Отправляясь в продуктовый магазин, вы наверняка возьмете с собой список покупок, исходя их ваших потребностей и предпочтений. Домохозяйка, возможно, купит полезные продукты для семейного ужина, а холостяк, скорее всего, возьмет пива и чипсов. Понимание таких закономерностей поможет увеличить продажи сразу несколькими способами. Например, если пара товаров X и Y часто покупается вместе, то:
¾ реклама товара X может быть направлена на покупателей товара Y;
¾ товары X и Y могут быть размещены на одной и той же полке, чтобы побудить покупателей одного товара к приобретению второго;
¾ товары X и Y могут быть скомбинированы в некий новый продукт, такой как X со вкусом Y.
Узнать, как именно товары связаны друг с другом, нам помогут ассоциативные правила. Кроме увеличения продаж ассоциативные правила могут быть также использованы в других областях. В медицинской диагностике, например, понимание сопутствующих симптомов может улучшить заботу о пациентах.
Поддержка, достоверность и лифт.
Существуют три основные меры для определения ассоциаций.
Мера 1: поддержка. Поддержка показывает то, как часто данный товарный набор появляется, что измеряется долей покупок, в которых он присутствует (рисунок 22). Яблоко появляется в четырех из восьми покупок, значит, его поддержка 50 %. Товарные наборы могут содержать и несколько элементов.

Рисунок 22 – Примеры покупок
Например, поддержка набора {яблоко,пиво,рис} — два из восьми, то есть 25 %. Для определения часто встречающихся товарных наборов может быть установлен порог поддержки. Товарные наборы, встречаемость которых выше заданного числа, будут считаться частотными.
Мера 2: достоверность. Достоверность показывает, как часто товар Y появляется вместе с товаром X, что выражается как {X->Y}. Это измеряется долей их одновременных появлений. Согласно рисунку 22, достоверность {яблоко->пиво} соответствует трем из четырех, то есть 75 %.
Одним из недостатков этой меры является то, что она может исказить степень важности предложенной ассоциации. Пример принимает во внимание только то, как часто покупают яблоки, но не то, как часто покупают пиво. Если пиво тоже довольно популярно, то неудивительно, что покупки, включающие яблоки, нередко содержат и пиво, таким образом увеличивая меру достоверности. Тем не менее, можем принять во внимание частоту обоих товаров, используя третью меру.
Мера 3: лифт. Лифт отражает то, как часто товары X и Y появляются вместе, одновременно учитывая, с какой частотой появляется каждый из них.
Таким образом, лифт {яблоко->пиво} равен достоверности
{яблоко->пиво}, деленной на частоту {пива}.
Лифт для {яблоко->пиво} равен единице, что означает отсутствие связи между товарными позициями. Значения лифта больше единицы означают, что товар Y вероятно купят вместе с товаром X, а значение меньше единицы — что их совместная покупка маловероятна.
Ведение продуктовых продаж.
Чтобы продемонстрировать использование мер ассоциации, проанализировали данные одного продуктового магазина за 30 дней. Рисунок 23 показывает ассоциации между товарными парами, в которых достоверность выше 0,9 %, а лифт — 2,3. Большие круги означают высокую поддержку, а темные — больший лифт.
Ассоциативные правила.
Можем наблюдать такие закономерности в покупках:
¾ чаще всего покупают яблоки и тропические фрукты;
¾ другая частая покупка: лук и овощи;
¾ если кто-то покупает сыр в нарезке, он, скорее всего, возьмет и сосиски;
¾ если кто-то покупает чай, то он, вероятно, возьмет и тропические фрукты.
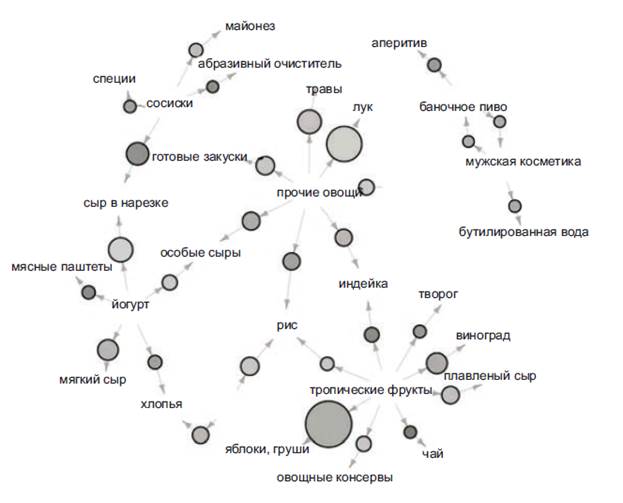
Рисунок 23 – Граф ассоциаций между товарными позициями
Вспомним, что одним из недостатков меры «достоверность» является то, что она может создавать искаженное впечатление о значимости ассоциации. Чтобы показать это, рассмотрим три ассоциативных правила, содержащих пиво (рисунок 24).
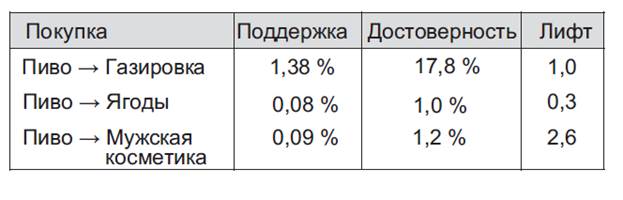
Рисунок 24 – Ассоциативные метрики для трех правил, связанных с пивом
Правило {пиво->газировка} имеет высокую достоверность — 17,8 %. Однако и пиво, и газировка вообще часто появляются среди покупок, поэтому их ассоциация может оказаться простым совпадением (рисунок 25). Это подтверждается значением лифта, указывающим на отсутствие связи между газировкой и пивом.
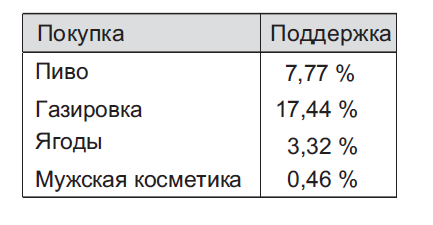
Рисунок 25 – Значение поддержки для отдельных товаров в правилах, связанных с пивом
С другой стороны, правило {пиво->мужская косметика} имеет низкую достоверность из-за того, что мужскую косметику вообще реже покупают. Тем не менее, если кто-то покупает ее, он, вероятно, купит также и пиво, на что указывает высокое значение лифта в 2,6. Для пары {пиво->ягоды} верно обратное. Видя лифт меньше единицы, мы заключаем, что если кто-то покупает пиво, то он, скорее всего, не возьмет ягод.
Хотя несложно определить частотность отдельных товарных наборов, владелец бизнеса обычно заинтересован в получении полного списка часто покупаемых товарных наборов. Для этого потребуется вычислить значения поддержки для каждого возможного товарного набора, после чего выбрать те, поддержка которых выше заданного порога.
В магазине со всего десятью товарами суммарное число возможных конфигураций для анализа составит 1023 (то есть 210 – 1), и это число экспоненциально возрастает для магазина с сотнями товарных позиций. Ясно, что нам потребуется более эффективное решение.
Принцип Apriori.
Одним из способов снизить количество конфигураций рассматриваемых товарных наборов является использование принципа Apriori. Если вкратце, то принцип Apriori утверждает, что если какой-то товарный набор редкий, то и большие наборы, которые его включают, тоже должны быть редки. Это значит, что если редким является, скажем, {пиво}, то редким должно быть и сочетание {пиво, пицца}. Таким образом, составляя список частотных товарных наборов, уже не будем рассматривать ни пару {пиво, пицца}, ни какую-либо другую с содержанием пива. [30]
Поиск товарных наборов с высокой поддержкой
С применением принципа Apriori мы можем получить список частотных товарных наборов, используя следующие шаги.
Шаг 0: начать с товарных наборов, содержащих всего один элемент, таких как {яблоки} или {груши}.
Шаг 1: вычислить поддержку для каждого товарного набора. Оставить наборы, удовлетворяющие порогу, и отбросить остальные.
Шаг 2: увеличить размер анализируемого товарного набора на единицу и сгенерировать все возможные конфигурации, используя товарные наборы из предыдущего шага.
Шаг 3: повторять шаги 1 и 2, вычисляя поддержку для возрастающих товарных наборов до тех пор, пока они не закончатся.
На рисунке 26 показано, как число рассматриваемых товарных наборов может значительно сократиться при использовании принципа Apriori. Если у элемента {яблоки} низкая поддержка, то он будет удален из списка анализируемых товарных наборов вместе со всем, что его содержит, тем самым это сократит число наборов для анализа более чем вдвое.
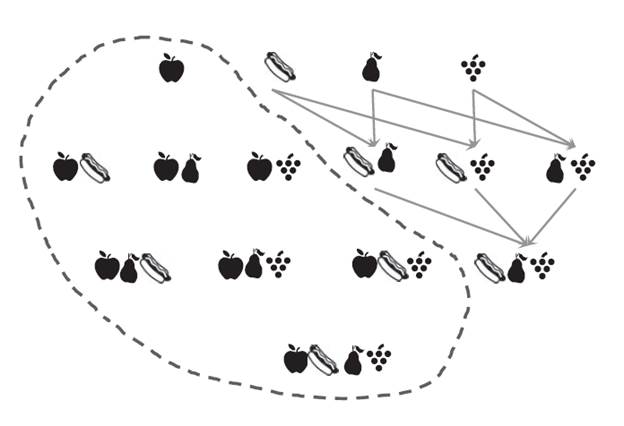
Рисунок 26 – Товарные наборы в пределах пунктирной линии будут отброшены
Поиск товарных правил с высокой достоверностью или лифтом.
Кроме определения товарных наборов с высокой поддержкой, принцип Apriori также может помочь найти товарные ассоциации с высокой достоверностью или лифтом. Поиск этих ассоциаций требует меньше вычислений, поскольку если товарные наборы с высокой поддержкой известны, то достоверность и лифт вычисляются уже с использованием значения поддержки. Возьмем для примера задачу поиска правил с высокой достоверностью. Если правило {пиво, чипсы->яблоки} имеет низкую достоверность, то и все другие правила с теми же образующими элементами и яблоком с правой стороны будут тоже иметь низкую достоверность, включая {пиво->яблоки, чипсы} и {чипсы->яблоки, пиво}. Как и прежде, эти правила могут быть отброшены благодаря принципу Apriori, тем самым снижая число потенциально рассматриваемых правил.
Требует долгих вычислений. Хотя принцип Apriori и снижает число потенциальных товарных наборов для рассмотрения, оно все еще может быть достаточно значительным, если список товаров большой или указан низкий порог поддержки. В качестве альтернативного решения можно сократить число сравнений, используя расширенные структуры данных, чтобы отобрать потенциальные товарные наборы с большей эффективностью. [22]
Ложные ассоциации. В больших наборах данных ассоциации могут быть чистой случайностью. Чтобы убедиться, что обнаруженные ассоциации масштабируемы, их нужно оценить. Несмотря на эти ограничения, ассоциативные правила остаются интуитивно-понятным методом обнаружения закономерностей в наборах данных с управляемым размером.
Ассоциативные правила выявляют то, как часто элементы появляются вообще и в связи с другими.
Есть три основных способа оценки ассоциации:
1. Поддержка {X} показывает, как часто X появляется.
2. Достоверность {X->Y} показывает, как часто Y появляется в присутствии X.
3. Лифт {X->Y} показывает, как часто элементы X и Y появляются вместе по сравнению с тем, как часто они появляются по отдельности.
Принцип Apriori ускоряет поиск часто встречающихся товарных наборов, отбрасывая значительную долю редких.
Самый простой Big Data проект сложнее проекта из мира привычного ПО. Имеется ввиду не сложность собственно алгоритмов или архитектуры, но анализа того, что представляет собой проект, как он работает с данными, как собирается та или иная витрина, какие для нее берутся данные.
Например, нужно решить такую задачу:
¾ загрузить таблицу из Oracle;
¾ посчитать в ней сумму по какого-нибудь полю, сгруппировав по ключу;
¾ результат сохранить в витрину в Hive.
Набор инструментов будет выглядеть примерно так:
¾ Oracle;
¾ Apache Sqoop;
¾ Oozie;
¾ Apache Spark;
¾ Hive.
Простая задача неожиданно приводит к появлению проекта, включающего три независимых инструмента с тремя независимыми папками исходных файлов. И как понять – что происходит в проекте?
Если рассмотреть более типичный случай, то набор артефактов простого проекта в Big Data представляет собой:
¾ SH управляющие файлы;
¾ Sqoop скрипты;
¾ набор Airflow Dag или Oozie Workflow;
¾ SQL скрипты собственно преобразований;
¾ Исходники на PySpark или Scala Spark;
¾ DDL скрипты создания объектов.
Также, особенностью является то, что если пользоваться Cloudera или Hortonworks, то среда не предоставляет удобных средств разработки и отладки.
Облачные среды, такие как AWS или Azure, предлагают все делать в их оболочке, объединяющей все требуемые артефакты в удобном интерфейсе (рисунок 27).
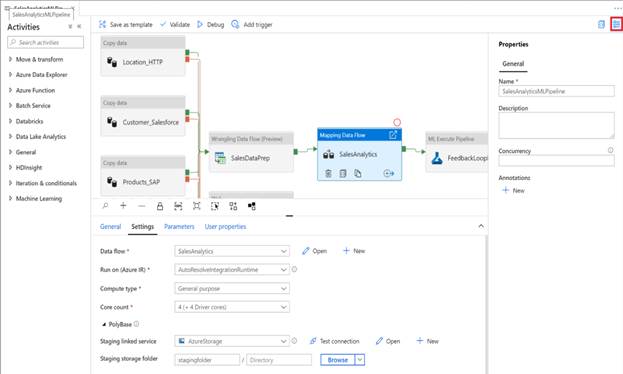
Рисунок 27 – Скриншот с сайта Microsoft Azure.
Еще одним подходом является создание в компании Data Catalog, в котором будет регистрироваться каждый источник данных, и который будет являться единственным источником информации о датасетах, Source of Truth.
Существуют различные инструменты для создания Data Catalog:
¾ Cloudera Navigator (рисунок 28);
¾ Alation;
¾ Colibra.
Эти инструменты, например, с помощью Data Crawlers, мониторят события, происходящие в области данных и строят каталог объектов, пытаясь построить Lineage там, где это возможно. Например, подключаются к событиям Spark и вынимают оттуда данные об объектах. Это иногда позволяет не только записать в каталог объект, но и восстановить его Lineage. В результате появляется каталог как единый Source of Truth для данных, что сильно облегчает понимание их структуры и взаимосвязей.
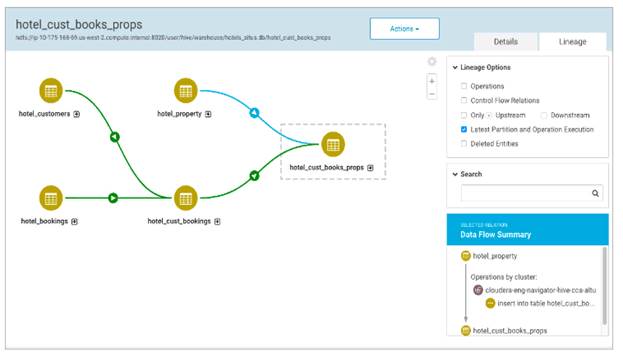
Рисунок 28 – Скриншот с сайта Cloudera Navigator.
Вообще создание и поддержание каталога данных большая и сложная задача. Для этого нужна готовность заказчика, а также необходимы инструмент, команда и время. Требуется зарегистрировать все источники, написать регламенты работы с данными, внедрить – в целом это серьезная инфраструктурная задача для организации.
Мы в компании Neoflex разработали и применяем несколько другой подход, который реализовали в инструменте Datalog или, более полно – Data Topology. Инструмент предоставляет возможность раскрывать топологию объектов проекта в разрезе Dataflow, создавая автообновляемую документацию проекта в разрезе диаграм Dataflow на основе исходных кодов.
Проект Big Data представляет собой исходники для самых разных инструментов, но их объединяет одно – общая доменная модель. Имеется ввиду то, что все артефакты проекта – SQL-скрипты, SH-скрипты, исходники Spark и прочее описывают только одно – Dataflow.
Это значит, что если извлечь из артефактов (скриптов и исходников) данные о таблицах, которые используются в каждом из компонентов, то можно построить диаграмму Dataflow проекта. В большинстве случаев этого более чем достаточно, чтобы сделать содержимое проекта прозрачным и доступным анализу.