Содержание
Задание 1. 3
Задание 2. 7
Задание 3. 11
Литература. 12
Задание 1.
Задачи DataMining. Задача классификации и регрессии
Классификация задач DataMining
Согласно классификации по стратегиям, задачи DataMining подразделяются на следующие группы:
¾ обучение с учителем;
¾ обучение без учителя;
¾ другие.
Категория обучение с учителем представлена следующими задачами DataMining: классификация, оценка, прогнозирование.
Категория обучение без учителя представлена задачей кластеризации.
В категорию другие входят задачи, не включенные в предыдущие две стратегии.
Задачи DataMining, в зависимости от используемых моделей, могут быть дескриптивными и прогнозирующими. Эти типы моделей будут подробно описаны в лекции, посвященной процессу DataMining.
В соответствии с этой классификацией, задачи DataMining представлены группами описательных и прогнозирующих задач.
В результате решения описательных (descriptive) задач аналитик получает шаблоны, описывающие данные, которые поддаются интерпретации.
Эти задачи описывают общую концепцию анализируемых данных, определяют информативные, итоговые, отличительные особенности данных. Концепция описательных задач подразумевает характеристику и сравнение наборов данных.
Характеристика набора данных обеспечивает краткое и сжатое описание некоторого набора данных.
Сравнение обеспечивает сравнительное описание двух или более наборов данных.
Прогнозирующие (predictive) основываются на анализе данных, создании модели, предсказании тенденций или свойств новых или неизвестных данных.
Достаточно близким к вышеупомянутой классификации является подразделение задач DataMining на следующие: исследования и открытия, прогнозирования и классификации, объяснения и описания.
Автоматическое исследование и открытие (свободный поиск)
Пример задачи: обнаружение новых сегментов рынка.
Для решения данного класса задач используются методы кластерного анализа.
прогнозирование и классификация
Пример задачи: предсказание роста объемов продаж на основе текущих значений.
Методы: регрессия, нейронные сети, генетические алгоритмы, деревья решений.
Задачи классификации и прогнозирования составляют группу так называемого индуктивного моделирования, в результате которого обеспечивается изучение анализируемого объекта или системы. В процессе решения этих задач на основе набора данных разрабатывается общая модель или гипотеза.
Объяснение и описание
Пример задачи: характеристика клиентов по демографическим данным и историям покупок.
Методы: деревья решения, системы правил, правила ассоциации, анализ связей.
Если доход клиента больше, чем 50 условных единиц, и его возраст - более 30 лет, тогда класс клиента - первый.
В интерпретации обобщенной модели аналитик получает новое знание. Группировка объектов происходит на основе их сходства.
Задачи DataMining
Классификация (Classification)
Краткое описание. Наиболее простая и распространенная задача DataMining. В результате решения задачи классификации обнаруживаются признаки, которые характеризуют группы объектов исследуемого набора данных - классы; по этим признакам новый объект можно отнести к тому или иному классу.
Методы решения. Для решения задачи классификации могут использоваться методы: ближайшего соседа (NearestNeighbor); k-ближайшего соседа (k-NearestNeighbor); байесовские сети (BayesianNetworks); индукция деревьев решений; нейронные сети (neuralnetworks).
Кластеризация (Clustering)
Краткое описание. Кластеризация является логическим продолжением идеи классификации. Это задача более сложная, особенность кластеризации заключается в том, что классы объектов изначально не предопределены. Результатом кластеризации является разбиение объектов на группы.
Пример метода решения задачи кластеризации: обучение "без учителя" особого вида нейронных сетей - самоорганизующихся карт Кохонена.
Ассоциация (Associations)
Краткое описание. В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в наборе данных.
Отличие ассоциации от двух предыдущих задач DataMining: поиск закономерностей осуществляется не на основе свойств анализируемого объекта, а между несколькими событиями, которые происходят одновременно.
Наиболее известный алгоритм решения задачи поиска ассоциативных правил - алгоритм Apriori.
Последовательность (Sequence), или последовательная ассоциация (sequentialassociation)
Краткое описание. Последовательность позволяет найти временные закономерности между транзакциями. Задача последовательности подобна ассоциации, но ее целью является установление закономерностей не между одновременно наступающими событиями, а между событиями, связанными во времени (т.е. происходящими снекоторым определенным интервалом во времени). Другими словами, последовательность определяется высокой вероятностью цепочки связанных во времени событий. Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю. Эту задачу DataMining также называют задачей нахождения последовательных шаблонов (sequentialpattern).
Правило последовательности: после события X через определенное время произойдет событие Y.
Пример. После покупки квартиры жильцы в 60% случаев в течение двух недель приобретают холодильник, а в течение двух месяцев в 50% случаев приобретается телевизор. Решение данной задачи широко применяется в маркетинге и менеджменте, например, при управлении циклом работы с клиентом (CustomerLifecycleManagement).
Прогнозирование (Forecasting)
Краткое описание. В результате решения задачи прогнозирования на основе особенностей исторических данных оцениваются пропущенные или же будущие значения целевых численных показателей.
Для решения таких задач широко применяются методы математической статистики, нейронные сети и др.
Определение отклонений или выбросов (DeviationDetection), анализ отклонений или выбросов
Краткое описание. Цель решения данной задачи - обнаружение и анализ данных, наиболее отличающихся от общего множества данных, выявление так называемых нехарактерных шаблонов.
Задание 2.
Создать локальный OLAP-куб в MS Excel для анализа суммарной стоимости проданных товаров сотрудниками фирмы «Борей» клиентам данной фирмы по датам размещения заказов.
Создать локальныйOLAP-куб в MSExcel
Для этого запустим MicrosoftExcel и из меню Данных выберем Сводная таблица. После этого управление будет передано мастеру сводных таблиц и диаграмм. В первой диалоговой панели этого мастера укажем, что для построения сводной таблицы выбирается внешний источник данных, вид создаваемого отчета – сводная диаграмма. Затем укажем, что это за источник, нажав кнопку Получить данные в следующей диалоговой панели, что приведет к запуску приложения MicrosoftQuery. Далее выберем закладку Базы Данных и, если в операционной системе еще нет описания соответствующего источника данных, создадим его, выбрав Новый источник данных.


В качестве дальнейших действий выберем создание куба OLAP из данного запроса.

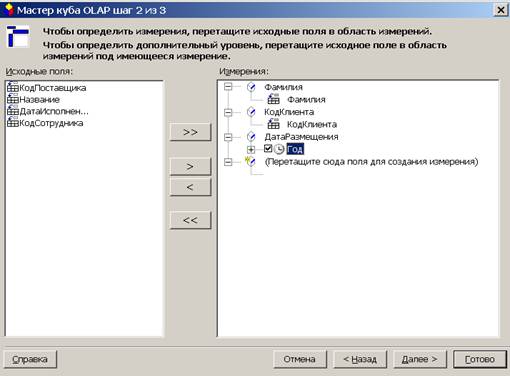


Итак, мы отобразили в сводной таблице Excel содержимое OLAP-куба.

Задание 3.
Подобрать массив данных по выбранной предметной области в соответствии с интересами по осваиваемой специальности, работе или другими обстоятельствами. При использовании Internet можно воспользоваться сайтами rambler.ru, expert.ru, yandex.ruи другими. Экспортировать заинтересовавшие данные в Excel и провести интеллектуальный анализ полученных данных с помощью команд меню Данные, построения Диаграмм. Реализовать для данного массива данных одну из моделей DataMining – классификации (регрессии), кластеризации или поиска ассоциативных правил.
При использовании Internetподберем массив данных
сайт https://www.president.gov.by/press10686.html

Экспортированные данные в Excel
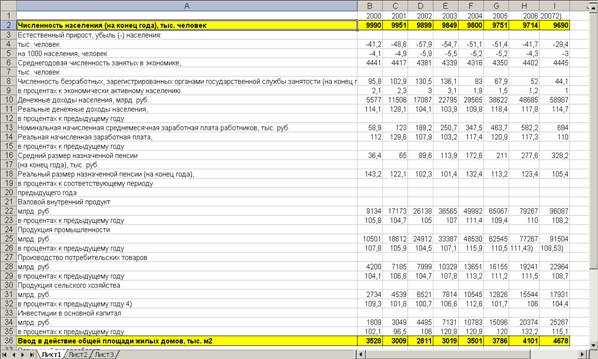
Для анализа данных будем использовать инструмент «Регрессия»

Диалоговое окно инструмента «Регрессия»
