Зная из предыдущей главы, насколько эффективно методы одномерного поиска позволяют сокращать интервал неопределенности (одномерный или двумерный), можно попытаться применить ту же методику и к многомерному пространству. Один из наиболее очевидных методов исключения областей называется методом касательной к линии уровня, так как в нем используются касательные к линиям уровня целевой функции. Продемонстрируем этот метод на примере двумерной целевой функции. Пусть произвольно выбранная точка пространства проектирования лежит на линии уровня, проходящей несколько ниже пика, соответствующего оптимальному решению. Проведем через эту точку касательную к линии уровня. Сделать это нетрудно, так как касательная должна лежать в плоскости линии уровня и быть перпендикулярной локальному градиенту поверхности целевой функции. Если целевая функция достаточно гладкая и унимодальная, то касательная к линии уровня разделит пространство проектирования на две части, в одной из которых вероятность нахождения оптимума велика, а в другой мала. Пользуясь этим приемом в нескольких удачно выбранных точках, для которых известны значения целевой функции, можно существенно сузить область поиска. Однако осуществление этого алгоритма связано с некоторыми трудностями. Если линии уровня вогнутые, а не выпуклые, то может оказаться исключенной область, содержащая экстремум. Кроме того, оставшаяся после нескольких исключений область неопределенности может иметь конфигурацию, мало пригодную для применения других алгоритмов.
Одним из методов исключения является метод сеточного поиска, разработанный Мишке и дающий неплохие результаты. В этом случае суженная область неопределенности представляет собой гиперкуб - многомерный аналог квадрата или куба, - размеры которого можно определить заранее. Благодаря этому метод Мишке является одним из немногих методов многомерного поиска, эффективность которого поддается измерению. Чтобы лучше понять сущность этого метода, рассмотрим его для случая пространства проектирования, определяемого двумя переменными. Исходную область неопределенности в зависимости от размерности пространства отобразим на единичный квадрат, куб или гиперкуб. Это позволит вести поиск в нормированной области со стороной, равной единице. В гиперкубе построим сетку, образованную попарно симметричными взаимно ортогональными плоскостями, параллельными координатным направлениям, вдоль которых изменяются проектные параметры. Эти плоскости пересекаются по прямым, которые в свою очередь пересекаются в точках, называемых в дальнейшем узлами. Вычислим значения целевой функции в узлах и в центре куба. В случае М проектных параметров получим 2  значений целевой функции, из которых выберем наибольшее. Примем соответствующий узел за центр гиперкуба меньших размеров и продолжим исследование. Процесс продолжается до тех пор, пока не будет достигнута требуемая степень сужения интервала неопределенности. Если в области допустимых значений обозначить степень сужения вдоль какой-либо оси координат через r, то линейное сужение для b-мерного гиперкуба будет равно f=r
значений целевой функции, из которых выберем наибольшее. Примем соответствующий узел за центр гиперкуба меньших размеров и продолжим исследование. Процесс продолжается до тех пор, пока не будет достигнута требуемая степень сужения интервала неопределенности. Если в области допустимых значений обозначить степень сужения вдоль какой-либо оси координат через r, то линейное сужение для b-мерного гиперкуба будет равно f=r  , а число вычисленных значений целевой функции N = b (2
, а число вычисленных значений целевой функции N = b (2  ) +1.
) +1.
Мишке рекомендует выбирать r в интервале значений 2/3<r<1. Он отмечает также, что в случае трех и более переменных большую эффективность обеспечивают не кубические, а звездообразные области.
Метод случайного поиска
Выше в этой главе говорилось о громоздкости вычислений в случае многомерного пространства на примере числа значений целевой функции, которые необходимо вычислить, чтобы, пользуясь методом сеток, получить f==0,1, и было показано, что это число растет как степенная функция, показатель степени которой равен размерности пространства. Оригинальный подход, позволяющий обойти эту трудность, предложен Бруксом и основан на случайном поиске. Пусть пространство проектирования представляет собой куб или гиперкуб со стороной, равной единице, и разделено на кубические ячейки путем деления на 10 равных частей каждой стороны куба, соответствующей одному из проектных параметров. При N=2 число ячеек равно 100, при N=3оно равно 100, в общем случае при N измерений число ячеек равно 10  . Вероятность того, что выбранная наугад ячейка войдет в число 10% наиболее перспективных ячеек, равна 0,1, так как при N=1 нас будет интересовать одна ячейка из 10, при N=2 - одна из десяти лучших при общем количестве ячеек 100 и т.д. Вероятность того, что мы пропустим одну из 10% наиболее перспективных ячеек, составит 0,9. Если случайным образом выбрать две ячейки, то вероятность пропуска будет 0,9
. Вероятность того, что выбранная наугад ячейка войдет в число 10% наиболее перспективных ячеек, равна 0,1, так как при N=1 нас будет интересовать одна ячейка из 10, при N=2 - одна из десяти лучших при общем количестве ячеек 100 и т.д. Вероятность того, что мы пропустим одну из 10% наиболее перспективных ячеек, составит 0,9. Если случайным образом выбрать две ячейки, то вероятность пропуска будет 0,9  , т. е 0,81. Вообще вероятность нахождения по крайней мере одной ячейки из наиболее перспективных, доля которых равна f, после N попыток составит Р=1- (1-f) .
, т. е 0,81. Вообще вероятность нахождения по крайней мере одной ячейки из наиболее перспективных, доля которых равна f, после N попыток составит Р=1- (1-f) .
В таблице 1 указано, сколько ячеек надо выбрать случайным образом, чтобы обеспечить заданную вероятность при заданной доле наиболее перспективных ячеек. Из нее видно, что при случайной выборке 44 ячеек вероятность достижения f=0,1 составит 99%.
Это очень неплохо, если вспомнить, что для 100% -ного обеспечения целевую функцию в случае пяти переменных пришлось бы вычислить 2 476 099 раз.
Таблица 1.
| F | ВЕРОЯТНОСТЬ | |||
| 0.80 | 0.90 | 0.95 | 0.99 | |
| 0.1 | ||||
| 0.05 | ||||
| 0.01 | ||||
| 0.005 |
Метод случайного поиска имеет два преимущества. Во-первых, он пригоден для любой целевой функции независимо от того, является она унимодальной или нет. Во-вторых, вероятность успеха при попытках не зависит от размерности рассматриваемого пространства. Хотя этот метод не позволяет непосредственно найти оптимальное решение, он создает подходящие предпосылки для применения в дальнейшем других методов поиска. Поэтому его часто применяют в сочетании с одним или несколькими методами других типов. Функция Random -случайное число из [0,1]
Один из возможных примеров алгоритмов.
f (x) - > min, xÎ Rn
x0-начальное приближение (массив [1: n])
Будем считать, что нам известна функция
minf (j (q)), которая вычисляется qmin: j (qmin) =min j (q)
r: =f (x0); r1: =r+2*e; x: =x0;
пока abs (r1-r) >= e
нц
r1: =r; x1: =x;
Для i от 1 до n
нц
l [i]: = random;
x [i]: =x [i] +q*R [i];
кц
j (q): =f (x);
qmin: = minf (j (q));
x: =x1;
для i от 1до n
нц
x [i]: =x [i] + qmin* l [i] ;
кц
r: =f (x);
кц
Градиентные методы
Во многих алгоритмах многомерной оптимизации так или иначе используется информация о градиентах. Проиллюстрируем это положение следующим простым примером.
Представим себе, что альпинисту завязали глаза и сказали, что он должен добраться до вершины "унимодальной" горы. Даже ничего не видя, он может это сделать, если все время будет двигаться вверх. Хотя любая ведущая вверх тропа в конечном счете приведет его к вершине, кратчайшей из них будет самая крутая, если, правда, альпинист не натолкнется на вертикальный обрыв, который придется обходить. (Математическим эквивалентом обрыва на поверхности, образуемой целевой функцией, являются те ее места, где поставлены условные ограничения) Предположим пока, что задача оптимизации не содержит ограничений.
Позднее мы включим их в схему поиска.
Метод оптимизации, в основу которого положена идея движения по самой крутой тропе, называется методом наискорейшего подъема или наискорейшего спуска. Вектор градиента перпендикулярен линии уровня и указывает направление к новой точке в пространстве проектирования.
Отметим, что градиентный метод в отличие от метода касательной к линии уровня можно использовать применительно к любой унимодальной функции, а не только тех, у которых это свойство явно выражено. Чтобы лучше понять идею градиентных методов, подробнее остановимся на свойствах градиентов. Рассмотрим систему независимых единичных векторов e  ,e
,e  ,e
,e  ,…,e
,…,e  , направленных вдоль осей координат x ,x ,x ,…,x , являющихся в то же время проектными параметрами.
, направленных вдоль осей координат x ,x ,x ,…,x , являющихся в то же время проектными параметрами.
Вектор градиента произвольной целевой функции F (x  ,x
,x  ,x ,…,x
,x ,…,x  ) имеет вид:
) имеет вид:
(¶F/¶x ) e + (¶F/¶ x ) e +…. + (¶F/ ¶ x ) e ,
где частные производные вычисляются в рассматриваемой точке. Этот вектор направлен вверх, в направлении подъема; обратный ему вектор указывает направление спуска. Единичный вектор градиента часто представляют в виде v e +v e +v e +…+v e , где
v  =
= 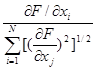 .
.
Иногда характер целевой функции бывает достаточно хорошо известен, чтобы можно было вычислить компоненты вектора градиента путем непосредственного дифференцирования. Если таким способом частные производные получить не удается, то можно найти их приближенные значения в непосредственной окрестности рассматриваемой точки:

Здесь D - небольшое смещение в направлении x . Эту формулу часто называют "приближением секущей". Полученную информацию о направлении градиента можно использовать различным образом для построения алгоритма поиска.
Один из возможных примеров алгоритмов.
f (x) - > min, xÎ Rn
x0-начальное приближение (массив [1: n])
Будем считать, что нам известна функция
minf (j (q)), которая вычисляется qmin: j (qmin) =min j (q)
r: =f (x0); r1: =r+2*e; x: =x0;
Пока abs (r-r1) >= e
нц
r1: =r;
x1: =x;
Для i от 1 до n
нц
l [i]: = ¶f (x1) / ¶x [i];
x [i]: =x [i] +q*l [i];
кц
j (q): =f (x);
qmin: = minf (j (q));
x: =x1;
Для i от 1 до n
x [i]: =x [i] +qmin*l [i];
кц
r: =f (x);
кц