Операторы манипулирования данными. Операторы DML (Data Manipulation Language) - операторы манипулирования данными
· SELECT - отобрать строки из таблиц
· INSERT - добавить строки в таблицу
· UPDATE - изменить строки в таблице
· DELETE - удалить строки в таблице
· COMMIT - зафиксировать внесенные изменения
· ROLLBACK - откатить внесенные изменения
INSERT INTO
P (PNUM, PNAME)
VALUES (4, "Иванов");
UPDATE P
SET PNAME = "Пушников"
WHERE P.PNUM = 1;
DELETE FROM P
WHERE P.PNUM = 1;
SELECT *
FROM P;
| 4.Организация безопасности данных в базе данных. Безопасность и секретность. Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это права, от неавторизованной модификации данных или их разрушения. Секретность определяется как право отдельных лиц или организаций решать, когда, как и какое количество соответствующей информации может быть передано другим лицам или организациям.Ниже перечислены положения, особенно важные с точки зрения обеспечения безопасности данных в базе данных:1.Данные должны быть защищены от искажения, хищения и других форм разрушения.2.Данные должны быть восстанавливаемыми, так как иногда, несмотря на тщательную предосторожность, могут иметь место различного рода случайные сбои.3.Данные должны быть контролируемыми. Нарушения проверочных средств в вычислительных системах могут привести к катастрофе.4.Система должна быть недоступной для вмешательства; обычные программисты не должны располагать возможностью обхода системы контроля.5.В настоящее время еще нет систем, полностью изолированных от возможности вмешательства, но осуществление вмешательства в систему должно быть предельно трудным. Должна быть установлена процедура идентификации пользователя базы данных, которая обеспечивает возможность доступа к базе только после правильного ее выполнения.6.В системе должен быть предусмотрен контроль действий пользователя с точки зрения санкционирования их выполнения.7.Контроль над работой пользователя должен осуществляться так, чтобы его ошибочные действия были с большой вероятностью обнаружены.
10.Простые и сложные сетевые структуры.Во многих сетевых структурах, задающих связи между типами записей или типами агрегатов данных, представление отношений между исходными и порожденными элементами аналогично представлению отношений в случае дерева: отношение исходный-порожденный является сложным, а отношение порожденный-исходный – простым (рис.3.6).
 Рис.3.6. Категории схем. СУБД и используемые в них языки отличаются типами допустимых структур. В одних системах возможна обработка только иерархических структур, в других – допустимы только простые сетевые структуры. Число уровней, которые могут обрабатываться, различно в разных системах. Лишь в нескольких системах, если такие вообще существуют, допустимые петли.
16.Основные понятия, используемые в многомерных СУБД: агрегируемость, историчность и прогнозируемость данных. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных. Агрегируемостъ данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
36.Семантическое моделирование.В реальном проектировании структуры базы данных применяются другой метод - так называемое, семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship). Модель данных "сущность-связь" или ER-модель (Entity Relationship Model) дает представление о предметной области в виде объектов, называемых сущностями, между которыми фиксируются связи.Для каждой связи определено число связываемых ею объектов. На схеме сущности изображаются прямоугольниками, связи - ромбами. Число связываемых объектов указывается цифрой на линии соединения объекта и связи. По сути, все варианты диаграмм сущность-связь исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
44.Операторы защиты и управления данными. Операторы защиты и управления даннымиCREATE ASSERTION - создать ограничение DROP ASSERTION - удалить ограничение GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами REVOKE - отменить привилегии пользователя или приложения
CREATE ASSERTION constraint_name
CHECK (conditional_expression)
<предоставление_привилегий>::=
GRANT SELECT, INSERT ON Товар TO stud
<отмена_привилегий>::=
REVOKE INSERT ON Товар TO stud
7.Иерархическая модель. Достоинства и недостатки данной модели. Иерархическая модельИерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Рис.3.6. Категории схем. СУБД и используемые в них языки отличаются типами допустимых структур. В одних системах возможна обработка только иерархических структур, в других – допустимы только простые сетевые структуры. Число уровней, которые могут обрабатываться, различно в разных системах. Лишь в нескольких системах, если такие вообще существуют, допустимые петли.
16.Основные понятия, используемые в многомерных СУБД: агрегируемость, историчность и прогнозируемость данных. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных. Агрегируемостъ данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
36.Семантическое моделирование.В реальном проектировании структуры базы данных применяются другой метод - так называемое, семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship). Модель данных "сущность-связь" или ER-модель (Entity Relationship Model) дает представление о предметной области в виде объектов, называемых сущностями, между которыми фиксируются связи.Для каждой связи определено число связываемых ею объектов. На схеме сущности изображаются прямоугольниками, связи - ромбами. Число связываемых объектов указывается цифрой на линии соединения объекта и связи. По сути, все варианты диаграмм сущность-связь исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
44.Операторы защиты и управления данными. Операторы защиты и управления даннымиCREATE ASSERTION - создать ограничение DROP ASSERTION - удалить ограничение GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами REVOKE - отменить привилегии пользователя или приложения
CREATE ASSERTION constraint_name
CHECK (conditional_expression)
<предоставление_привилегий>::=
GRANT SELECT, INSERT ON Товар TO stud
<отмена_привилегий>::=
REVOKE INSERT ON Товар TO stud
7.Иерархическая модель. Достоинства и недостатки данной модели. Иерархическая модельИерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева).  Рис.3.1 Дерево (каждый элемент имеет не более одного исходного элемента) Дерево (рис. 3.1) представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне. Они называются порожденными. Элементы, расположенные в конце ветви, т.е. не имеющие порожденных, называются листьями. На рис. 3.1 элемент 1 является корнем, элементы 5, 6, 8-12 и 14-22 - листьями. Дерево обычно изображается в перевернутом виде - с корнем вверху и листьями внизу.Деревья, подобные показанному на рис. 3.1, применяются как для логического, так и для физического описания данных. В логическом описании данных они используются для определения связей между типами сегментов или типами записей, а при определении физической организации данных - для описания набора указателей и связей между элементами в индексах. Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. В целом тип «дерево» представляет собой иерархически организованный набор типов «запись». Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
11.Реляционная модель. Достоинства и недостатки данной модели.Реляционная модель данных была предложена Е.Ф. Коддом, известным исследователем в области баз данных, в 1969 году, когда он был сотрудником фирмы IBM. Впервые основные концепции этой модели были опубликованы в 1970.
Реляционная база данных представляет собой хранилище данных, организованных в виде двумерных таблиц (см. рис. 2.5). Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями). Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, - об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам: 1. Каждое значение, содержащееся на пересечении строки и столбца, должно быть атомарным. 2. Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД. 3. Каждая запись в таблице уникальна, то есть в таблице не существует двух записей с полностью совпадающим набором значений ее полей. 4. Каждое поле имеет уникальное имя. 5. Последовательность полей в таблице несущественна. 6. Последовательность записей в таблице несущественна. Поле или комбинацию полей, значения которых однозначно идентифицируют каждую запись таблицы, называют возможным ключом(или просто ключом). Если таблица имеет более одного возможного ключа, тогда один ключ выделяют в качестве первичного. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой строки. Поле, указывающее на запись в другой таблице, связанную с данной записью, называется внешним ключом. Подобное взаимоотношение между таблицами называется связью. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой базы данных. Информация о таблицах, их полях, первичных и внешних ключах, а также иных объектах базы данных, называется метаданными. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной ее широкого использования. Рис.3.1 Дерево (каждый элемент имеет не более одного исходного элемента) Дерево (рис. 3.1) представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне. Они называются порожденными. Элементы, расположенные в конце ветви, т.е. не имеющие порожденных, называются листьями. На рис. 3.1 элемент 1 является корнем, элементы 5, 6, 8-12 и 14-22 - листьями. Дерево обычно изображается в перевернутом виде - с корнем вверху и листьями внизу.Деревья, подобные показанному на рис. 3.1, применяются как для логического, так и для физического описания данных. В логическом описании данных они используются для определения связей между типами сегментов или типами записей, а при определении физической организации данных - для описания набора указателей и связей между элементами в индексах. Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. В целом тип «дерево» представляет собой иерархически организованный набор типов «запись». Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
11.Реляционная модель. Достоинства и недостатки данной модели.Реляционная модель данных была предложена Е.Ф. Коддом, известным исследователем в области баз данных, в 1969 году, когда он был сотрудником фирмы IBM. Впервые основные концепции этой модели были опубликованы в 1970.
Реляционная база данных представляет собой хранилище данных, организованных в виде двумерных таблиц (см. рис. 2.5). Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями). Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, - об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам: 1. Каждое значение, содержащееся на пересечении строки и столбца, должно быть атомарным. 2. Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД. 3. Каждая запись в таблице уникальна, то есть в таблице не существует двух записей с полностью совпадающим набором значений ее полей. 4. Каждое поле имеет уникальное имя. 5. Последовательность полей в таблице несущественна. 6. Последовательность записей в таблице несущественна. Поле или комбинацию полей, значения которых однозначно идентифицируют каждую запись таблицы, называют возможным ключом(или просто ключом). Если таблица имеет более одного возможного ключа, тогда один ключ выделяют в качестве первичного. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой строки. Поле, указывающее на запись в другой таблице, связанную с данной записью, называется внешним ключом. Подобное взаимоотношение между таблицами называется связью. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой базы данных. Информация о таблицах, их полях, первичных и внешних ключах, а также иных объектах базы данных, называется метаданными. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной ее широкого использования.  Рис. 2.5. Схема реляционной модели данных К основным недостаткам реляционной модели относятся отсутствие стандартных средств идентификации отдельных записей и сложность описан ия ие рархических и сетевых связей. Примерами зарубежных реляционных СУБД для ПЭВМ являются: DB 2, Paradox, FoxPro, Access, Clarion, Ingres, Oracle. К отечественным СУБД реляционного типа относятся системы ПАЛЬМА и HyTech.
14.Постреляционная модель. Достоинства и недостатки данной модели. Постреляционная модель является естественным развитием реляционной модели, появление которой без сомнения было событием в истории развития баз данных. Более того, это позволило создавать программы, независимые от данных, упростить программный интерфейс для конечного пользователя и, наконец, обеспечить безопасность и целостность данных, что очень важно для каждой компании. Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц, называемую не первой нормальной формой NF2. Поддержка этой модели в СУБД позволяет объединять большинство функций реляционной модели (особенно язык запросов SQL) с дополнительными возможностями поиска, манипулирования и хранения данных. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.На рис. 1 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица Накладные содержит данные о номерах накладных и номерах покупателей. В таблице Накладные-товары содержатся данные о каждой из накладных: номер накладной, название товара и количество товара. Таблица Накладные связана с таблицей Накладные-товары по полю номер накладной.а) Накладные Рис. 2.5. Схема реляционной модели данных К основным недостаткам реляционной модели относятся отсутствие стандартных средств идентификации отдельных записей и сложность описан ия ие рархических и сетевых связей. Примерами зарубежных реляционных СУБД для ПЭВМ являются: DB 2, Paradox, FoxPro, Access, Clarion, Ingres, Oracle. К отечественным СУБД реляционного типа относятся системы ПАЛЬМА и HyTech.
14.Постреляционная модель. Достоинства и недостатки данной модели. Постреляционная модель является естественным развитием реляционной модели, появление которой без сомнения было событием в истории развития баз данных. Более того, это позволило создавать программы, независимые от данных, упростить программный интерфейс для конечного пользователя и, наконец, обеспечить безопасность и целостность данных, что очень важно для каждой компании. Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц, называемую не первой нормальной формой NF2. Поддержка этой модели в СУБД позволяет объединять большинство функций реляционной модели (особенно язык запросов SQL) с дополнительными возможностями поиска, манипулирования и хранения данных. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.На рис. 1 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица Накладные содержит данные о номерах накладных и номерах покупателей. В таблице Накладные-товары содержатся данные о каждой из накладных: номер накладной, название товара и количество товара. Таблица Накладные связана с таблицей Накладные-товары по полю номер накладной.а) Накладные
| Номер накладной
| Номер покупателя
| |
|
| |
|
| |
|
| Накладные-товары
| Номер накладной
| Название товара
| Количество товара
| |
| Монитор
|
| |
| Системный блок
|
| |
| Принтер
|
| |
| Клавиатура
|
| |
| Сканер
|
| |
| Плоттер
|
| б) Накладные
| Номер накладной
| Номер покупателя
| Название товара
| Количество товара
| |
|
| Монитор
|
| |
|
| Системный блок
|
| |
|
| Принтер
|
| |
|
| Клавиатура
|
| |
|
| Сканер
|
| |
|
| Плоттер
|
| Рис. 1. Структуры данных реляционной и постреляционной моделей
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д. На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость. Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах. Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Постреляционная модель обеспечивает инфраструктуру, наилучшим образом обеспечивающую решение сложных аналитических задач, требующих обработки больших объемов информации. Она сокращает требуемые размеры памяти и позволяет на той же самой конфигурации связать больше пользователей с базой данных, чем реляционные базы данных. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. К числу СУБД, основанных на постреляционной модели данных, относятся системы uniVers, Bubba и Dasdb.
21.Связь объектно-ориентированных СУБД с общими понятиями объектно-ориентированного подхода. В наиболее общей и классической постановке объектно-ориентированный подход базируется на следующих концепциях: - объекта и идентификатора объекта; - атрибутов и методов; - классов; - иерархии и наследования классов. Любая сущность реального мира в объектно-ориентированных языках и системах моделируется в виде объекта. Любой объект при своем создании получает генерируемый системой уникальный идентификатор, который связан с объектом все время его существования и не меняется при изменении состояния объекта. Каждый объект имеет состояние и поведение. Состояние объекта - набор значений его атрибутов. Поведение объекта - набор методов (программный код), оперирующих над состоянием объекта. Значение атрибута объекта - это тоже некоторый объект или множество объектов. Состояние и поведение объекта инкапсулированы (находяться) в объекте; взаимодействие объектов производится на основе передачи сообщений и выполнении соответствующих методов. Множество объектов с одним и тем же набором атрибутов и методов образует класс объектов. Объект должен принадлежать только одному классу (если не учитывать возможности наследования). Допускается наличие примитивных предопределенных классов, объекты-экземпляры которых не имеют атрибутов: целые, строки и т.д. Класс, объекты которого могут служить значениями атрибута объектов другого класса, называется доменом этого атрибута. Допускается порождение нового класса на основе уже существующего класса - наследование. В этом случае новый класс, называемый подклассом существующего класса (суперкласса), наследует все атрибуты и методы суперкласса. В подклассе, кроме того, могут быть определены дополнительные атрибуты и методы. Различаются случаи простого и множественного наследования. В первом случае подкласс может определяться только на основе одного суперкласса, во втором случае суперклассов может быть несколько. Если в языке или системе поддерживается единичное наследование классов, набор классов образует древовидную иерархию. При поддержании множественного наследования классы связаны в ориентированный граф с корнем, называемый решеткой классов. Объект подкласса считается принадлежащим любому суперклассу этого класса. Одной из более поздних идей объектно-ориентированного подхода является идея возможного переопределения атрибутов и методов суперкласса в подклассе (перегрузки методов). Эта возможность увеличивает гибкость, но порождает дополнительную проблему: при компиляции объектно-ориентированной программы могут быть неизвестны структура и программный код методов объекта, хотя его класс (в общем случае - суперкласс) известен. Для разрешения этой проблемы применяется так называемый метод позднего связывания, означающий, по сути дела, интерпретационный режим выполнения программы с распознаванием деталей реализации объекта во время выполнения посылки сообщения к нему. Введение некоторых ограничений на способ определения подклассов позволяет добиться эффективной реализации без потребностей в интерпретации. Как видно, при таком наборе базовых понятий, если не принимать во внимание возможности наследования классов и соответствующие проблемы, объектно-ориентированный подход очень близок к подходу языков программирования с абстрактными (или произвольными) типами данных. С другой стороны, если абстрагироваться от поведенческого аспекта объектов, объектно-ориентированный подход весьма близок к подходу семантического моделирования данных (даже и по терминологии). Фундаментальные абстракции, лежащие в основе семантических моделей, неявно используются и в объектно-ориентированном подходе. На абстракции агрегации основывается построение сложных объектов, значениями атрибутов которых могут быть другие объекты. Абстракция группирования - основа формирования классов объектов. На абстракциях специализации/обобщения основано построение иерархии или решетки классов. Видимо, наиболее важным новым качеством ООБД, которого позволяет достичь объектно-ориентированный подход, является поведенческий аспект объектов. В прикладных информационных системах, основывавшихся на БД с традиционной организацией (вплоть до тех, которые базировались на семантических моделях данных), существовал принципиальный разрыв между структурной и поведенческой частями. Структурная часть системы поддерживалась всем аппаратом БД, ее можно было моделировать, верифицировать и т.д., а поведенческая часть создавалась изолированно. В частности, отсутствовали формальный аппарат и системная поддержка совместного моделирования и гарантирования согласованности этих структурной (статической) и поведенческой (динамической) частей. В среде ООБД проектирование, разработка и сопровождение прикладной системы становится процессом, в котором интегрируются структурный и поведенческий аспекты. Конечно, для этого нужны специальные языки, позволяющие определять объекты и создавать на их основе прикладную систему. Специфика применения объектно-ориентированного подхода для организации и управления БД потребовала уточненного толкования классических концепций и некоторого их расширения. Это определяется потребностями долговременного хранения объектов во внешней памяти, ассоциативного доступа к объектам, обеспечения согласованного состояния ООБД в условиях мультидоступа и тому подобных возможностей, свойственных базам данных. Выделяются три аспекта, отсутствующие в традиционной парадигме, но требующиеся в ООБД. Первый аспект касается потребности в средствах спецификации знаний при определении класса (ограничений целостности, правил дедукции и т.п.). Второй аспект - потребность в механизме определения разного рода семантических связей между объектами вообще говоря разных классов. Фактически это означает требование полного распространения на ООБД средств семантического моделирования данных. Потребность в использовании абстракции ассоциирования отмечается и в связи с использовании ООБД в сфере автоматизированного проектирования и инженерии. Наконец, третий аспект связан с пересмотром понятия класса. В контексте ООБД оказывается более удобным рассматривать класс как множество объектов данного типа, т.е. одновременно поддерживать понятия и типа и класса объектов. Как мы отмечали во введении, в сообществе исследователей ООБД и разработчиков систем отсутствует полное согласие, но в большинстве практических работ используется некоторое расширение объектно-ориентированного подхода.
26.Нормальные формы отношений. Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение. Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации. Устранение избыточности производится, как правило, за счёт декомпозиции отношений таким образом, чтобы в каждом отношении хранились только первичные факты (то есть факты, не выводимые из других хранимых фактов).
23. Базовые понятия РБД осн понятиями РБД явл-ся: -тип д-х, -домен, -атрибут, -кортеж, -первич.ключ, -отношения. Тип д-х: понятие типа д-х в РБД полностью адекв. понятию типа д-х в языках прогр-я. Обычно в соврем. РБД допуск-ся хран-е символ-х, числ-х д-х, битовых строк, специализ. числ-х д-х, а также спец-х темпорал-х д-х (дата, время, врем. инт-л). Дост. активно развив-ся подход к расшир-ю возм-тей реляц-х систем абстракт-ми типами д-х. Домен: В РМД с понятием типа д-х тесно связ. понятие домена, кот. можно счит. уточ-ем типа д-х. Домен-семантич. понятие. Домен можно рассм-ть как подмн-во знач-й некот. типа д-х, имеющих опред. смысл. Домен хар-ся след. св-вами: 1.домен имеет уникал. имя; 2.домен опр-н на некот. простом типе д-х или на др. домене; 3.домен может иметь некот. логич. усил-е, позвол-е описать подмн-во д-х допуст-х для данн. домена; 4.домен несет опред. смысл-ю нагрузку. Понятие домена помогает прав-но моделир-ть предмет. обл-ть. Отнош-е: 1. Атрибут отн-я есть пара вида <имя_атрибута:имя_домена>. Имена атрибутов должны быть уникал. в пределах отнош-я. Часто имена атриб-в отн-я совпад. с именами соотв-х доменов. 2. Отн-я к R, опред-е на мн-ве доменов Д1,Д2,...Дп содержит 2 части: заголовок и тело. Заголовок отн-я содерж. фиксир-е кол-во атриб-в отн-я (<А1:Д1>, <А2:Д2>,..., <Ап:Дп>). Тело отн-я содерж. мн-во кортежей отн-я. Кажд. кортеж отн-я предст. собой мн-во пар вида <имя_атрибута:знач-е_атрибута> (Тело: <A1:Val1>, <A2:Val2>, …, <An:Valn>), таких что знач-е Vali атрибута Ai принадл. домену Di. Отн-е обычно запис-ся в виде R(<А1:Д1>, <А2:Д2>,..., <Ап:Дп>), или короче R(A1, A2, …, An), или просто R. Число атриб-в в отн-и наз. степенью или R-тью отн-я. Мощ-ть мн-ва кортежей отн-я наз. мощ-тью отн-я. Выводы: 1)-заголовок отн-я опис. декартово произв-е доменов, на кот. задано отн-е. –заголовок статичен, он не мен-ся во время работы с БД. –если в отн-и изм-ны, добав-ны или удалены атрибуты, то в рез-те получим уже др.отн-е, пусть даже с преж.именем. 2)тело отн-я предст. собой набор кортежей, т.е. подмн-во декарт. произв-я доменов. Т.о. тело отн-я собственно и явл-ся отн-ем в матем. смысле слова. 3. РБД наз-ся набор отн-й. 4. Схемой РБД наз. набор заголовков отн-й,вх-х в БД.

30. 3НФ. Атрибуты наз. взаимозавис-ми, если ни 1 из них не явл. функц. завис. от др. Отн-е R нах. в 3НФ <=> отн-е нах-ся в 2НФ и все неключ. атрибуты взаимно независ. Отн-е «сотр-отделы» не нах-ся в 3НФ, т.к. имеется функц. завис-ть неключ. атриб-в (№тел-адрес-№отдела): №отдела->тел. Для того, чтобы устран. завис-ть неключ. атриб-в, необх. произвести декомпоз-ю отн-я на неск-ко отн-й, при этом те неключ. атрибуты, кот. явл-ся завис. вынос-ся в отд. отнош-е. Отн-е «Сотр-отделы» декомпоз. на сотр и отд. «Сотр»: (№, фамилия, №отдела). В этом отн-и есть функц. завис-ть, а именно завис-ть атриб-в, хар-х сотр-ка, от табел. номера сотр-ка: номер_сотр->фамилия, номер_сотр->номер_отдела, номер_сотр->тел. Т.о. мы можем предст. отн. «Сотр» в табл. форме: №сотр | фамилия | №отдела: 1-Ив-1, 2-петр-1, 3-Сид-2. «Отделы»: (№отдела, тел). В этом отн-и есть функц. завис-ть: №отдела->тел. Также можно предст. в табл. форме: №отдела | тел: 1-1111, 2-1122. Обратим вним-е на то, что атрибут «номер_отдела», не явл-ся ключ-м в отн-и «сотр-отдел», стан-ся потенц. ключом в отн-и «отделы». Именно засчет этого устран-ся избыт-ть, связ. с многократ. хран-ем 1 и тех же №№ тел-в.Т.о. все обнаруж-е аномалии обновл-я устранены. Реляц. модель, сост-я из 4х отн-й (сотр, отделы, проекты, задания), нах-ся в 3НФ, явл-ся адекват. опис-ймодели предм.обл. и требует налич. только тех тригеров, кот. поддерж. ссылоч. целост-ть. Такие тригеры явл-ся стандарт. и не требуют больших усилий в разраб-ке. Отн-е в 3НФ явл-ся самыми «хорошими» с т.з. выбр-х нами критериев.
37. Основные понятия ER-диаграмм. Сущность- класс однотип. объектов, инфо о кот. должна быть учтена в модели. Кажд. сущ-ть должна иметь наим-е, выраж-е сущ-ным в ед. числе. Кажд сущ-ть в модели изобр-ся в виде прямоуг-ка с наим-ем: (прямоуг-к, раздел. пополам, сверху надпись «сотрудник», нижний пуст; аналогич. прямоуг-к «отдел»). Экземпляр сущ-ти – конкрет. предст-ль данн. сущ-ти. Экз-ры сущ-ти должны быть различимы, т.е. иметь некот. св-ва, уникал. для кажд. экз-ра эт. сущ-ти. Атрибут сущ-ти – именов-я хар-ка, явл-ся некот. св-вом сущ-ти. (Для сущ-ти «Сотр-к» - Фамилия, имя, отдел, з/п итд). Атрибуты изобр-ся в пределах пр-ка, опред-го сущ-ть: (прямоуг-к, раздел. пополам, сверху надпись «Сотр-к», в ниж. части Фамилия, Имя, Отдел, з/п). Ключ сущ-ти – неизбыт. набор атриб-в, знач-е кот. в совокуп-ти явл. уникал. для любого экз-ра сущ-ти. Неизбыт-ть закл. в том, что удал-е любого атрибута из ключа нарушает его уникал-ть. Сущ-ть может иметь неск-ко различ. ключей. Ключ-е атрибуты изобр-ся в диагр-х подчерк-ем (обычно запис-ся самым первым). Связь – некот. ассоциация м/у 2мя сущ-тями. 1 сущ-ть м.б. связ. с др. сущ-тью или сама с собой. Графически связь изобр-ся линией, соед-й 2 сущ-ти: 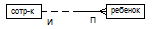 И-иметь, П-принадлежность. И-иметь, П-принадлежность.
42. Опер-ры опред-я объектов БД. Опер-ры DDL – это опер-ры опред-я объектов БД. (create schema – опер-р созд-я сх. БД; drop schema – опер-р удал-я сх. БД; create table – опер-р созд-я табл.; drop table – опер-р удал-я табл.; alter table – опер-р измен-я табл.; create view – опер-р созд-я предст-я; drop view – опер-р удал-я предст-я).
пример: вставка 1 строки в табл.
insert into
P(pnum, pname)
values(4,”Иванов”)
обновл-е неск-ких строк в табл.
update P
set pname=”Иванов”
where p.pnum=1
удал-е неск-ких строк в табл
delete from P
where P.pnum=1
удал-е всех строк в табл.
delete from p
38.Типы связи сущность-связь. Каждая связь может иметь один из следующих типов связи: ]  Рис. 5 Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две. Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней. Характерный пример такой связи приведен на Рис. 4. Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности. Рис. 5 Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две. Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней. Характерный пример такой связи приведен на Рис. 4. Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
39.Модальность связи. Каждая связь может иметь одну из двух модальностей связи: 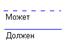 Рис. 6 Модальность " может " означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром. Модальность " должен " означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности. Связь может иметь разную модальность с разных концов (как на Рис. 4). Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз: <Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>. Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так: Слева направо: "каждый сотрудник может иметь несколько детей". Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику". Рис. 6 Модальность " может " означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром. Модальность " должен " означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности. Связь может иметь разную модальность с разных концов (как на Рис. 4). Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз: <Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>. Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так: Слева направо: "каждый сотрудник может иметь несколько детей". Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".  Рис.4 Рис.4
|