ЧАСТЬ 1. ВВЕДЕНИЕ
В реальной жизни мы сталкиваемся с классом задач, где объектом предсказания является номинативная переменная с двумя градациями. Например, купит ли покупатель исследуемый продукт или нет, расплатится ли заемщик по кредиту или уволится ли сотрудник из компании в ближайшее время и.т.д.
Модель XGboost, основанная на построении бинарных деревьев решений способна поддерживать многопоточную обработку данных и строить направленную композицию: каждый следующий алгоритм исправляет ошибки предыдущего.
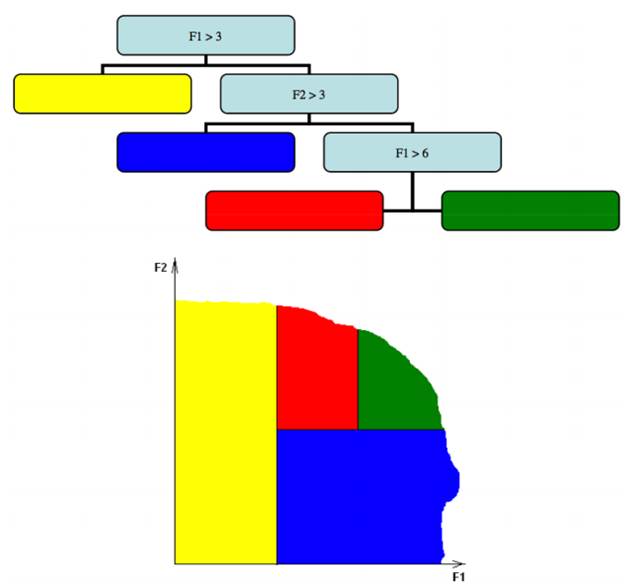
Рисунок 1. Небольшой пример для понимания.
ЧАСТЬ 2. ОБЩИЕ СВЕДЕНИЯ
Бустинг — это подход к построению композиций, в рамках которого:
• Базовые алгоритмы строятся последовательно, один за другим.
• Каждый следующий алгоритм строится таким образом, чтобы исправлять ошибки уже построенной композиции. Благодаря тому, что построение композиций в бустинге является направленным, достаточно использовать простые базовые алгоритмы, например неглубокие деревья.
Градиентный бустинг способ направленного построения композиции, которая является суммой, а не усреднением базовых алгоритмов bi(x).
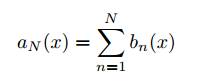
Это связано с тем, что алгоритмы обучаются последовательно, и каждый следующий корректирует ошибки предыдущих.
Пусть задана функция потерь L(y, z), где y — истинный ответ, z — прогноз алгоритма на некотором объекте.
Примерами возможных функций потерь являются:
• среднеквадратичная ошибка (в задаче регрессии):
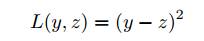
• логистическая функция потерь (в задаче классификации):
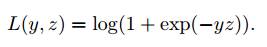
Инициализация.
В начале построения композиции по методу градиентного бустинга нужно ее инициализировать, то есть построить первый базовый алгоритм b0(x). Этот алгоритм не должен быть сколько-нибудь сложным и не стоит тратить на него много усилий.
Например, можно использовать:
• алгоритм b0(x) = 0, который всегда возвращает ноль (в задаче регрессии);
• более сложный, который возвращает средний по всем элементам обучающей выборки истинный ответ (в задаче регрессии);
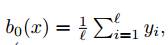
• алгоритм, который всегда возвращает метку самого распространенного класса в обучающей выборке (в задаче классификации).
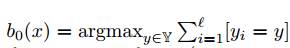
Обучение базовых алгоритмов происходит последовательно. Пусть к некоторому моменту обучены N − 1 алгоритмов b1(x),..., bN−1(x), то есть композиция имеет вид:
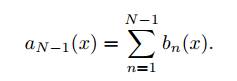
Теперь к текущей композиции добавляется еще один алгоритм bN (x). Этот алгоритм обучается так, чтобы как можно сильнее уменьшить ошибку композиции на обучающей выборке:
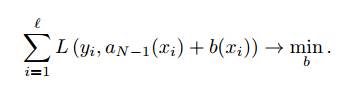
Сначала имеет смысл решить более простую задачу: определить, какие значения s1,..., s l должен принимать алгоритм bN (xi) = si на объектах обучающей выборки, чтобы ошибка на обучающей выборке была минимальной:
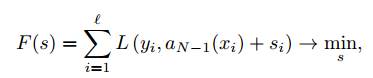 , где s = (s1,..., s l) — вектор сдвигов.
, где s = (s1,..., s l) — вектор сдвигов.
Другими словами, необходимо найти такой вектор сдвигов s, который будет минимизировать функцию F(s).
Поскольку направление наискорейшего убывания функции задается направлением антиградиента, его можно принять в качестве вектора s:
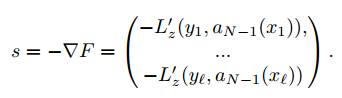
Компоненты вектора сдвигов s, фактически, являются теми значениями, которые на объектах обучающей выборки должен принимать новый алгоритм bN (x), чтобы минимизировать ошибку строящейся композиции. Обучение bN (x), таким образом, представляет собой задачу обучения на размеченных данных, в которой
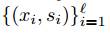
— обучающая выборка, и используется, например, квадратичная функция ошибки:
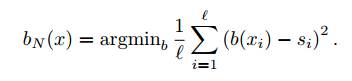
Следует обратить особое внимание на то, что информация об исходной функции потерь L(y, z), которая не обязательно является квадратичной, содержится в выражении для вектора оптимального сдвига s. Поэтому для большинства задач при обучении bN (x) можно использовать квадратичную функцию потерь.
Описание алгоритма градиентного бустинга:
Инициализация композиции:
a0(x) = b0(x), то есть построение простого алгоритма b0.
Шаг итерации:
(a) Вычисляется вектор сдвига
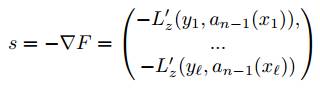
(b) Строится алгоритм
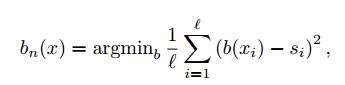 , параметры которого подбираются таким образом, что его значения на элементах обучающей выборки были как можно ближе к вычисленному вектору оптимального сдвига s.
, параметры которого подбираются таким образом, что его значения на элементах обучающей выборки были как можно ближе к вычисленному вектору оптимального сдвига s.
(c) Алгоритм bn(x) добавляется в композицию
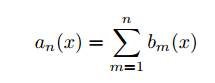
Если не выполнен критерий останова, то выполнить еще один шаг итерации. Если критерий останова выполнен, остановить итерационный процесс.
ЧАСТЬ 3. РЕАЛИЗАЦИЯ
Рассмотрим работу модели градиентного бустинга, решив задачу прогнозирования сахарного диабета с использованием языка программирования Python и библиотеки XGBoost. Набор данных для обучения, который предоставляет Университет Джонса Хопкинса, состоит из объектов, каждый из которых имеет 8 признаков и одну целевую переменную.
Объектами являются женщины в возрасте от 21 года индийского наследия Пима. Признаками объектов являются:
1) Количество беременностей
2) Плазменные концентрации глюкозы в тесте на допустимое отклонение глюкозы
3) Диастолическое артериальное давление
4) Толщина кожи в области трицепса
5) Количество инсулина
6) Индекс массы тела
7) Diabetes pedigree function
8) Возраст
Целевой переменной является метка класса:
0 — прогноз, на предрасположенность к заболеванию сахарным диа- бетом в ближайшие 5 лет,
1 — прогноз, на не предрасположенность к заболеванию сахарным диабетом в ближайшие 5 лет.
Загрузим наборы данных и подготовим их для обучения и оценки качества с помощью модели XGBoost.
import numpy
import xgboost from sklearn
import cross_validation from sklearn. metrics
import accuracy_score
# load data dataset = numpy. loadtxt («pima-indians-diabetes. csv», delimiter=««,)
Необходимо разделить столбцы исходного набора данных на обучающую выборку и целевую переменную.
# split data into X and y
X = dataset [:,0:8]
Y = dataset [:,8]
Также необходимо разбить обучающую выборку на две части: первая будет участвовать в обучении модели, а вторая (отложенная выборка) — в оценке качества обученной модели.
# split data into train and test sets
seed = 7 4
test_size = 0.33
X_train, X_test, y_train, y_test = cross_validation. train_test_split (X, Y, test_size=test_size, random_state=seed)
Так как целевая переменная принимает конечное число значений (0 или 1), мы имеем дело с задачей классификации. Для решения подобных задач в библиотеке XGBoost есть класс XGBClassifier, который позволяет решать задачи классификации при помощи метода градиентного бустинга. Метод fit данного класса принимает в качестве входных параметров обучающую выборку и целевую переменную и обучает модель по входным данным.
# fit model no training data model = xgboost. XGBClassifier () model. fit (X_train, y_train)
После того как модель обучена, можно делать предсказания по отложенной выборке. Для того чтобы сделать предсказание по отложенной выборке, необходимо ее передать на вход в функцию predict объекта XGBClassifier. Выходным значением функции predict является вектор размерности (1, количество объектов в выборке, которая подается на вход), который содержит в себе вероятности отнесения объекта с индексом, к классу 0. Чтобы получить валидные метки класса (0 или 1) необходимо округлить полученные вероятности до 0 или 1.
# make predictions for test data y_pred = model. predict (X_test) predictions = [round (value) for value in y_pred]
Для оценки качества построенной модели используется метод accuracy_score из библиотеки sklearn. На вход он принимает полученные предсказания и действительные метки классов, а на выходе мы получаем долю правильно классифицированных объектов.
# make predictions for test data y_pred = model. predict (X_test) predictions = [round (value) for value in y_pred]
Accuracy: 77.95%
В итоге мы получили качество 77.95%, что является хорошим качеством, учитывая тот факт, что мы имеем в наличии небольшой набор данных.
ЧАСТЬ 4. ПРЕИМУЩЕСТВА
В течение последних 10 лет бустинг остаётся одним из наиболее популярных методов машинного обучения, наряду с нейронными сетями и машинами опорных векторов.
Основные причины — простота, универсальность, гибкость (возможность построения различных модификаций), и, главное, высокая обобщающая способность.
Благодаря достаточной простоте метода и четкому математическому обоснованию, в каждой конкретной вариации бустинга не сложно провести некоторые математические и алгоритмические оптимизации, которые заметно ускорят работу алгоритма, поэтому этот метод считается одним из наиболее эффективных методов с точки зрения качества классификации.
Во многих экспериментах наблюдалось практически неограниченное уменьшение частоты ошибок на независимой тестовой выборке по мере наращивания композиции. Более того, качество на тестовой выборке часто продолжало улучшаться даже после достижения безошибочного распознавания всей обучающей выборки. Это перевернуло существовавшие долгое время представления о том, что для повышения обобщающей способности необходимо ограничивать сложность алгоритмов. На примере бустинга стало понятно, что хорошим качеством могут обладать сколь угодно сложные композиции, если их правильно настраивать.
ЧАСТЬ 5. НЕДОСТАТКИ
Бустинг – трудоемкий метод, и работает он достаточно медленно. Зачастую требуется построение сотен или даже тысяч базовых алгоритмов для композиции.
Кроме того, без дополнительных модификаций он имеет свойство полностью подстраиваться под данные, в том числе под ошибки и выбросы в них.
Идея бустинга обычно плохо применима к построению композиции из достаточно сложных и мощных алгоритмов. Построение такой композиции занимает очень много времени, а качество существенно не увеличивается.
И наконец, результаты работы бустинга сложно интерпретируемы, особенно если в композицию входят десятки алгоритмов.
ЧАСТЬ 6. ОБЛАСТИ ПРИМЕНЕНИЯ
Платформа Геоаналитика.
Интеллектуальная геоинформационная платформа:
Работа с потоками данных •
Автоматизированные процессы обработки и анализа геоданных •
Интерактивная аналитика •
Моделирование и машинное обучение •
Системы поддержки принятия решений и «облачные» геоинформационные сервисы.
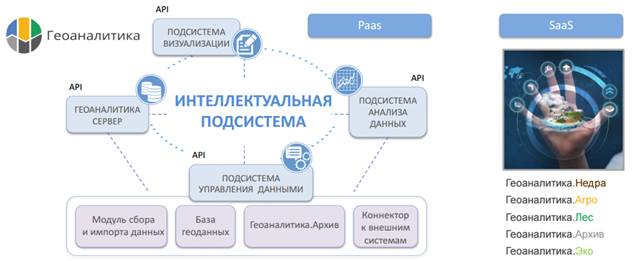
Рисунок 2. Платформа Геоаналитика.
Рисунок 3. Межстрановые сравнения.
ЗАКЛЮЧЕНИЕ
В результате выполнения учебно-исследовательской работы был рассмотрена конкретная реализация градиентного бустинга — пакет XGBoost. Подводя итоги, стоит отметить, что градиентный бустинг в XGBoost имеет ряд важных особенностей.
1. Базовый алгоритм приближает направление, посчитанное с учетом вторых производных функции потерь.
2. Отклонение направления, построенного базовым алгоритмом, измеряется с помощью модифицированного функционала — из него удалено деление на вторуюпроизводную, за счет чего избегаются численные проблемы.
3. Функционал регуляризуется — добавляются штрафы за количество листьев и за норму коэффициентов.
4. При построении дерева используется критерий информативности, зависящий от оптимального вектора сдвига.
5. Критерий останова при обучении дерева также зависит от оптимального сдвига.