СУБД
Лабораторная работа № 1
Основные сведения из теории СУБД
(Систем управления базами данных)
Задание по работе
1.1. Законспектировать незнакомый материал раздела 2,3.
1.2. Выполнить задания из раздела 3.
1.3. Ответить на вопросы раздела 4 и защитить работу.
Основы теории
Для хранения информации могут использоваться 3 типа моделей:
2.1. Иерархическая модель (файловая система).
2.2. Сетевая (Интернет)
2.3. Реляционная (таблицы с полями ключей).
Иерархическая модель (файловые системы)
Историческим шагом создания в совершенствовании файловых систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы файл - это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле и структура этих данных зависят от конкретной системы управления файлами и от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным.
Первая развитая файловая система была разработана фирмой IBM (1960–е годы). Во всех файловых системах явно или неявно выделяется некоторый базовый уровень, обеспечивающий работу с файлами, представляющими набор прямо адресуемых в адресном пространстве файла блоков. Размер этих логических блоков файла совпадает или кратен размеру физического блока диска и обычно выбирается равным размеру страницы виртуальной памяти, поддерживаемой аппаратурой компьютера совместно с операционной системой.
Для создания адресности в файловых системах используется структура – каталоги. Возможны два варианта. Первый - каждый архив файлов целиком располагался на одном дисковом пакете (или логическом диске, разделе физического дискового пакета, представляемом с помощью средств операционной системы как отдельный диск). В этом случае полное имя файла начинается с имени дискового устройства, на котором установлен соответствующий диск.
Этот вариант создает изолированную файловую систему (файловая система фирмы DEC –для персональных компьютеров). Второй вариант – централизованный. Имя задается как совокупность каталогов и файлов и формируется как единое дерево. Полное имя файла начинается с имени корневого каталога (имя диска учитывается по умолчанию). Сама система, выполняя поиск файла по его имени, и если необходимо, запрашивает установку других дисков. Во многом централизованные файловые системы удобнее изолированных: система управления файлами принимает на себя больше рутинной работы. Но в таких системах возникают существенные проблемы, если требуется перенести поддерево файловой системы на другую вычислительную установку. Компромиссное решение применено в файловых системах ОС UNIX. На базовом уровне в этих файловых системах поддерживаются изолированные архивы файлов. Один из этих архивов объявляется корневой файловой системой.
Файлы применяются для хранения текстовых данных: документов, текстов программ и т.д. и обеспечивают хранение слабо структурированной информации.
Примером иерархической модели является дерево каталогов и файлов в ОС DOS (команда Alt + F10), в ОС Windows (программа «Проводник»), административные схемы предприятий и т. д..
Сетевая модель
Сетевая модель базы данных похожа на иерархическую. Она имеет те же основные составляющие (узел, уровень, связь), однако характер их отношений принципиально иной. В сетевой модели принята свободная связь между элементами разных уровней. В качестве примера на рис. 1 представлена схема распределения преподавателей, предметов и студенческих групп. Видно, что один преподаватель может преподавать в нескольких группах и что один и тот же предмет могут вести разные преподаватели.
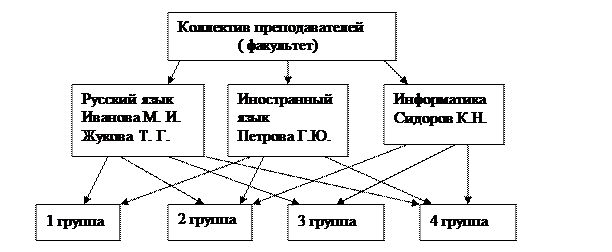
По сетевой модели построен Internet, создаются графики выполнения различных работ по нескольким ветвям.
Реляционная модель
Термин «реляционный» (от латинского relatio — отношение) указывает, прежде всего, на то, что такая модель хранения данных построена на взаимоотношении составляющих ее частей. В простейшем случае она представляет собой двухмерный массив или двухмерную таблицу, а при создании сложных информационных моделей составит совокупность взаимосвязанных таблиц.
В табл. 1, даны сведения об студентах факультета (фамилия, имя, отчество, год рождения, группа, номер личного дела). Каждая строка такой таблицы называется записью. Каждый столбец в такой таблице называется полем. На основании этой таблицы можно создать базу данных студентов с названием «Факультет».
Таблица 1.
| Группа | № личного дела | Фамилия | Имя | Отчество | Дата рождения |
| 1ж | Коноплев | Михаил | Александрович | 13.10.80 | |
| 1ж | …. | …. | … | … | … |
| 2ж | Иванова | Елена | Сергеевна | 14.02.81 | |
| 2ж | … | … | … | … | … |
Реляционная модель данных имеет следующие свойства:
· Каждый элемент таблицы — один элемент данных.
- Все столбцы в таблице являются однородными, т. е. имеют один тип (числа, текст, дата и т. д.).
- Каждый столбец (поле) имеет уникальное имя.
- Одинаковые строки (записи) в таблице отсутствуют.
- Порядок следования строк в таблице может быть произвольным и может характеризоваться количеством полей (столбцов), количеством записей (строк), типом данных(численных, текстовых, логических, графических, др.).
Реляционная модель данных, как правило, состоит из нескольких таблиц, которые связываются между собой ключами.
Ключ — поле, которое однозначно определяет соответствующую запись.
В табл.1 в качестве ключа может служить номер личного дела студента. Реляционная модель является наиболее удобной и применимой для хранения данных. При определении состава таблиц существует правило: в каждой таблице должны храниться данные только об одном классе (типе) объектов. Например, в одной таблице нельзя хранить анкетные данные студента и фамилии преподавателей, которым он сдавал экзамены, т.к. это свойства разных классов объектов.
Если в базе данных должна содержаться информация о разных классах объектов, то она должна быть разбита на отдельные таблицы. Связь между таблицами осуществляется с помощью общих полей.
Связи между любыми двумя таблицами относятся к одному из трех типов: один-к-одному (1:1), один-ко-многим (1:М) и много-ко-многим (М:М).
Связь типа “один-к-одному” (1:1)
При этом типе связи каждой записи в одной таблице соответствует не более одной записи в другой таблице. Этот вид связи встречается довольно редко. В основном в тех случаях, когда часть информации об объекте либо редко используется, либо является конфиденциальной (такая информация хранится в отдельной таблице, которая защищена от несанкционированого доступа).