В качестве примеров рассмотрим наиболее известные классы задач, для решения которых в настоящее время широко применяются нейросетевые технологии.
Прогнозирование.
 Прогноз будущих значений переменной, зависящей от времени, на основе предыдущих значений ее и/или других переменных. В финансовой области, это,например, прогнозирование курса акций на 1 день вперед,
Прогноз будущих значений переменной, зависящей от времени, на основе предыдущих значений ее и/или других переменных. В финансовой области, это,например, прогнозирование курса акций на 1 день вперед,
или прогнозирование изменения курса валют на определен
ный период времени и т.д.. (рис 1.6)
Распознавание или классификация.
Определение, к какому из заранее известных классов принадлежит тестируемый объект. Следует отметить, что задачи классификации очень плохо алгоритмизируются. Если в случае распознавания букв верный ответ очевиден для нас заранее, то в более сложных практических задачах обученная нейросеть выступает как эксперт, обладающий большим опытом и способный дать ответ на трудный вопрос.
 Примером такой задачи служит
Примером такой задачи служит
медицинская диагностика, где сеть может
учитывать большое количество числовых
параметров (энцефалограмма, давление, вес и т.д.).
Конечно, "мнение" сети в этом случае нельзя
считать окончательным.
 Классификация предприятий по степени их перспективности (рис 1.8) - это уже привычный способ использования нейросетей в практике крупных компаний. При этом сеть также использует множество
Классификация предприятий по степени их перспективности (рис 1.8) - это уже привычный способ использования нейросетей в практике крупных компаний. При этом сеть также использует множество
экономических показателей,
сложным образом связанных
между собой.
Кластеризацию и поиск закономерностей.
Помимо задач классификации, нейросети широко используются для поиска зависимостей в данных и кластеризации.
Например, нейросеть на основе методики МГУА (метод группового учета аргументов) позволяет на основе обучающей выборки построить зависимость одного параметра от других в виде полинома (рис. 1.9). Такая сеть может не только мгновенно выучить таблицу умножения, но и найти сложные скрытые зависимости в данных (например, финансовых), которые не обнаруживаются стандартными статистическими методами.
 |
Кластеризация - это разбиение набора примеров на несколько компактных областей (кластеров), причем число кластеров заранее неизвестно (рис. 1.10). Кластеризация позволяет представить неоднородные данные в более наглядном виде и использовать далее для исследования каждого кластера различные методы. Например, таким образом можно быстро выявить фальсифицированные страховые случаи или недобросовестные предприятия.
 |
Несмотря на большие возможности, существует ряд недостатков, которые все же ограничивают применение нейросетевых технологий. Во-первых, нейронные сети позволяют найти только субоптимальное решение, и соответственно они неприменимы для задач, в которых требуется высокая точность. Функционируя по принципу черного ящика, они также неприменимы в случае, когда необходимо объяснить причину принятия решения. Обученная нейросеть выдает ответ за доли секунд, однако относительно высокая вычислительная стоимость процесса обучения как по времени, так и по объему занимаемой памяти также существенно ограничивает возможности их использования. И все же класс задач, для решения которых эти ограничения не критичны, достаточно широк.
2. Постановка задачи классификации сейсмических сигналов.
Международная система мониторинга (МСМ), сформировавшаяся в мире за последние десятилетия, предназначена для наблюдения за сейсмически активными регионами. Основная часть информации фиксируется на одиночных сейсмических станциях. Дальнейшая обработка этой информации позволяет оценить различные физические параметры, характеризующие записанное событие. Соответственно чем информативнее записанный сигнал, тем больше всевозможных параметров можно определить и точнее. Относительно недавно для наблюдения стали использовать группы сейсмических станций. Наиболее широкое применение получили малоапертурные группы с диаметром приблизительно 3 км. за счет того, что в этом случае можно пренебречь искажениями сигнала, возникающими из-за неоднородности земной поверхности.
Причина использования сейсмических групп также заключается в том, что при таком методе наблюдения можно применять специальные алгоритмы комплексной обработки регистрируемой многоканальной сейсмограммы, которые обеспечивают лучшее качество оценки параметров записанной информации, в сравнении с одиночными сейсмическими станциями.
Одна из многочисленных задач, возникающих при региональном мониторинге, это задача идентификации типа сейсмического источника или задача классификации сейсмических сигналов. Она состоит в том, чтобы по сейсмограмме определить причину возникновения зафиксированного события, т.е. различить взрыв и землетрясение. Ее решение предусматривает разработку определенного метода (решающего правила), который с определенной вероятностью мог бы отнести записанное событие к одному из двух классов. На рис.2.1 представлена схема постановки задачи.
 |
Для решения этой задачи в настоящее время применяются различные аналитические методы из теории статистического анализа, позволяющие с высокой вероятностью правильно классифицировать данные. Как правило, для конкретного региона существует своя база данных записанных событий. Она включает в себя пример сейсмограмм характеризующих как землетрясения, так и взрывы произошедшие в этом регионе с момента начала наблюдения. Все существующие методы идентификации используют эту базу данных в качестве обучающего множества, тем самым, улавливая тонкие различия характерные для данного региона, методы, настраивают определенным образом свои параметры и в итоге учатся классифицировать все обучающее множество на принадлежность к одному из двух классов.
Один из наиболее точных методов основан на выделении дискриминантных признаков из сейсмограмм и последующей классификации векторов признаков с помощью статистических решающих правил. Размерность таких векторов соответствует количеству признаков, используемых для идентификации и, как правило, не превышает нескольких десятков.
Математическая постановка в этом случае формулируется как задача разделения по обучающей выборке двух классов и ставится так: имеется два набора векторов (каждый вектор размерности N): X1,…,Xp1 и Y1,…Yp2. Заранее известно, что Xi (i=1,…,p1) относится к первому классу, а Yj (j=1,…,p2) - ко второму. Требуется построить решающее правило, т.е. определить такую функцию f, что при f(x) > 0 вектор x относился бы к первому классу, а при f(x) < 0 - ко второму, где xÍ{X1,…, Xp1, Y1,…, Yp2}.
3. Статистическая методика решения задачи классификации.
В данном разделе рассматривается методика определения типов сейсмических событий, основанная на выделении дискриминантных признаков из сейсмограмм и последующей классификации векторов признаков с помощью статистических решающих правил.[8]
3.1 Выделение информационных признаков из сейсмограмм.
Исходные данные представлены в виде сейсмограмм (рис. 3.1) – это временное отображение колебаний земной поверхности.
 |
В таком виде анализировать информацию, оценивать различные физические характеристики зафиксированного события достаточно трудно. Существуют различные методы, специально предназначенные для обработки сигналов, которые позволяют выделять определенные признаки, и, в дальнейшем, по ним производить анализ записанного события.
Как правило, в большинстве из этих методов на начальном этапе выполняется следующий набор операций:
1. Из всей сейсмограммы выделяется часть («временное окно»), которое содержит информацию о какой-то отдельной составляющей сейсмического события, например, только о P-волне.
2. Для выделенных данных последовательно применяется такие процедуры как:
а) Быстрое (дискретное) преобразование Фурье (БПФ);
б) Затем накладываются характеристики определенного фильтра, например, фильтра Гаусса.
в) Обратное преобразование Фурье (ОБПФ), для того чтобы получить отфильтрованный сигнал.
Далее, применяются различные алгоритмы для формирования определенного признака. В частности, можно легко найти максимальную амплитуду колебания сигнала, характеристику определяемую выражением max{peakMax – peakMin }. Определив данный параметр для частоты f1 допустим для P волны, а также для частоты f2 для S волны можно найти их отношение P(f1)/S(f2), и использовать его в качестве дискриминационного признака.
Применяя другие алгоритмы, можно построить большое количество таких признаков. Однако, для задачи идентификации типа сейсмического события, важными являются далеко не все. Из наиболее информативных можно выделить такие признаки, как отношение амплитуд S и P волн, или доля мощности S фазы на высоких (низких) частотах по отношению к мощности S фазы во всей полосе частот.
Как правило, максимальное количество признаков, которое используется для этой задачи составляет около 25 – 30.
3.2 Отбор наиболее информативных признаков для идентификации.
Как было показано выше, в сейсмограмме анализируемого события можно выделить достаточно много различных характеристик, однако, далеко не все из них могут действительно нести информацию, существенную для надежной идентификации взрывов и землетрясений. Многочисленные исследования в дискримининтном анализе показали, что выделение малого числа наиболее информативных признаков исключительно важно для эффективной классификации. Несколько тщательно отобранных признаков могут обеспечить вероятность ошибочной классификации существенно меньшую, чем при использовании полного набора.
Ниже представлена процедура отбора наиболее информативных дискриминантных признаков, осуществляемая на основании обучающих реализаций землетрясений и взрывов из данного региона.[8]
В начале каждый вектор x sj = (x(i)sj, iÎ1,p); где sÎ1,2 - номер класса (s=1 - землетрясения s=2 - взрывы), jÎ1,ns, ns -число обучающих векторов данного класса состоит из p признаков, выбранных из эвристических соображений как предположительно полезные для данной проблемы распознавания. При этом число p может быть достаточно велико и даже превышать число имеющихся обучающих векторов в каждом из классов, но для устойчивости вычислений должно выполняться условие p < n1+n2. Процедура отбора признаков - итерационная и состоит из p шагов на каждом из которых число отобранных признаков увеличивается на единицу. На каждом промежуточном k -м шаге процедура работает с n1+n2 k -мерными векторами x sj(k) (k£p), сформированных из k-1 признаков, отобранных в результате первых k-1 шагов и некоторого нового признака из числа оставшихся. Отбор признаков основан на оценивании по векторам, состоящим из различных признаков, стохастического расстояния Кульбака-Махаланобиса D(k) между распределениями вероятностей векторов x sj(k):
D(k)= (m (k,1) - m (k,2))T S-1n1+n2 (k) (m (k,1) - m (k,2)), (6)
где: m (k,1), m (k,2) k - мерные векторы выборочных средних, вычисленные по k -мерным векторам x 1j(k) jÎ1,n1 и x 2j(k) jÎ1,n2 первого и второго классов; S-1n1+n2 (k) есть (k´k) - мерная обратная выборочная матрица ковариаций, вычисленная с использованием всего набора k - мерных векторов x 1j(k) jÎ1,n1 и x 2j(k) jÎ1,n2
На первом шаге процедуры отбора значения функционала D(1) вычисляются для каждого из p признаков. Максимум из этих p значений достигается на каком то из признаков, который таким образом отбирается как первый информативный. На втором шаге значения функционала D(2) вычисляются уже для векторов, состоящих из пар признаков. Первый элемент в каждой паре - это признак, отобранный на предыдущем шаге, второй элемент пары - один их оставшихся признаков. Таким образом получаются p-1 значения функционала D(2). Второй информативный признак отбирается из условия, что на нем достигается максимум функционала D(2). Далее процедура продолжается аналогично, и на k -м шаге процедуры отбора вычисляются значения функционала D(k) по обучающим векторам, состоящим из k признаков. Первые k-1 компонент этих векторов есть информативные признаки, отобранные на предыдущих k-1 шагах, последняя компонента - один из оставшихся признаков. В качестве k -го информативного признака отбирается тот признак, для которого функционал D(k) -максимален.
Описанная процедура ранжирует порядок следования признаков в обучающих векторах так, чтобы обеспечить максимально возможную скорость возрастания расстояния Махаланобиса (6) с ростом номера признака. Для селекции множества наиболее информативных признаков на каждом шаге k=1,2,...,p описанной выше итерационной процедуры ранжирования признаков по информативности сохраняются номер j(k) в исходной таблице признаков и имя выбранного признака, также вычисляется теоретическое значение полной вероятности ошибки классификации P(k) по формуле Колмогорова-Деева [12].
P(k) = (1/2)[1 - Tk(D(k)/s(k)) + Tk(-D(k)/ s(k))],
где k - число используемых признаков
s2(k) = [(t+1)/t][r1+r2+D(k)]; t = [(r1+r2)/r1r2]-1; r1=k/n1; r2=k/n2 (7)
Tk(z) = F(z) + (1/(k-1)) (a1 - a2H1(z) + a3H2(z) - a4H3(z)) f(z),
F(z) - функция стандартного Гауссовского распределения вероятностей; f(z) - плотность этого распределения; Hi(z) - полином Эрмита степени i, i=1,2,3; aj, j=1,...,4 - некоторые коэффициенты, зависящие от k, n1, n2 и D(k) [12]. Эта формула, как было показано в различных исследованиях, имеет хорошую точность при размерах выборок порядка сотни и rs<0.3, s=1,2.
Функция D(k), получаемая в результате процедуры ранжирования признаков, возрастает с ростом k, однако, на практике ее рост, как правило, существенно замедляется при k® p. В этом случае функция P(k) на каком то шаге k0 между 1 и p имеет минимум. В качестве набора наиболее информативных признаков и принимается совокупность признаков, отобранных на шагах 1,..., k0 описанной выше процедуры. Именно они обеспечивают минимальную полную вероятность ошибочной классификации, которая может быть получена при данных обучающих наблюдениях.
3.3 Процедура статистической идентификации.
В качестве решающего правила используются алгоритмы идентификации, основанные на классических статистических дискриминаторах, таких как линейный и квадратичный дискриминаторы. Данные алгоритмы применяются наиболее часто в виду простоты их использования, удобства обучения применительно к конкретному региону и легкости оценивания вероятности ошибочной идентификации взрывов и землетрясений для каждого конкретного региона Их роль как эффективных правил выбора решения при идентификации особенно возрастает, если применять эти алгоритмы к множествам обучающих и идентифицируемых векторов, составленных из наиболее информативных для данного региона дискриминантных признаков, отобранных в соответствии с описанной выше методикой.
Линейная дискриминантная функция описывается следующей формулой
 . (8)
. (8)
где k - число отобранных наиболее информативных признаков, x (k) - классифицируемый вектор, m (k,1), m (k,2) - k - мерные векторы выборочных средних, вычисленные по k -мерным векторам x 1j(k) jÎ1,n1 и x 2j(k) jÎ1,n2 1го и 2-го классов, S-1n1+n2 (k) - (k´k) - мерная обратная выборочная матрица ковариаций, вычисленная с использованием всего набора k - мерных векторов x 1j(k) jÎ1,n1 и x 2j(k) jÎ1,n2. Если LDF > 0, то принимается, что вектор x (k) принадлежит первому классу - (землетрясение); в противоположном случае он принадлежит второму класс (взрыв).
Квадратичная дискриминационная функция описывается следующей формулой
 (9)
(9)
где  , s=1,2 - обратные матрицы ковариаций обучающих выборок 1 -го и 2 -го классов, вычисленные по обучающим векторам x 1j(k) jÎ1,n1 и x 2j(k) jÎ1,n2, соответственно.
, s=1,2 - обратные матрицы ковариаций обучающих выборок 1 -го и 2 -го классов, вычисленные по обучающим векторам x 1j(k) jÎ1,n1 и x 2j(k) jÎ1,n2, соответственно.
3.4 Оценка вероятности ошибочной классификации методом скользящего экзамена.
Оценивание вероятности ошибочной идентификации типа событий (землетрясение-взрыв), в каждом конкретном регионе представляет собой одну из основных практических задач мониторинга. Эту задачу приходится решать на основании накопления региональных сейсмограмм событий, о которых доподлинно известно, что они порождены землетрясениями или взрывами. Эти же сейсмограммы представляют собой "обучающие данные" для адаптации решающих правил.
Из теории распознавания образов известно, что наиболее точной и универсальной оценкой вероятности ошибок классификации является оценка, обеспечиваемая процедурой “скользящего экзамена”(“cross-validation”) [11].
В методе скользящего экзамена на каждом шаге один из обучающих векторов x sj, jÎ1,ns, sÎ1,2, исключается из обучающей выборки. Оставшиеся векторы используются для адаптации (обучения) LDF или QDF или любого другого дискриминатора. Исключенный вектор затем классифицируется с помощью дискриминатора, обученного без его участия. Если этот вектор классифицируется неправильно, т.е. относится к классу 2 вместо класса 1 или наоборот, соответствующие “счетчики” n12 или n21 увеличиваются на 1. Исключенный вектор затем возвращается в обучающую выборку, а изымается уже другой вектор x s(j+1). Процедура повторяется для всех nl + n2 обучающих векторов. Вычисляемая в результате величина
p0=(n12 +n21)/(nl +n2 )
является состоятельной оценкой полной вероятности ошибочной классификации. Значения дискриминатора, полученные в результате процедуры скользящего экзамена для обоих классов, ранжируются по амплитуде: ранжированные последовательности удобнее сравнивать с порогом и делать выводы о “физических” причинах ошибочной классификации.
4. Обзор различных архитектур нейронных сетей, предназначенных для задач классификации.
Приступая к разработке нейросетевого решения, как правило, сталкиваешься с проблемой выбора оптимальной архитектуры нейронной сети. Так как области применения наиболее известных парадигм пересекаются, то для решения конкретной задачи можно использовать совершенно различные типы нейронных сетей, и при этом результаты могут оказаться одинаковыми. Будет ли та или иная сеть лучше и практичнее, зависит в большинстве случаев от условий задачи. Так что для выбора лучшей приходится проводить многочисленные детальные исследования.
Рассмотрим ряд основных парадигм нейронных сетей, успешно применяемых для решения задачи классификации, одна из постановок которой представлена в данной дипломной работе.
4.1 Нейрон – классификатор.
Простейшим устройством распознавания образов в нейроинформатике является одиночный нейрон (рис. 4.1), превращающий входной вектор признаков в скалярный ответ, зависящий от линейной комбинации входных переменных [1-5, 7,10]:
 | |||
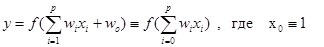 |
Скалярный выход нейрона можно использовать в качестве т.н. дискриминантной функции. Этим термином называют индикатор принадлежности входного вектора к одному из заданных классов, а нейрон соответственно – линейным дискриминатором. Так, если входные вектора могут принадлежать одному из двух классов, можно различить тип входа, например, следующим образом: если f(x) ³ 0, входной вектор принадлежит первому классу, в противном случае – второму. Рассмотрим алгоритм обучения подобной структуры, приняв f(x)ºx.
Итак, в p-мерном пространстве задана обучающая выборка x1,…,xn (первый класс) и y1,…,ym (второй класс). Требуется найти такие p+1- мерный вектор w, что для всех i=1,…,n и j=1,…,m w0+(xi,w)>0 и w0+(yj,w)<0.
Переформулируем задачу, сведя ее к отделению нуля от конечного множества векторов в p+1 - мерном пространстве. Для этого рассмотрим p+1 – мерные векторы zl (l=0, 1,…., n+m):
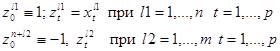 |
В этих обозначениях условия разделения превращаются в систему n+m однотипных неравенств:
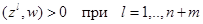 |
В качестве нулевого приближения можно выбрать любой вектор w, например, w=0, или wÍR[-0.5,0.5]. Цикл алгоритма состоит в том, что для всех l = 1,…,n+m проверяется неравенство (zl,w) > 0. Если для данного l £ n+m оно выполнено, переходим к следующем l (либо при l=n+m заканчиваем цикл), если же не выполнено, то модифицируем w по правилу w=w+zl, или w=w+hTzl, где T – номер модификации, а  , например.
, например.
Когда за весь цикл нет ни одной ошибки (т.е. модификации w), то решение w найдено, в случае же ошибок полагаем l=1 и снова проходим цикл.
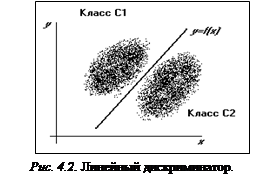
В некоторых простейших случаях линейный дискриминатор – наилучший из возможных, а именно когда оба класса можно точно разделить одной гиперплоскостью, рисунок 4.2 демонстрирует эту ситуацию для плоскости, когда p=2.
 |
4.2 Многослойный персептрон.
Возможности линейного дискриминатора весьма ограничены. Для решения более сложных классификационных задач необходимо усложнить сеть вводя дополнительные (скрытые) слои нейронов, производящих промежуточную предобработку входных данных, таким образом, чтобы выходной нейрон-классификатор получал на свои входы уже линейно-разделимые множества. Такие структуры носят название многослойные персептроны [1-4,7,10] (рис. 1.3).
Легко показать, что, в принципе, всегда можно обойтись одним скрытым слоем, содержащим, достаточно большое число нейронов. Действительно, увеличение скрытого слоя повышает размерность пространства, в котором выходной нейрон производит классификацию, что, соответственно, облегчает его задачу.
Персептроны весьма популярны в нейроинформатике. И это обусловлено, в первую очередь, широким кругом доступных им задач, в том числе и задач классификации, распознавания образов, фильтрации шумов, предсказание временных рядов, и т.д., причем применение именно этой архитектуры в ряде случаев вполне оправдано, с точки зрения эффективности решения задачи.
Рассмотрим какие алгоритмы обучения многослойных сетей разработаны и применяются в настоящее время.[7,10]. В основном все алгоритмы можно разбить на две категории:
· Градиентные алгоритмы;
· Стохастические алгоритмы.
К первой группе относятся те, которые основаны на вычислении производной функции ошибки и корректировке весов в соответствии со значением найденной производной. Каждый дальнейший шаг направлен в сторону антиградиента функции ошибки. Основу всех этих алгоритмов составляет хорошо известный алгоритм обратного распространения ошибки (back propagation error).[1-5,7,10].
 ,где функция ошибки
,где функция ошибки 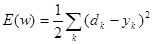
Многочисленные модификации, разработанные в последнее время, позволяют существенно повысить эффективность этого алгоритма. Из них наиболее известными являются:
1. Обучение с моментом.[4,7]. Идея метода заключается в добавлении к величине коррекции веса значения пропорционального величине предыдущего изменения этого же весового коэффициента.

2. Автономный градиентный алгоритм (Обучение с автоматическим изменением длины шага h). [10]
3. RPROP (от resilient –эластичный), в котором каждый вес имеет свой адаптивно настраиваемый темп обучения.[4]
4. Методы второго порядка, которые используют не только информацию о градиенте функции ошибки, но и информацию о вторых производных.[3,4,7].
Стохастические методы обучения выполняют псевдослучайные изменения величин весов, сохраняя те изменения, которые ведут к улучшениям характеристик сети. К этой группе алгоритмов относятся такие как
1. Алгоритм поиска в случайном направлении.[10]
2. Больцмановское обучение или (алгоритм имитации отжига). [1]
3. Обучение Коши, как дополнение к Больцмановскому обучению.[1]
Основным недостатком этой группы алгоритмов является очень долгое время обучения, а соответственно и большие вычислительные затраты. Однако, как пишут в различных источниках, эти алгоритмы обеспечивают глобальную оптимизацию, в то время как градиентные методы в большинстве случаев позволяют найти только локальные минимумы функционала ошибки.
Известны также алгоритмы, которые основаны на совместном использовании обратного распространения и обучения Коши. Коррекция весов в таком комбинированном алгоритме состоит из двух компонент: направленной компоненты, вычисляемой с использованием алгоритма обратного распространения, и случайной компоненты, определяемой распределением Коши. Однако, несмотря на хорошие результаты, эти методы еще плохо исследованы.
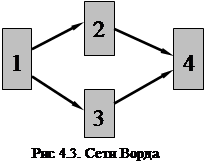
4.3 Сети Ворда.
Одним из вариантов многослойного персептрона являются нейронные сети Ворда. Они способны выделять различные свойства в данных, благодаря наличию в скрытом слое нескольких блоков, каждый из которых имеет свою передаточную функцию (рис.4.4). Передаточные функции (обычно сигмоидного типа) служат для преобразования внутренней активности нейрона. Когда в разных блоках скрытого слоя используются разные передаточные функции, нейросеть оказывается способной выявлять новые свойства в предъявляемом образе. Для настройки весовых коэффициентов используются те же алгоритмы, о которых говорилось в предыдущем разделе.
 |
4.2 Сети Кохонена.
Сети Кохонена – это одна из разновидностей нейронных сетей, для настройки которой используется алгоритм обучения без учителя. Задачей нейросети Кохонена является построение отображения набора входных векторов высокой размерности на карту кластеров меньшей размерности, причем таким образом, что близким кластерам на карте отвечают близкие друг к другу входные векторы в исходном пространстве.
Сеть состоит из M нейронов, образующих, как правило одномерную или двумерную карту (рис. 4.2). Элементы входных сигналов {xi} подаются на входы всех нейронов сети. В процессе функционирования (самоорганизации) на выходе слоя Кохонена формируются кластеры (группа активных нейронов определённой размерности, выход которых отличен от нуля), характеризующие определённые категории входных векторов (группы входных векторов, соответствующие одной входной ситуации). [9]
 |
Алгоритм Кохонена формирования карт признаков.
Шаг 1. Инициализировать веса случайными значениями. Задать размер окрестности s(0), и скорость h(0) и tmax.
Шаг 2. Задать значения входных сигналов (x1,…,xp).
Шаг 3. Вычислить расстояние до всех нейронов сети. Расстояния dk от входного сигнала x до каждого нейрона k определяется по формуле:

где
xi - i-ый элемент входного сигнала,
wki - вес связи от i-го элемента входного сигнала к нейрону k.
Шаг 4. Найти нейрон – победитель, т.е. найти нейрон j, для которого расстояние dj наименьшее:
j:dj < dk "k¹p
Шаг 5. Подстроить веса победителей и его соседей.
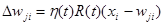

Шаг 6. Обновить размер окрестности s(t) и скорость h(t)
s(t)=s(0)(1-t/tmax) h(t)=h(0)(1-t/tmax)
Шаг 7. Если (t < tmax), то Шаг 2, иначе СТОП.
Благодаря своим способностям к обобщению информации, карты Кохонена являются удобным инструментом для наглядного представления о структуре данных в многомерном входном пространстве, геометрию которого представить практически невозможно.
Сети встречного распространения.
Еще одна группа технических применений связана с предобработкой данных. Карта Кохонена группирует близкие входные сигналы Х, а требуемая функция Y = G(X) строится на основе обычной нейросети прямого распространения (например многослойного персептрона или линейной звезды Гроссберга[1]) к выходам нейронов Кохонена. Такая гибридная архитектура была предложена Р. Хехт-Нильсеном и имеет название сети встречного распространения [1-3,7,9]. Нейроны слоя Кохонена обучаются без учителя, на основе самоорганизации, а нейроны распознающих слоев адаптируются с учителем итерационными методами. Пример такой структуры для решения задачи классификации сейсмических сигналов приведен на рис. 4.5.

Второй уровень нейросети используется для кодирования информации. Весовые коэффициенты tij (i =1,...,M; j=1,2) – коэффициенты от i-го нейрона слоя Кохонена к j-му нейрону выходного слоя рассчитываются следующим образом:

где
Yi – выход i- го нейрона слоя Кохонена
Sj – компонента целевого вектора (S={0,1} – взрыв, S={1,0}-землетрясение)
Таким образом после предварительного обучения и формирования кластеров в слое Кохонена, на фазе вторичного обучения все нейроны каждого полученного кластера соединяются активными (единичными) синапсами со своим выходным нейроном, характеризующим данный кластер.
Выход нейронов второго слоя определяется выражением:
(11) 
где: 
Kj - размерность j-ого кластера, т.е. количество нейронов слоя Кохонена соединённых с нейроном j выходного слоя отличными от нуля коэффициентами.
R - пороговое значение (0 < R < 1).
Пороговое значение R можно выбрать таким образом, чтобы с одной стороны не были потеряны значения активированных кластеров, а с другой стороны - отсекался "шум не активизированных кластеров".
В результате на каждом шаге обработки исходных данных на выходе получаются значения Sj, которые характеризуют явление, породившее данную входную ситуацию (- землетрясение; - взрыв).
4.5 Выводы по разделу.
Итак, подводя итог данной главе, следует сказать, что это далеко не полный обзор нейросетевых архитектур, которые успешно справляются с задачами классификации. В частности ничего не было сказано о вероятностных нейронных сетях, о сетях с базисно радиальными функциями, о использовании генетических алгоритмов для настройки многослойных сетей и о других, пусть менее известных, но хорошо себя зарекомендовавших. Соответственно проблема выбора наиболее оптимальной архитектуры для решения задачи классификации сейсмических сигналов вполне актуальна. В идеале, конечно хотелось бы проверить эффективность хотя бы нескольких из них и выбрать наилучшую. Но для этого необходимо проводить более масштабные исследования, которые займут много времени. На данном этапе исследований была сделана попытка использовать хорошо изученные нейронные сети и алгоритмы обучения для того, чтобы убедиться в эффективности подхода в целом. В главе 6 детально обсуждаются нейросеть, которая была исследована в рамках настоящей дипломной работы.