delphi. Представляет собой CASE-средство, ориентированное на генерацию кода Delphi. Позволяет хранить и обслуживать отношения между классами и их членами, поддерживает построение UML-диаграмм. По сравнению с другими генераторами кода ModelMaker позволяет разрабатывать сложные проекты.
□ Data Module Designer — позволяет проектировать БД с таблицами формата Paradox. Программа обеспечивает достаточно удобный и наглядный интерфейс. Структура БД, в том числе связи между таблицами, отображается в графическом виде.
54
Часть I. Основы работы с базами данных
П Cadet — независимый продукт, позволяющий проектировать БД с таблицами форматов dBase, Paradox и InterBase. С учетом того, что указанные форматы являются родными для Delphi, программу Cadet удобно использовать при разработке информационных систем.
Программы Data Module Designer и Cadet предназначены для моделирования структур данных и автоматизации проектирования БД. Возможности, предоставляемые этими средствами, меньше, чем возможности таких мощных систем, как, например, Sdesigner, однако доступность делает их привлекательными для использования. Так, программа Cadet является условно бесплатной, a Data Module Designer входит в состав СУБД Paradox 7.O. Впрочем, с появлением ModelMaker использование других CASE-средств может не потребоваться.

|
Глава 4
Технология создания информационной системы
Продемонстрируем возможности Delphi по работе с БД на примере создания простой информационной системы. Эту информационную систему можно разработать даже без написания кода: все необходимые операции выполняются с помощью программы Database Desktop, Конструктора формы и Инспектора объектов. Работа над информационной системой состоит из следующих основных этапов:
□ создание БД;
□ создание приложения.
В простейшем случае БД состоит из одной таблицы. Если таблицы уже имеются, то первый этап не выполняется. Отметим, что совместно с Delphi поставляется большое количество примеров приложений, в том числе и приложений БД. Файлы таблиц для этих приложений находятся в каталоге c:\Program Files\ Common Files\Borland Shared\Data. Готовые таблицы также можно использовать для своих приложений.
Создание таблиц базы данных
Для работы с таблицами БД при проектировании приложения удобно использовать программу Database Desktop, которая позволяет:
□ создавать таблицы;
□ изменять структуры;
□ редактировать записи.
Кроме того, с помощью Database Desktop можно выполнять и другие действия над БД (создание, редактирование и выполнение визуальных и SQL-запросов,
56
Часть I. Основы работы с базами данных
операции с псевдонимами), которые будут рассматриваться позже (в главе, посвященной инструментам).
(_____ ЗамечаниеJ
Почти все рассматриваемые далее действия по управлению структурой таблицы можно выполнить также программно, что описано в главах 7 и 8, посвященных навигационному и реляционному способам доступа.
Процесс создания новой таблицы начинается с вызова команды File\New\Table (Файл\Новая\Таблица) и происходит в интерактивном режиме. При этом разработчик должен:
□ выбрать формат (тип) таблицы;
□ задать структуру таблицы.
В начале создания новой таблицы в окне Create Table (Создание таблицы) (рис. 4.1) выбирается ее формат. По умолчанию предлагается формат таблицы Paradox версии 7, который мы и будем использовать. Для таблиц других форматов, например, dBase IV, действия по созданию таблицы практически не отличаются.
После выбора формата таблицы появляется окно определения структуры таблицы (рис. 4.2), в котором выполняются следующие действия:
□ описание полей;
□ задание ключа;
□ задание индексов;
□ определение ограничений на значения полей;
□ определение условий (ограничений) ссылочной целостности;
□ задание паролей;
□ задание языкового драйвера;
□ задание таблицы для выбора значений.
В этом списке обязательным является только первое действие, т. е. каждая таблица должна иметь хотя бы одно поле. Остальные действия выполняются при необ-
Глава 4. Технология создания информационной системы
57
ходимости. Часть действий, таких как задание ключа и паролей, производится только для таблиц определенных форматов, например, для таблиц Paradox.
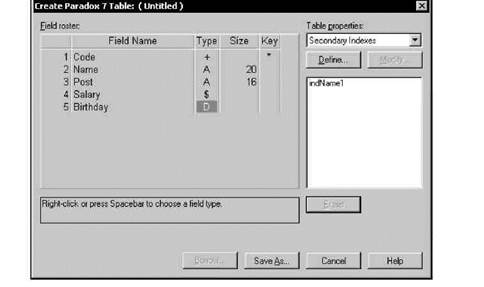
Рис. 4.2. Определение структуры таблицы

Рис. 4.3. Выбор таблицы для заимствования ее структуры
58
Часть I. Основы работы с базами данных
При создании новой таблицы, сразу после выбора ее формата, можно не создавать структуру таблицы, а скопировать ее из другой таблицы: при нажатии на кнопку Borrow (Взаймы) открывается окно Select Borrow Table (Выбор таблицы для заимствования) (рис. 4.3).
В этом окне можно выбрать таблицу (ее главный файл) и указать копируемые элементы структуры, установив соответствующий флажок, например, Primary index (Первичный индекс) для ключа. После нажатия кнопки Open из выбранной таблицы в новую таблицу копируются описания полей, а также те элементы, для которых установлен флажок. Если какой-либо элемент в структуре копируемой таблицы отсутствует, то состояние флажка не имеет значения. Например, если в выбранной таблице не определены ограничения ссылочной целостности, то в новой таблице они не появятся, даже если установлен флажок Referential integrity (Ссылочная целостность).
Впоследствии скопированную структуру можно настраивать, изменяя, добавляя или удаляя отдельные элементы.
После определения структуры таблицы ее необходимо сохранить, нажав кнопку Save As и указав расположение таблицы на диске и ее имя. В результате на диск записывается новая таблица, первоначально пустая, при этом все необходимые файлы создаются автоматически.
Описание полей
Центральной частью окна определения структуры таблицы является список Field roster (Список полей), в котором указываются поля таблицы. Для каждого поля задаются:
□ имя поля — в столбце Field Name;
□ тип поля — в столбце Туре;
□ размер поля — в столбце Size.
Имя поля вводится по правилам, установленным для выбранного формата таблиц. Правила именования и допустимые типы полей таблиц Paradox описаны в главе 2.
Тип поля можно задать, непосредственно указав соответствующий символ, например, а для символьного или i для целочисленного поля, или выбрать его в списке (рис. 4.4), раскрываемом нажатием клавиши <пробел> или щелчком правой кнопки мыши в столбце Туре. Список содержит все типы полей, допустимые для заданного формата таблицы. В списке подчеркнуты символы, используемые для обозначения соответствующего типа, при выборе типа эти символы автоматически заносятся в столбец Туре.
Размер поля задается не всегда, необходимость его указания зависит от типа поля. Для полей определенного типа, например, автоинкрементного (+) или целочисленного (i), размер поля не задается. Для поля строкового типа размер определяет максимальное число символов, которые могут храниться в поле.
Глава 4. Технология создания информационной системы
59
Добавление к списку полей новой строки выполняется переводом курсора вниз на несуществующую строку, в результате чего эта строка появляется в конце списка. Вставка новой строки между существующими строками с уже описанными полями выполняется нажатием клавиши <Insert>. Новая строка вставляется перед строкой, в которой расположен курсор. Для удаления строки необходимо установить курсор на эту строку и нажать комбинацию клавиш <Ctrl>+<Delete>.
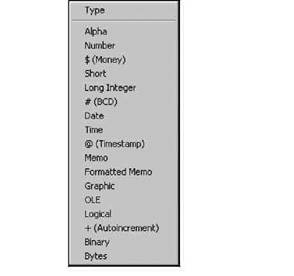
Рис. 4.4. Список типов для полей таблицы Paradox 7
Ключ создается указанием его полей. Для указания ключевых полей в столбце ключа (Key) нужно установить символ *, переведя в эту позицию курсор и нажав любую алфавитно-цифровую клавишу. При повторном нажатии клавиши отметка принадлежности поля ключу снимается. В структуре таблицы ключевые поля должны быть первыми, т. е. верхними в списке полей. Часто для ключа используют автоинкрементное поле (см. рис. 4.2).
Напомним, что для таблиц Paradox ключ также называют первичным индексом (Primary Index), а для таблиц dBase ключ не создается, и его роль выполняет один из индексов.
Для выполнения остальных действий по определению структуры таблицы используется комбинированный список Table properties (Свойства таблицы) (см. рис. 4.2), содержащий следующие пункты:
□ Secondary Indexes (Вторичные индексы);
□ Validity Checks (Проверка правильности ввода значений полей) — выбирается по умолчанию;
□ Referential Integrity (Ссылочная целостность);
60
Часть I. Основы работы с базами данных
П Password Security (Пароли);
□ Table Language (Язык таблицы, языковой драйвер);
□ Table Lookup (Таблица выбора);
□ Dependent Tables (Подчиненные таблицы).
После выбора какого-либо пункта этого списка в правой части окна определения структуры таблицы появляются соответствующие элементы, с помощью которых выполняются дальнейшие действия.
Состав данного списка зависит от формата таблицы. Так, для таблицы dBase он содержит только пункты Indexes и Table Language.
Задание индексов
Задание индекса сводится к определению:
□ состава полей;
□ параметров;
□ имени.
Эти элементы устанавливаются или изменяются при выполнении операций создания, изменения и удаления индекса.
(Замечание^
Напомним, что для таблиц Paradox индекс называют также вторичным индексом.
Для выполнения операций, связанных с заданием индексов, необходимо выбрать пункт Secondary Indexes (Вторичные индексы) списка Table properties (Свойства таблицы), при этом под списком появляются кнопки Define (Определить) и Modify (Изменить), список индексов и кнопка Erase (Удалить). В списке индексов выводятся имена созданных индексов, на рис. 4.2 это индекс indNamel.
Создание нового индекса начинается с нажатия кнопки Define, которая всегда доступна. Она открывает окно Define Secondary Index (Задание вторичного индекса), в котором задаются состав полей и параметры индекса (рис. 4.5).
В списке Fields окна выводятся имена всех полей таблицы, включая и те, которые нельзя включать в состав индекса, например, графическое поле или поле комментария. В списке Indexed fields (Индексные поля) содержатся поля, которые включаются в состав создаваемого индекса. Перемещение полей между списками выполняется выделением нужного поля (полей) и нажатием расположенных между этими списками кнопок с изображением горизонтальных стрелок. Имена полей, которые нельзя включать в состав индекса, выделяются в левом списке серым цветом. Поле не может быть повторно включено в состав индекса, если оно уже выбрано и находится в правом списке.
Глава 4. Технология создания информационной системы
61
| Замечание |
| При работе с записями индексные поля обрабатываются в порядке следования этих полей в составе индекса. Это нужно учитывать при указании порядка полей в индексе. |
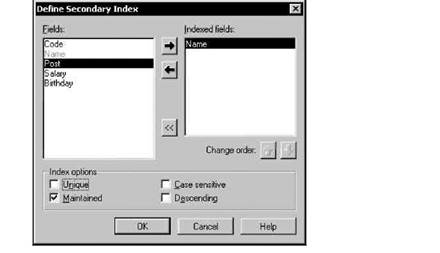
Рис. 4.5. Окно задания индекса
Изменить порядок следования полей в индексе можно с помощью кнопок с изображением вертикальных стрелок, имеющих общее название Change order (Изменить порядок). Для перемещения поля (полей) необходимо его (их) выделить и нажать нужную кнопку.
Флажки, расположенные в нижней части окна задания индекса, позволяют указать следующие параметры индекса:
□ Unique — индекс требует для составляющих его полей уникальных значений;
□ Maintained — задается автоматическое обслуживание индекса;
□ Case sensitive — для полей строкового типа учитывается регистр символов;
□ Descending — сортировка выполняется в порядке убывания значений.
Так как у таблиц dBase нет ключей, для них использование параметра Unique является единственной возможностью обеспечить уникальность записей на физическом уровне (уровне организации таблицы), не прибегая к программированию.
После задания состава индексных полей и нажатия кнопки ОК появляется окно Save Index As, в котором нужно указать имя индекса (рис. 4.6). Для удобства обращения к индексу в его имя можно включить имена полей, указав какой-нибудь префикс, например, ind. Нежелательно образовывать имя индекса только из имен полей, т. к. для таблиц Paradox подобная система именования используется при автоматическом образовании имен для обозначения ссылочной цело-
62
Часть I. Основы работы с базами данных
стности между таблицами. После повторного нажатия кнопки ОК сформированный индекс добавляется к таблице, и его имя появляется в списке индексов.
Созданный индекс можно изменить, определив новый состав полей, параметров и имени индекса. Изменение индекса практически не отличается от его создания. После выделения индекса в списке и нажатия кнопки Modify снова открывается окно задания индекса (см. рис. 4.5). При нажатии кнопки ОК появляется окно сохранения индекса (см. рис. 4.6), содержащее имя изменяемого индекса, которое можно исправить или оставить прежним.
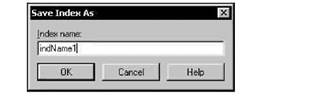
Рис. 4.6. Задание имени индекса
Для удаления индекса его нужно выделить в списке индексов и нажать кнопку Erase. В результате индекс удаляется без предупреждающих сообщений.
Кнопки Modify и Erase доступны, только если индекс выбран в списке.
Задание ограничений на значения полей
Задание ограничений на значения полей заключается в указании для полей:
□ требования обязательного ввода значения;
□ минимального значения;
□ максимального значения;
□ значения по умолчанию;
□ маски ввода.
СЗамечание^
Установленные ограничения задаются на физическом уровне (уровне таблицы) и действуют для любых программ, выполняющих операции с таблицей: как для программ типа Database Desktop, так и для приложений, создаваемых в Delphi. Дополнительно к этим ограничениям или вместо них в приложении можно задать программные ограничения.
Для выполнения операций, связанных с заданием ограничений на значения полей, нужно выбрать пункт Validity Checks (Проверка значений) комбинированного списка Table properties (см. рис. 4.2), при этом ниже списка появляются флажок Required Field (Обязательное поле), поля редактирования Minimum Value, Maximum Value, Default Value, Picture (Маска ввода) и кнопка Assist (По-
Глава 4. Технология создания информационной системы
63
мощь). Флажок и поля редактирования отображают установки для поля таблицы, которое выбрано в списке (курсор находится в строке этого поля).
Требование обязательного ввода значения означает, что поле не может быть пустым (иметь значение Null). Это требование действует при добавлении к таблице новой записи. До того как изменения в таблице будут подтверждены, поле должно получить какое-либо непустое значение, в противном случае генерируется ошибка. Ошибка может также возникнуть при редактировании записи, когда будет удалено старое значение поля и не присвоено новое.
Данное требование удобно использовать для так называемых обязательных полей таблиц, например, для поля фамилии в таблице сотрудников организации.
(_____ ЗамечаниеJ
Обязательность ввода значения не действует на автоинкрементное поле, которое и без того является обязательным и автоматически заполняемым.
Для указания обязательности ввода значения в поле необходимо установить флажок Required Field, который по умолчанию снят.
Для полей некоторых типов, в первую очередь числовых, денежных, строковых и даты, иногда удобно задавать диапазон возможных значений, а также значение по умолчанию. Диапазон определяется минимальным и максимальным возможными значениями, которые вводятся в полях редактирования Minimum Value и Maximum Value. После их задания выход значения поля за указанные границы не допускается при вводе и редактировании любым способом.
Значение поля по умолчанию указывается в поле Default Value. Это значение устанавливается при добавлении новой записи, если при этом для поля не указано какое-либо значение.
(_____ ЗамечаниеJ
Задание диапазона и значений по умолчанию возможно не для всех полей, например, они не определяются для графического поля и поля комментария. Для этих полей соответствующее поле ввода в диалоговом окне определения структуры таблицы (см. рис. 4.2) блокируется.
В поле ввода Picture можно задать маску (шаблон) для ввода значения поля. Ввод по маске поддерживается, например, для таких типов полей, как числовой или строковый. Его удобно использовать для ввода информации определенных форматов, например, телефонных номеров или почтовых индексов.
Для маски используются следующие символы:
□ # (цифра);
□? (любая буква; регистр не учитывается);
□ & (любая буква; преобразуется к верхнему регистру);
□ a (любая буква; преобразуется к нижнему регистру);
□ @ (любой символ);
64
Часть I. Основы работы с базами данных
П! (любой символ; преобразуется к верхнему регистру);
□; (за этим символом следует буква);
□ * (число повторов следующего символа);
□ [abc] или {а,ь,с} (любой из приведенных символов — а, ь, или с; во втором случае значения перечисляются через запятую без пробелов).
Маску можно ввести в поле ввода Picture вручную или использовать для этого диалоговое окно Picture Assistance (Помощник представления), вызываемое нажатием кнопки Assist (рис. 4.7).
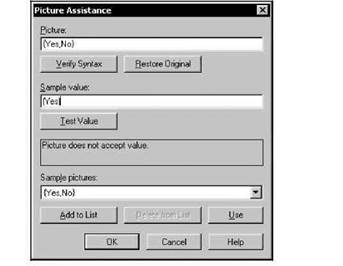
Рис. 4.7. Диалоговое окно формирования маски
Указанное окно помогает ввести, выбрать или откорректировать маску, а также проверить ее функционирование.
Список Sample pictures содержит образцы масок, которые выбираются нажатием кнопки Use. Выбранная маска помещается в поле ввода Picture и доступна для изменения. Для модификации списка образцов масок служат кнопки Add to List и Delete from List: первая добавляет к списку маску, содержащуюся в поле ввода Picture, а вторая удаляет из списка Sample pictures выбранную маску.
Проверка синтаксиса маски выполняется по нажатию кнопки Verily Syntax, результат проверки выводится в информационной панели. Кнопка Restore Original (Вернуть исходную) служит для восстановления начального (т. е. до начала редактирования) значения маски.