Принципы эконометрики.
1. принцип правильной постановки проблемы;
2. принцип системной направленности эконометрических расчетов;
3. принцип учета рыночной неопределенности;
4. принцип улучшения имеющихся альтернатив и поиска новых.
Основные эконометрические методы.
1. сводка и группировка информации;
Статистическая сводка - это научно организованная обработка материалов наблюдения, включающая в себя систематизацию, группировку данных, составление таблиц, подсчет итогов, расчет производных показателей (средних, относительных величин). Статистическая группировка - это процесс образования однородных групп на основе расчленения статистической совокупности на части или объединения изучаемых единиц в частные совокупности по существенным для них признакам.
2. вариационный и дисперсионный анализ;
Дисперсия признака - это средний квадрат отклонений вариантов от их средней величины.В эконометрических расчетах, как правило, используют общую, межгрупповую и внутригрупповую дисперсии. При этом общая дисперсия характеризует вариацию признака в статистической совокупности в результате влияния всех факторов. Межгрупповая дисперсия показывает размер отклонения групповых средних от общей средней, то есть характеризует влияние фактора, положенного в основание группировки. Внутригрупповая (остаточная) дисперсия характеризует вариацию признака в середине каждой группы статистической группировки. В эконометрических расчетах используется среднее квадратическое отклонение - обобщающая характеристика размеров вариации признака в совокупности. Оно равно корню квадратному из дисперсии. Для осуществления сравнений колеблемости одного и того же признака в нескольких совокупностях используется относительный показатель вариации — коэффициент вариации.
2. регрессионный и корреляционный анализ;
Применение метода наименьших, квадратов (МНК) позволяет получить достаточно точные теоретические значения модели однофакторной регрессии и соответственно ее графическое изображение (термин "регрессия" - движение назад, возвращение в прежнее состояние, - был введен Фрэнсисом Галтоном в конце XIX века при анализе зависимости между ростом родителей и ростом детей; в любом случае средний рост детей - и у низких, и у высоких родителей -стремится (возвращается) к среднему росту людей в данном регионе).
3. статистические уравнения зависимости;
4. статистические индексы и др.
Статистические индексы могут быть использованы в качестве меры изменения количества независимо от изменения качественного признака (цены, себестоимости, производительности труда и т.п.), а также для характеристики качественного признака независимо от изменения количества (объема продукции в натуральном выражении, численности работников и т.п.).
2. Спецификация модели парной регрессии
В зависимости от количества факторов, включенных в уравнение регрессии, принято различать простую (парную) и множественную регрессию.
Парная регрессия – регрессия между двумя переменными y и x, т.е. модель вида

где y – зависимая переменная (результативный признак);
x – независимая, объясняющая переменная (признак-фактор).
Спецификация модели – формулировка вида модели, исходя из соответствующей теории связи между переменными. Со спецификации модели начинается любое эконометрическое исследование. Иными словами, исследование начинается с теории, устанавливающей связь между явлениями.
Прежде всего, из круга факторов, влияющих на результативный признак, необходимо выделить наиболее существенно влияющие факторы. Парная регрессия достаточна, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной. В уравнении регрессии корреляционная по сути связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией

где yj — фактическое значение результативного признака;
yxj —теоретическое значение результативного признака.
 — случайная величина, характеризующая отклонения реального значения результативного признака от теоретического.
— случайная величина, характеризующая отклонения реального значения результативного признака от теоретического.
Случайная величина ε называется также возмущением. Она включает влияние неучтенных в модели факторов, случайных ошибок и особенностей измерения.
От правильно выбранной спецификации модели зависит величина случайных ошибок: они тем меньше, чем в большей мере теоретические значения результативного признака подходят к фактическим данным у.
К ошибкам спецификации относятся неправильный выбор той или иной математической функции для  , и недоучет в уравнении регрессии какого-либо существенного фактора, т. е. использование парной регрессии вместо множественной.
, и недоучет в уравнении регрессии какого-либо существенного фактора, т. е. использование парной регрессии вместо множественной.
Наряду с ошибками спецификации имеет место ошибка выборки - исследователь чаще всего имеет дело с выборочными данными при установлении закономерной связи между признаками. Ошибки измерения практически сводят на нет все усилия по количественной оценке связи между признаками.
Основное внимание в эконометрических исследованиях уделяется ошибкам спецификации модели. В парной регрессии выбор вида математической функции  может быть осуществлен тремя способами: графическим; аналитическим (исходя из теории изучаемой взаимосвязи) и экспериментальным.
может быть осуществлен тремя способами: графическим; аналитическим (исходя из теории изучаемой взаимосвязи) и экспериментальным.
Графический метод основан на поле корреляции. Аналитический метод основан на изучении материальной природы связи исследуемых признаков. Экспериментальный метод осуществляется путем сравнения величины остаточной дисперсии Dост, рассчитанной при разных моделях. Если фактические значения результативного признака совпадают с теоретическими  то Docm =0. Если имеют место отклонения фактических данных от теоретических
то Docm =0. Если имеют место отклонения фактических данных от теоретических  то
то 
Чем меньше величина остаточной дисперсии, тем лучше уравнение регрессии подходит к исходным данным.
Если остаточная дисперсия оказывается примерно одинаковой для нескольких функций, то на практике предпочтение отдается более простым видам функций, ибо они в большей степени поддаются интерпретации и требуют меньшего объема наблюдений. Число наблюдений должно в 6 — 7 раз превышать число рассчитываемых параметров при переменной х.
3.Линейная регрессия и корреляция
Линейная регрессия находит широкое применение в эконометрике ввиду четкой экономической интерпретации ее параметров.
Линейная регрессия сводится к нахождению уравнения вида
 или
или  .
.
Уравнение вида позволяет по заданным значениям фактора x находить теоретические значения результативного признака, подставляя в него фактические значения фактора x.
Построение линейной регрессии сводится к оценке ее параметров – a и b. Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров a и b, при которых сумма квадратов отклонений фактических значений результативного признака y от теоретических  минимальна:
минимальна:

Чтобы найти минимум функции, надо вычислить частные производные по каждому из параметров a и b и приравнять их к нулю.
Обозначим  через S(a,b):
через S(a,b):  , тогда
, тогда

После несложных преобразований, получим следующую систему линейных уравнений для оценки параметров a и b:

Решая систему уравнений, найдем искомые оценки параметров a и b:
 ,
,
 , где
, где  .
.
Так как  , то
, то 
Параметр b называется коэффициентом регрессии. Он имеет смысл показателя силы связи между вариацией x и вариацией y. Его величина показывает среднее изменение результата с изменением фактора на одну единицу.
Коэффициент a может не иметь экономического содержания, интерпретировать можно только знак, он показывает направления связи.
Уравнение регрессии всегда дополняется показателем тесноты связи. При использовании линейной регрессии в качестве такого показателя выступает линейный коэффициент корреляции rxy, который можно рассчитать по следующим формулам:

Линейный коэффициент корреляции находится в пределах: -1£rxy£1.
Если r>0, то прямая связь
Если r<0, то обратная связь
Если |r|³0,7, то сильная связь
Если 0,5£|r|<0,7, то умеренная связь
Если |r|<0,5, то слабая связь
Если b>0, то 0£rxy£1, если b<0, то -1£rxy£0.
4. Прогнозирование по линейному уравнению регрессии
Пусть требуется оценить прогнозное значение признака-результата для заданного значения признака-фактора  .
.
Прогнозируемое значение признака-результата с доверительной вероятностью равной (1-a) принадлежит интервалу прогноза:

где  - точечный прогноз;
- точечный прогноз;
t - коэффициент доверия, определяемый по таблицам распределения Стьюдента в зависимости от уровня значимости a и числа степеней свободы (n-2);
 - средняя ошибка прогноза.
- средняя ошибка прогноза.
Точечный прогноз рассчитывается по линейному уравнению регрессии:
 .
.
Средняя ошибка прогноза в свою очередь:

5. Нелинейная регрессия.
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы, параболы второй степени и др.
Различают два класса нелинейных регрессий:
§ регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
§ регрессии, нелинейные по оцениваемым параметрам.
Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
· полиномы разных степеней – у = а + bх + с2 + ε,
у = а + bх + сх + dx3 + ε,
§ равносторонняя гипербола 
К нелинейным регрессиям по оцениваемым параметрам относятся функции:
§ степенная — y = axb ε
§ показательная – у = аbх ε
§ экспоненциальная – y = ea+bx ε
6. Спецификация модели множественной регрессии.
Парная регрессия может дать хороший результат при моделировании, если влиянием других факторов, воздействующих на объект исследования, можно пренебречь. Поведение отдельных экономических переменных контролировать нельзя, т. е. не удается обеспечить равенство всех прочих условий для оценки влияния одного исследуемого фактора. В этом случае следует попытаться выявить влияние других факторов, введя их в модель, т. е. построить уравнение множественной регрессии: 
Такого рода уравнение может использоваться при изучении потребления. Тогда коэффициенты  — частныепроизводные потребления
— частныепроизводные потребления  по соответствующим факторам
по соответствующим факторам  :
:

в предположении, что все остальные постоянны.
В 30-е гг. XX в. Кейнс сформулировал свою гипотезу потребительской функции. С того времени исследователи неоднократно обращались к проблеме ее совершенствования. Современная потребительская функция чаще всего рассматривается как модель вида:

где С — потребление; у — доход; Р — цена, индекс стоимости жизни; М — наличные деньги; Z — ликвидные активы.
При этом 
Множественная регрессия широко используется в решении проблем спроса, доходности акций; при изучении функции издержек производства, в макроэкономических расчетах и целого ряда других вопросов эконометрики. В настоящее время множественная регрессия – один из наиболее распространенных методов эконометрики. Основная цель множественной регрессии — построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель.
Построение уравнения множественной регрессия начинается с решения вопроса о спецификации модели. Спецификация модели включает в себя два круга вопросов: отбор факторов и выбор вида уравнения регрессии.
Требования к факторам.
1 Они должны быть количественно измеримы.
2.Факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи.
Разновидностью интеркоррелированности факторов является мультиколлинеарность - наличие высокой линейной связи между всеми или несколькими факторами.
Причинами возникновения мультиколлинеарности между призанками являются:
1. Изучаемые факторные признаки, характеризуют одну и ту же сторону явления или процесса. Например, показатели объема производимой продукции и среднегодовой стоимости основных фондов одновременно включать в модель не рекомендуется, так как они оба характеризуют размер предприятия;
2. Использование в качестве факторных признаков показателей, суммарное значение которых представляет собой постоянную величину;
3. Факторные признаки, являющиеся составными элементами друг друга;
4. Факторные признаки, по экономическому смыслу дублирующие друг друга.
5. Одним из индикаторов определения наличия мультиколлинеарности между признаками является превышение парным коэффициентом корреляции величины 0,8 (rxi xj) и др.
7. Построение линейного уравнения множественной регрессии
8. Уравнение регрессии в стандартизированном виде.
9. Показатели тесноты связи во множественной регрессии
Показатели тесноты связи во множественном регрессионном анализе - парные и частные коэффициенты корреляции.
Корреля́ция — статистическая взаимосвязь двух или нескольких случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом, изменения одной или нескольких из этих величин приводят к систематическому изменению другой или других величин. Математической мерой корреляции двух случайных величин служит коэффициент корреляции.
Корреляция может быть положительной и отрицательной (возможна также ситуация отсутствия статистической взаимосвязи — например, для независимых случайных величин). Отрицательная корреляция — корреляция, при которой увеличение одной переменной связано с уменьшением другой переменной, при этом коэффициент корреляции отрицателен. Положительная корреляция — корреляция, при которой увеличение одной переменной связано с увеличением другой переменной, при этом коэффициент корреляции положителен.
Величина влияния фактора на исследуемый отклик может быть оценена при помощи коэффициента линейной парной корреляции, характеризующего тесноту (силу) линейной связи между двумя переменными.
Коэффициент можно определить по формуле:
 . .
| (6.4) |
Коэффициент обладает следующими свойствами:
1) не имеет размерности, следовательно, сопоставим для величин различных порядков;
2) изменяется в диапазоне от –1 до +1. Положительное значение свидетельствует о прямой линейной связи, отрицательное – об обратной. Чем ближе абсолютное значение коэффициента к единице, тем теснее связь. Считается, что связь достаточно сильная, если коэффициент по абсолютной величине превышает 0,7, и слабая, если он менее 0,3.
Значение коэффициента легко вычисляется при помощи MS Excel (функция КОРРЕЛ).
Величина r2 называется коэффициентом детерминации. Он определяет долю вариации одной из переменных, которая объясняется вариацией другой переменной.
Частный коэффициент корреляции - мера линейной связи между зависимой переменной Y и какой-либо одной из переменных  после удаления влияния на эту связь всех остальных переменных
после удаления влияния на эту связь всех остальных переменных
Укажем один из способов построения частного коэффициента корреляции. Пусть, например, изучается линейная связь между переменными  и требуется найти коэффициент корреляции между зависимой переменной
и требуется найти коэффициент корреляции между зависимой переменной  и независимой переменной
и независимой переменной  , «очищенный» от влияния переменной
, «очищенный» от влияния переменной  .
.
Вычислим парные коэффициенты корреляции  и рассмотрим разность
и рассмотрим разность
 (3.29)
(3.29)
Если переменные и не коррелируют с , то  .Оценивать зависимость с помощью разности (3.29) неудобно. Поэтому ее нормируют так, чтобы получившийся коэффициент был в пределах от – 1 до + 1. В этом случае получаем выражение
.Оценивать зависимость с помощью разности (3.29) неудобно. Поэтому ее нормируют так, чтобы получившийся коэффициент был в пределах от – 1 до + 1. В этом случае получаем выражение
 . (3.30)
. (3.30)
Величина  называется частным коэффициентом корреляции величин и без учета влияния . Если требуется устранить влияние на двух переменных и
называется частным коэффициентом корреляции величин и без учета влияния . Если требуется устранить влияние на двух переменных и  , то по формуле (3.30) вычислим предварительно коэффициенты ,
, то по формуле (3.30) вычислим предварительно коэффициенты ,  ,
,  . Затем вычисляем коэффициент
. Затем вычисляем коэффициент  , (3.31)
, (3.31)
который отражает зависимость между и без учета влияния и . Аналогично поступают в случае любого числа переменных. Можно показать, что коэффициент частной корреляции показывает тесноту связи результирующего признака с одним из факторов при неизменном уровне других факторов.
Частные коэффициенты корреляции имеют те же свойства, что и обычные. При выборе наилучшей модели с их помощью определяют, какая переменная оказывает на переменную выхода наибольшее влияние.
10.Оценка значимости уравнения множественной регрессии и частный F-критерий
Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью F-критерия Фишера:
 , где Dфакт - факторная сумма квадратов на одну степень свободы;
, где Dфакт - факторная сумма квадратов на одну степень свободы;
Dост - остаточная сумма квадратов на одну степень свободы;
R2 - коэффициент (индекс) множественной детерминации;
m – число параметров при переменных х
n – число наблюдений.
Частный F-критерий построен на сравнении прироста факторной дисперсии, обусловленного влиянием дополнительно включенного фактора, с остаточной дисперсией на одну степень свободы по регрессионной модели в целом. Предположим, что оцениваем значимость влияния х1 как дополнительно включенного в модель фактора. Используем следующую формулу:
 , где
, где  - коэффициент множественной детерминации для модели с полным набором факторов;
- коэффициент множественной детерминации для модели с полным набором факторов;
 - тот же показатель, но без включения в модель фактора х1;
- тот же показатель, но без включения в модель фактора х1;
n – число наблюдений
m – число параметров в модели (без свободного члена).
Если оцениваем значимость влияния фактора хn после включения в модель факторов x1,x2, …,xn-1, то формула частного F-критерия определится как
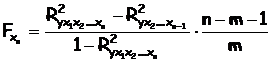
В общем виде для фактора xi частный F-критерий Фишера определится как

Фактическое значение F-критерия Фишера сравнивается с табличным при 5%-ном или 1%-ном уровне значимости и числе степеней свободы: m и n-m-1. Если Fфакт>Fтабл(a,n,n-m-1), то дополнительное включение фактора xi в модель статистически оправданно и коэффициент чистой регрессии bi при факторе xi статистически значим. Если же Fфакт<Fтабл(a,n,n-m-1), то дополнительное включение фактора xi в модель существенно не увеличивает долю объясненной вариации признака y, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
С помощью частного F-критерия Фишера можно проверить значимость всех коэффициентов регрессии в предположении, что каждый соответствующий фактор xi вводился в уравнение множественной регрессии последним.
Если уравнение содержит больше двух факторов, то соответствующая программа ПК дает таблицу дисперсионного анализа, показывая значимость последовательного добавления к уравнению регрессии соответствующего фактора. Так, если рассматривается уравнение
y=a+b1x1+b2x2+ b3x3+ε,
то определяются последовательно F-критерий для уравнения с одним фактором х1, далее F-критерий для дополнительного включения в модель фактора х2, т.е. для перехода от однофакторного уравнения регрессии к двухфакторному, и, наконец, F-критерий для дополнительного включения в модель фактора х3 после включения в модель фактора х1 и х2. В этом случае F-критерий для дополнительного включения фактора х1 после х2 является последовательным в отличие от F-критерия для дополнительного включения в модель фактора х3, который является частным F-критерием, ибо оценивает значимость фактора в предположении, что он включен в модель последним.
11.Понятие и виды систем эконометрических уравнений
Под системой эконометрических уравнений обычно понимается система одновременных, совместных уравнений. Сложные экономические процессы описывают с помощью системы взаимосвязанных уравнений.
Объектом статистического изучения в социальных науках являются сложные системы. Измерение тесноты связей между переменными, построение изолированных уравнений регрессии недостаточны для описания таких систем и объяснения механизма их функционирования. При использовании отдельных уравнений регрессии, например, для экономических расчетов в большинстве случаев предполагается, что аргументы (факторы) можно изменять независимо друг от друга. Однако это предположение является очень грубым: практически изменение одной переменной, как правило, не может происходить при абсолютной неизменности других. Ее изменение повлечет за собой изменения во всей системе взаимосвязанных признаков.
Следовательно, отдельно взятое уравнение множественной регрессии не может характеризовать истинные влияния отдельных признаков на вариацию результирующей переменной. Именно поэтому в экономических, биометрических социологических исследованиях важное место заняла проблема описания структуры связей между переменными системы так называемых одновременных уравнений или структурных уравнений.
Например, если изучается модель спроса как соотношение цен и количества потребляемых товаров, то одновременно для прогнозирования спроса необходима модель предложения товаров, в которой рассматривается также взаимосвязь между количеством и ценой предлагаемых благ. Это позволяет достичь равновесия между спросом и предложением.
Другой пример. При оценке эффективности производства нельзя руководствоваться только моделью рентабельности. Она должна быть дополнена моделью производительности труда, а также моделью себестоимости единицы продукции.
В еще большей степени возрастает потребность в использовании системы взаимосвязанных уравнений, если мы переходим от исследований на микроуровне к макроэкономическим расчетам. Модель национальной экономики включает в себя следующую систему уравнений: функции потребления, инвестиций заработной платы, тождество доходов и т.д. Это связано с тем, что макроэкономические показатели, являясь обобщающими показателями состояния экономики, чаще всего взаимозависимы. Так, расходы на конечное потребление в экономике зависят от валового национального дохода. Вместе с тем величина валового национального дохода рассматривается как функция инвестиций.
Виды систем
Система уравнений в эконометрических исследованиях может быть построена по-разному.
1) Система независимых уравнений, когда каждая зависимая переменная y рассматривается как функция одного и того же набора факторов x:



Набор факторов xi в каждом уравнении может варьировать. Например, модель вида

также является системой независимых уравнений с тем лишь отличием, что набор факторов в ней видоизменяется в уравнениях, входящих в систему. Отсутствие того или иного фактора в уравнении системы может быть следствием как экономической нецелесообразности его включения в модель, так и несущественности его воздействия на результативный признак (незначимо значение t -критерия или F - критерия для данного фактора).
Каждое уравнение системы независимых уравнений может рассматриваться самостоятельно. Для нахождения его параметров используется МНК, каждое уравнение этой системы является уравнением регрессии. Поскольку никогда нет уверенности, что факторы полностью объясняют зависимые переменные, в уравнениях присутствует свободный член a0. Так как фактические значения зависимой переменной отличаются от теоретических на величину случайной ошибки, в каждом уравнении присутствует величина случайной ошибки.
2) Система рекурсивных уравнений – когда зависимая переменная у одного уравнения выступает в виде фактора х в другом уравнении:


В данной системе зависимая переменная у включает в каждое последующее уравнение в качестве факторов все зависимые переменные предшествующих уравнений наряду с набором собственно факторов х. Примером такой системы может служить модель производительности труда и фондоотдачи вида


где у1 - производительность труда;
у2 - фондоотдача;
х1 - фондовооруженность труда;
х2 - энерговооруженность труда;
х3 - квалификация рабочих.
Как и в предыдущей системе, каждое уравнение может рассматриваться самостоятельно, и его параметры определяются методом наименьших квадратов.
3) Система взаимосвязанных уравнений – когда одни и те же зависимые переменные в одних уравнениях входят в левую часть, а в других – в правую часть системы:


Система взаимозависимых уравнений получила название система совместных, одновременных уравнений. Тем самым подчеркивается, что в системе одни и те же переменные у одновременно рассматриваются как зависимые в одних уравнениях и как независимые в других. В эконометрике эта система уравнений называется также структурной формой модели. В отличие от предыдущих систем каждое уравнение системы одновременных уравнений не может рассматриваться самостоятельно, и для нахождения его параметров традиционный МНК неприменим. С этой целью используются специальные приемы оценивания.
12.Структурная и приведенная формы модели.
Экономическая модель как система одновременных уравнений может быть представлена в структурной или в приведенной форме. В структурной форме ее уравнения имеют исходный вид, отражая непосредственные связи между переменными. Приведенная форма получается после решения модели относительно эндогенных (внутренних) переменных, то есть выражения этих переменных только через экзогенные (задаваемые извне) переменные и параметры модели. Структурная форма модели содержит эндогенные переменные –  . Это зависимые переменные, число которых равно числу уравнений в системе, и (которые определяются внутри системы). Экзогенные переменные –
. Это зависимые переменные, число которых равно числу уравнений в системе, и (которые определяются внутри системы). Экзогенные переменные –  . Это независимые переменные, которые определяются вне системы и влияющие на эндогенные переменные, но независящие от них. Лаговые переменные – независимые переменные за предыдущие моменты времени. Лаговыми могут быть эндогенные переменные за предшествующий период времени, и тогда они являются экзогенными.
. Это независимые переменные, которые определяются вне системы и влияющие на эндогенные переменные, но независящие от них. Лаговые переменные – независимые переменные за предыдущие моменты времени. Лаговыми могут быть эндогенные переменные за предшествующий период времени, и тогда они являются экзогенными.
Предопределённые переменные – это экзогенные и лаговые. Структурные коэффициенты модели:  и
и  при переменных x и y. Все переменные в модели выражены в отклонениях от среднего уровня, то есть под x подразумеваются ( -
при переменных x и y. Все переменные в модели выражены в отклонениях от среднего уровня, то есть под x подразумеваются ( -  ), под – ( -
), под – ( -  ). Поэтому свободный член в каждом уравнении отсутствует.
). Поэтому свободный член в каждом уравнении отсутствует.
Использование МНК для оценивания структурных коэффициентов модели дает, как принято считать в теории, смещенные и несостоятельные оценки. Поэтому обычно для определения структурных коэффициентов модели структурная форма модели преобразуется в приведенную форму модели:
 ;
;
 ; (4)
; (4)
…

По своему виду приведённая форма модели идентична системе (1), поэтому параметры системы (4) оцениваются традиционным МНК. А затем оценить значение эндогенных переменных через экзогенные.
Коэффициенты приведённой формы модели (4) представляют собой нелинейные функции коэффициентов структурной формы модели. Пример простейшей структурной модели:

 .
.
Приведенная форма получается так:
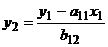
систему одновременных уравнений имеем
 , .
, .
Отсюда  ,
,
 ,
,

Аналогично, получается второе уравнение приведённой формы:  ,
,
 ,
,

13. Идентификация систем уравнений.
При переходе от приведенной формы модели к структурной исследователь сталкивается с проблемой идентификации. Идентификация — это единственность соответствия между приведенной и структурной формами модели.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
• Идентифицируемые (структурные коэффициенты СФМ определяются однозначно, единственным образом по коэффициентам ПФМ, т. е. если число параметров СФМ равно числу параметров ПФМ);
• Неидентифицируемые (число коэффициентов ПФМ меньше числа структурных коэффициентов СФМ, и в результате структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели);
• Сверхидентифицируемые (число коэффициентов ПФМ больше числа структурных коэффициентов СФМ. В этом случае на основе коэффициентов приведенной формы можно получить два или более значений одного структурного коэффициента).
Сверхидентифицируемая модель в отличие от неидентифицируемой модели практически решаема, но требует для этого специальных методов исчисления параметров.
Модель считается идентифицируемой, если каждое уравнение системы идентифицируемо. Если хотя бы одно из уравнений системы неидентифицируемо, то и вся модель считается неидентифицируемой. Сверхидентифицируемая модель содержит хотя бы одно сверхидентифицируемое уравнение.
Выполнение условия идентифицируемости модели проверяется для каждого уравнения системы. Чтобы уравнение было идентифицируемо, необходимо, чтобы число предопределенных переменных, отсутствующих в данном уравнении, но присутствующих в системе (Н), было равно числу эндогенных переменных в данном уравнении (D) без одного.
D + 1 = H— уравнение идентифицируемо;
D + 1 < H — уравнение неидентифицируемо;
D + 1 > H— уравнение сверхидентифицируемо.
Рассмотренное счетное правило отражает необходимое, но недостаточное условие идентификации. Более точно условия идентификации определяются, если накладывать ограничения на коэффициенты матриц параметров структурной модели. Уравнение идентифицируемо, если по отсутствующим в нем переменным (эндогенным и экзогенным) можно из коэффициентов при них в других уравнениях системы получить матрицу, определитель которой не равен нулю, а ранг матрицы не меньше, чем число эндогенных переменных в системе без одного.
14.Понятие временного ряда и факторы, влияющие на формирование уровня ряда.
Эконометрическую модель можно построить, используя два типа исходных данных:
1) Данные, характеризующие совокупность различных объектов в определенный момент (период) времени. Модели, построенные по данным такого типа, называются пространственными моделями.
2) Данные, характеризующие один объект за ряд последовательных моментов (периодов) времени. Такие модели называются моделями временных рядов.
Временной ряд – совокупность значений какого-либо показателя за несколько последовательных моментов (периодов) времени.
Факторы, влияющие на формирование уровней временного ряда:
1) Факторы, формирующие тенденцию ряда
2) Факторы, формирующие циклические колебания ряда
3) Случай