}
}
Исполнение обработчика начинается с выполнения кода записанного внутри круглыз скобок оператора if().
После выбора имени файла оно переписывается в строку MyFile. Если по каким то причинам попытка оказалаь неудачной, появляется сообщение "Невозможно открыть файл " с указанием имени файла.
Если диалог прошел удачно, то вызывается конструктор выходного потока, суказанием имени файла, в который будут записываться данные. Если в силу каких то причин поток не улалось создать, то пользователь получит сообщение "Не удалось создать выходной поток". Если поток создан, то элементы массива по очереди передаются в файл.
void __fastcall TForm1::OpenClick(TObject *Sender)
{
if(SaveDialog1->Execute())
MyFile=SaveDialog1->FileName;
else{
ShowMessage("Не удается открыть файл "+MyFile);
return;
}
ifstream in;
in.open(MyFile.c_str());
if(in.fail()){ //поток не создан, то сообщение и выход
ShowMessage("Не удается создать файл "+MyFile);
return;
}
else{ //если поток создан
int i=0;
char str[100];
in>>str[0];
while(str[i]!=EOF){//Пока не будет достигнут коней файла
i++;
in>>str[i];
}
Edit2->Text=AnsiString(str); //Преобразование строк
in.close();
}
}
Как и в предыдущем случае исполнение обработчика начинается с выполнения кода записанного внутри круглыз скобок оператора if(). При удачном открытии файла создается входной поток. В данном случае он создается с помощью конструктора без параметров. Это сделано для того, чтобы проиллюстрировать иной способ создания потока. Функция fail() возвращает значение true, если поток удалось создать. Ввиду того, что размер файла заранее неизвестен приходится созать массив размер которого будет больше, чем размер файла, в данном случае это str[100]. После того как массив заполнен, о чем свидетельствует возвращение потоком признака конца файла EOF, строка переводится в тип AnsiString и выводится в Edit2.
Обработчик выхода из программы вообще выглядит очень просто
void __fastcall TForm1::ExitClick(TObject *Sender)
{
exit(0);
}
В данном примере выходной поток стирает в файле записанные ранее данные.
Если в левом окне написать несколько слов через пробел и записать их в файл, то то в правом окне в считанной строке будут отсутствоваьь пробелы.

Это связано с тем, что операция взятия из потока (>>) читает не всю строку, а только одну лексему, т.е. последовательность символов между двумя пробелами.
Дополнительно о классе ofstream
Конструктор класса ofstream перегружен. Наиболее полныей вид:
ofstream(const char* szName, int nMode = ios::out, int nProt = filebuf::openprot);
Первый аргумент – имя выходного файла, и это единственный обязательный аргумент. Второй аргумент задает режим, в котором открывается поток. Этот аргумент – логическое ИЛИ из следующих величин:
| ios::app | при записи данные добавляются в конец файла, даже если текущая позиция была перед этим перемещена; |
| ios::ate | при создании потока текущая позиция помещается в конец файла; однако, в отличие от режима app, запись ведется в текущую позицию; |
| ios::in | поток создается для ввода; если файл уже существует, он сохраняется; |
| ios::out | поток создается для вывода (режим по умолчанию); |
| ios::trunc | если файл уже существует, его прежнее содержимое уничтожается, и длина файла становится равной нулю; режим действует по умолчанию, если не заданы ios::ate, ios::app или ios::in; |
| ios::binary | ввод-вывод будет происходить в двоичном виде, по умолчанию используется текстовое представление данных. |
Третий аргумент используется только в том случае, если создается новый файл; он определяет параметры создаваемого файла.
Можно создать поток вывода с помощью стандартного конструктора без аргументов, а позднее выполнить метод open с такими же аргументами, как у предыдущего конструктора:
void open(const char* szName, int nMode = ios::out, int nProt = filebuf::openprot);
Только после того, как поток создан и соединен с определенным файлом (либо с помощью конструктора с аргументами, либо с помощью метода open), можно выполнять вывод. Выводятся данные операцией <<. Кроме того, данные можно вывести с помощью методов write или put:
ostream& write(const char* pch, int nCount);ostream& put(char ch);
Метод write выводит указанное количество байтов (nCount), расположенных в памяти, начиная с адреса pch. Метод put выводит один байт.
Например, если имеется поток с именем fout,оператор
fout.put(‘Z’);
выведет в поток символ «Z».
Функции put() допускают сцепление, например
fout.put(‘Z’).put(‘\n’);
В данном случае в поток попадет сивол «Z», а за ним перевод на новую строку.
Для того чтобы переместить текущую позицию, используется метод seekp:
ostream& seekp(streamoff off, ios::seek_dir dir);Первый аргумент – целое число, смещение позиции в байтах. Второй аргумент определяет, откуда отсчитывается смещение; он может принимать одно из трех значений:
| ios::beg | смещение от начала файла |
| ios::cur | смещение от текущей позиции |
| ios::end | смещение от конца файла |
Сместив текущую позицию, операции вывода продолжаются с нового места файла.
После завершения вывода можно выполнить метод close, который выводит внутренние буферы в файл и отсоединяет поток от файла. То же самое происходит и при уничтожении объекта.
Пример.
char s[80], c;
ifstream infile("test.txt");
if(!infile){
ShowMessage("Файл не удается открыть");
return;
}
int i=0;
while((c=infile.get())!=EOF){
if(c=='\n')
//занесение нулевого символа в конец строки
s[i]=0;
// обработка строки
...
i=0;
}
//формирование строки
else s[i++]=c;
}
//закрытие файла
infile.close();
Дополнительно о классе ifstream
Класс ifstream, осуществляющий ввод из файлов, работает аналогично. При создании объекта типа ifstream в качестве аргумента конструктора можно задать имя существующего файла:
ifstream(const char* szName, int nMode = ios::in, int nProt = filebuf::openprot);Можно воспользоваться стандартным конструктором, а подсоединиться к файлу с помощью метода open.
В классе ifstream есть методы чтения из потока.
Метод write() выводит в файл из символьного массива на который указывает его первый параметр число символов заданных вторым параметром. Например,
out.write(str,5);
записывае в поток out 5 символов из массива str. Символы не обрабатываются. Это значит, что если встречаются управляющие символы, например, символ конца строки ’\0’, то он рассматривается просто как символ.
В классе ifstream есть методы чтения из потока.
Метод read(), предназначен для чтения из потока без обработки.
Функция gcount() сообщает количество символов, прочитанных последней операцией ввода.
Метод get() имеет три модификации:
| get() | Возвращает одиночный символ без анализа. |
| get(char) | Возвращает ссылку на на тот объект потока. для которого вызывался метод |
| get(char*, int n, char delim) |
Примеры.
char s[80], c;
ifstream infile("test.txt");
if(!infile){
ShowMessage("Файл не удается открыть");
return;
}
int i=0;
while((c=infile.get())!=EOF){
if(c=='\n')
//занесение нулевого символа в конец строки
s[i]=0;
// обработка строки
...
i=0;
}
//формирование строки
else s[i++]=c;
}
//закрытие файла
infile.close();
Управление потоком ввода-вывода
Для того, чтобы увидеть результаты работы программы они должны быть представлены соответствующим образом. В самом деле, если вы рассчитываете, например, таблицу натуральных логарифмов y= ln x, то и вывод должен быть организован в виде таблицы чисел с равным количеством знаков. Для большей информативности числа должны быть одинаково сориентированы относительно границ таблицы, а та, в свою очередь, относительно краев листа. Печать всех значений подряд просто бессмысленна.
Размещение вывода называют форматом. В С++ форматом можно управлять, т.е. устанавливать число пробелов между выводимыми символами, определять число цифр после десятичной точки и т.д. Команды форматирования можно применять к любому выходному потоку. Как правило, команды форматирования содержат, так называемые, флаги. Флаг – это инструкция, разрешающая выполнение одного из двух возможных действий. Наверное, сейчас трудно определитьопределить, откуда в программировании появилось слово флаг, предписывающее дальнейшее поведение программы. Возможно, что это связано с техникой управления войсками, когда команды отдавались с помощью различных флагов.
Для ссылки на флаг используется функция потокового класса setf(имя_флага). Функция-член с именем setf()(сокращение от set flag – установить флаг) класса ofsteam позволяет установить флаги, некоторые из них описаны в приведенной ниже таблице. Функция-член с именем unsetf() напротив дает возможность сбросить флаг.
| Флаг | Значение | Состояние по умолчанию |
| ios::fixed | Установка флага приводит к тому, что числа с плавающей точкой не используют запись с основанием e. Установка флага автоматически сбрасывает флаг ios::scrintific. | Сброшен |
| ios::scientific | Установка флага приводит к тому, что числа с плавающей точкой записываются с использованием e. Установка флага автоматически сбрасывает флаг ios::fixed | Сброшен |
| ios::showpoint | При установке флага в записи чисел с плавающей точкой всегда присутствует десятичная точка и замыкающие нули. Если флаг сброшен, то числа, в которых после десятичной точки стоят все нули, будут выводитсявыводиться без десятичной точки и следующих за ней нулей | Сброшен |
| ios::showpos | При установке флага перед положительными числами выводится знак “+”. Знак минус перед отрицательными числами ставится всегда, независимо от установки флагов. | Сброшен |
| ios::right | Если установлен этот флаг и в вызове функции-члена width указано значение ширины поля, то следующий элемент будет выводитсявыводиться прижатым к правому краю пространства с шириной равной, указанной в width количеству интервалов. Другими словами перед выводимым элементом будет добавлено недостающее число пробелов. Установка этого флага автоматически сбрасывает флаг ios::left. | Установлен |
| ios::left | Если установлен этот флаг и в вызове функции-члена width указано значение ширины поля, то следующий элемент будет выводиться прижатым к левому краю пространства с шириной равной, указанной в width количеству интервалов. Другими словами перед выводимым элементом будет добавлено недостающее число пробелов. Установка этого флага автоматически сбрасывает флаг ios::right. | Сброшен |
Для управления флагами в классе ios есть методы flags, setf и unsetf.
Перед осуществлением вывода можно установить несколько флагов. Пусть в программе организован поток с именем outStream. Ниже приведен фрагмент программы с установкой флагов для этого потока
outStream.setf(ios::scientific); //выводимые числа будут
// представлены с использованием е
outStream.setf(ios::showpoints); //используется десятичная точка
outStream.setf(ios::showpos); //перед положительными числами
//ставится +
Для управления выводом используется несколько функций-членов класса ofsteam. Одна из таких функций нам уже встречалась, это функция precision(int n). Применение этой функции приводит к тому, что любое число с десятичной точкой будет выводитсявыводиться в поток с n значащими цифрами после десятичной точки. Например, если имеется поток outStream, то после инструкции
outStream.precision(2);
все числа будут выводиться с двумя знаками после десятичной точки. Если потом потребуется изменить количество значащих цифр после точки, достаточно переписать последнюю строку с другим параметром, который должен быть целым неотрицательным числом, например,
outStream.precision(3);
Вот пример программы с использованием флагов. Программа рассчитывает выражение  для 10 значений n от 0 до 9
для 10 значений n от 0 до 9
#include <iostream>
#include <cmath>
#include <fstream>
#define pi 3.1415926
using namespace std;
main(){
ifstream inStream;//объявление потоков
ofstream outStream;
long double db1[10], db2[10];
outStream.open("character.dat"); //присоединение к файлу
for(int n=0;n<10;n++){
db1[n]=100*sin(pi/(n+1));
outStream<<db1[n]<<"\n";
}
outStream.close(); //закрытие потоков
inStream.open("character.dat"); //присоединение к файлу
if (inStream.fail()){
//Печать сообщения об ошибке
cout<<"Не удается открыть файл character.dat\n";
exit(1);// Функция аварийного завершения.
}
for(int i=0; i<10;i++)
inStream>> db2[i];
inStream.close(); //закрытие потоков
cout.width(20); //для вывода числа отводится 20 позиций
cout.setf(ios::right); //Выравнивание по правому краю
cout.setf(ios::fixed); /*выводимые числа представлены в
форме c фиксированной точкой*/
cout.setf(ios::showpos); //перед положительным числом знак +
for(int i=0; i<10;i++)
cout<<db2[i]<<endl;
char z;
cin>>z;
}
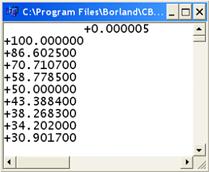

Видно, что выравнивание первого числа происходит по правому краю таблицы. После небольшого изменения программы можно выполнить выравнивание для всех строк, как это показано на втором рисунке..
Попробуйте теперь применить выравнивание по левому краю и сравните результаты.
Очень удобной функцией форматирования в потоке cout является функция width(интервал). Этой функцией мы уже воспользовались в предыдущем примере, а теперь пояснимпоясним, как она работает.
Функция width() позволяет отвести количество символов для вывода числа, точнее расстояние от начала печати. Если количество выводимых символов окажется большим, то функция на количество выводимых разрядов не влияет. Вот пример программы
#include <iostream>
using namespace std;
#include <windows>
main(){
SetConsoleOutputCP(1251);
int a=1;
while(a<1000000){ //организация условно-бесконечного цикла
cout<<"Введите целое число a=";
cin>>a;
cout.width(4);
cout<<a<<endl;
}
}
Вот результат

Видно, что при выводе для результата отводится 4 позиции. Свободные позиции заполняются пробелами. Если выделенных позиций не хватает, то интервал увеличивается на число необходимых позиций.
5.2. Ввод имен файлов
В примере, который мы только, что рассмотрели, имя файла было задано в программе в виде, так называемой, строки, т.е. текста заключенного в кавычки. О строках мы еще будем говорить позднее. А сейчас подумаем вот над чем. Нельзя ли имя файла прочитать из другого файла? Ответ можно предсказать – конечно, это возможно. Но чтобы не запутаться в файлах заранее дадим им имена. Рабочий файл в который записывается информация назовем workFaile.dat, а файл содержащий имя рабочего файла будем называть nameFile.
Далее поступим следующим образом. В разрабатываемой программе создадим массив символов nameWork[n] в который запишем имя рабочего файла в кавычках. Это значит, что размер массива n должен хотя бы на единицу превосходить количество символов в имени рабочего файла, в данном случае workFile.dat содержит 12 символов, т.е. величина n должна быть не менее 13. Напомним, что индексация элементов массива начинается с нуля. Если имя рабочего файла заранее неизвестно, то создавая такой массив следует заранее предусмотреть максимально возможный размер. После того как имя рабочего файла будет помещено в массив, последний можно записать в виде файла, подобно тому как мы только что сделали в предпоследнем примере. При необходимости это имя будет прочитано и программа создаст необходимые потоки ввода-вывода.
Как всегда рассмотрим пример. Создадим программу, которая вводит 4 целых числа. Затем спрашивает имя рабочего файла. После чего вычисляет разность соседних чисел, которая записывается в рабочий файл. Далее программа читает рабочий файл и выводит его на экран.
#include <iostream> //библиотека ввода вывода с использованием
//стандартных устройств
#include <fstream> //библиотека ввода из файла
#include <cstdlib> //библиотека вывода в файл
#include<windows>
using namespace std;
main(){
ifstream inStream; //объявление потока ввода из файла
ofstream outStream; //объявление потока вывода в файл
int number[4], diskr[3];
char nameWork[15]; //строка для записи имени рабочего файла
SetConsoleOutputCP(1251);
cout<<"Введите 4 числа \n";
for(int i=0; i<4;i++) {
cin>>number[i];
}
cout<<"Введите имя рабочего файла \n"; /*Имя файла в который
записываются числа*/
cin>>nameWork;
outStream.open("nameFile"); //присоединение файла с именем к потоку
outStream<< nameWork; //запись имени рабочего файла в потоке
inStream.open("nameFile"); //присоединение файла с именем
// рабочего файла к входному потоку
for(int i=1; i<4;i++) {
number[i]=number[i]-number[i-1];
outStream<< number[i];
}
inStream.open(nameWork);
inStream.fail();
if (outStream.fail()){
cout<<"Не удается открыть файл character.dat\n";
exit(1);
}
for(int i=0; i<4; i++){
inStream>>diskr[i];
cout<< diskr[i];
}
inStream.close();
outStream.close();
cin >>number[0];
}
5.3. Манипуляторы
Параметры форматирования потока можно установить не только посредством установки и снятия флагов, но и с помощью специальных функций, которые называются манипуляторами. Манипуляторы можно включать в выражения ввода-вывода. На самом деле нам уже известен один манипулятор, это endl. Этот манипулятор позволяет выводить символы с новой строки.
Приведем пример:
cout<<”Пример манипулятора”<<endl;
Этот манипулятор не использует никаких параметров, но есть манипуляторы которым для форматирования нужно указать дополнительные сведения или, говоря иначе, параметры.
Некоторые манипуляторы без параметров описаны в следующей таблице.
| Манипулятор | Назначение | Функция |
| dec | Устанавливает флаг десятичной системы счисления. | При вводе и выводе |
| hex | Устанавливает флаг шестнадцатеричной системы счисления. | При вводе и выводе |
| oct | Устанавливает флаг восьмеричной системы счисления. | При вводе и выводе |
| ws | Пропускает пробельные символы – пробел, знаки табуляции ‘\t’ и ‘\v’, символ перевода строки ‘\n’, символ возврата каретки ‘\r’, символ перевода страницы ‘\f’. | Действует только при выводе. |
| endl | Обеспечивает включение в выходной поток символа новой строки и выгружает содержимое этого потока. | Действует только при выводе. |
| ends | Вставляет в поток нулевой символ ‘\0’, что соответствует признаку конца строки. | Действует только при выводе. |
| flush | “Сбрасывает” поток, т.е. переписывает содержимое буфера, связанного с потоком, на соответствующее устройство. | Действует только при выводе. |
Здесь полезно заметить, что манипуляторы endl и ends играют важную роль при выводе. Без них нельзя гарантировать, что информация не останется в буфере.
5. Указатели
Познакомимся с еще одним типом переменных – это указатель. Указатель позволяет работать с памятью компьютера.
Как вы знаете, память компьютера образуют пронумерованные восьмиразрядные байты, в которых хранятся значения переменных. Причем каждая переменная может занимать несколько соседних байтов в зависимости от ее типа. Эти несколько байтов называются ячейкой. Номер первого байта ячейки называется ее адресом. Поэтому адреса двух переменные, хранящиеся в соседних ячейках памяти, могут отличаться на единицу - для символьных переменных, на 4 - для целых типа int, на 8 - для типа double, и вообще говоря, на практически любое целое число, если это массив, структура или переменная иного типа созданного программистом.
На заре появления вычислительных машин, когда языков программирования, в том виде, в котором мы знаем их сейчас, не было, программисты работали именно с адресами. То есть, каждый оператор программы представлял собой код, состоящих из нулей и единиц, который соответствовал командам типа взять число из памяти с адресом n, поместить число по адресу m, выполнить операцию p и т.п. Такой подход сохранился до сих пор в языках низкого уровня типа ассемблера. Конечно, писать всю программу на подобном языке сложно, но определенные преимущества в этом есть. Например, нужно создать программу работы с массивом, размеры которого заранее неизвестны, или изменить размеры уже созданного массива. В таких задачах можно указать адрес, с которого начинается продолжение массива. Подобные примеры можно продолжить. Вы уже вероятно поняли, что если такой подход в программировании имеет преимущества, то он реализован в С++.
Вся память компьютера делится на несколько кусков или как принято говорить сегментов. Байты с младшими адресами отданы для операционной системы, которая управляет компьютером. После этого идет сегмент, в котором хранится программа, включая значения всех ее переменных и функций. За тем идет сегмент, выделенный для хранения статических и внешних переменных. Дальше идет свободная память, ее программа может использовать в своих целях. Занятую часть свободной памяти принято называть кучей (heap). Таким образом, куча это присоединенная к программе память. Этот сегмент памяти принято называть также динамической памятью. Переменные, значения которых хранятся в динамической памяти, называются динамическими переменными.
| Операционная система | Код программы | Статические и внешние данные | Куча | Свободная оперативная память | Стек | Неиспользуемая память | Буферы, ПЗУ, видеопамять |
| Младшие адреса | Старшие адреса |
Объем оперативной памяти для кучи определяется запросами программы.
В процессе компиляции программы имена переменных преобразуются в адреса ячеек, в которых размещаются значения этих переменных. А операторы преобразуются в команды типа взять код по адресу n и поместить его по адресу m, т.е. компилятор осуществляет перевод инструкций с языка понятного человеку в команды компьютера. Подчеркнем еще раз, имена переменных не используются, а используются адреса, ну и, конечно, значения этих переменных. Программист может получить доступ к этим адресам, если он использует специальный тип переменных, который называется указателем.
Указатель – это переменная, которая хранит адрес первого байта другой переменной или функции, вообще говоря, указатель хранит адрес любого объекта, но о таких указателях мы будем говорить позже. Естественно, что значение указателя, это целое число. Но не нужно думать, что переменная типа указатель это то же самое, что переменная типа int. В противном случае с указателями можно было бы осуществлять математические операции, результаты которых были бы заведомо неверными. Указатель это переменная специального типа, причем каждый указатель может работать только с переменными своего типа. Например, указатель объявленный для чисел типа double не может применяться к другим типам переменных. При объявлении, указателям должны быть даны имена. Для имен указателей применяются обычные правила, например, указатель можно назвать словом pointer.Но такое имя может иметь переменная. Для того, что бы программа при объявлении не перепутала имена указателей и переменных впереди имени указателя ставится знак звездочка ' * '’, т.е синтакс указателей таков:
тип [модификатор] * имя_указателя;
В данном случае:
тип – имя типа переменной, адрес которой будет содержать переменная указатель (на которую он будет указывать), например char или int;
имя – идентификатор переменной типа указатель;
* - вспомогательный символ, говорящий о том, что происходит объявление указателя.
Например,
int *pointer1, x1;
double * pointer2, x2;
char *pointer3;
Такая запись означает, объявление 5 переменных. Переменная x1 – будет содержать целое число тиа int, x2-дробное типа double. Кроме того, объявлены 3 переменные типа указатель, о чем свидетельствует звездочка перед их именами. На самом деле имена указателей это pointer1, pointer2, pointer3. Звездочка является признаком указателя, и не входит в имя. Иногда, для того, чтобы выделить имена указателей используются круглые скобки.