Динамическое распределение памяти (его еще иногда называют управлением кучей (pool или heap)) представляет собой нетривиальную проблему. Действительно, активное использование функций malloc/free может привести к тому, что вся доступная память будет разбита на блоки маленького размера, и попытка выделения большого блока завершится неудачей, даже если сумма длин маленьких блоков намного больше требуемой. Это явление называется фрагментацией памяти. Кроме того, большое количество блоков требует длительного поиска.
В зависимости от решаемой задачи используются различные алгоритмы поиска свободных блоков памяти. Действительно, программа может требовать множество блоков одинакового размера, или нескольких фиксированных размеров. Это сильно облегчает решение проблемы фрагментации и поиска. Возможны ситуации, когда блоки освобождаются в порядке, обратном тому, в котором они выделялись. Это позволяет свести выделение памяти к стековой структуре. Возможны ситуации, когда некоторые из занятых блоков можно переместить по памяти. Так, например, функцию realloc() в ранних реализациях системы UNIX можно было использовать именно для этой цели.
В стандартных библиотеках языков высокого уровня, таких как malloc/free/realloc в C, new/dispose в Pascal и т.д., как правило, используются алгоритмы, рассчитанные на худший случай: программа требует блоки случайного размера в случайном порядке и освобождает их также случайным образом.
Возможны алгоритмы распределения памяти двух типов: когда размер блока является характеристикой самого блока, и когда его сообщают отдельно при освобождении. К первому типу относится malloc/free, ко второму - GetMem/FreeMem в Turbo Pascal. В первом случае с каждым блоком ассоциируется некоторый дескриптор, который содержит длину этого блока и еще информацию. Этот дескриптор может храниться отдельно от блока, или быть его заголовком. Иногда дескриптор состоит из двух меток - в начале блока и в его конце. Для чего это может быть полезно, будет рассказано ниже.
Обычно все свободные блоки памяти объединяются в двунаправленный связанный список. Список должен быть двунаправленным для того, чтобы из него в любой момент можно было извлечь любой блок. Впрочем, если все действия по извлечению блока производятся после поиска, то можно слегка усложнить пpоцедуpу поиска и всегда сохранять указатель на пpедыдущий блок. Это pешает пpоблему извлечения и можно огpаничиться однонапpавленным списком. Беда только в том, что многие алгоpитмы пpи объединении свободных блоков извлекают их из списка в соответствии с адpесом, поэтому для таких алгоpитмов двунапpавленный список необходим.
Поиск в списке может вестись двумя способами: до нахождения первого подходящего (first fit) блока или до блока, размер которого ближе всего к заданному - наиболее подходящего (best fit). Для нахождения наиболее подходящего мы обязаны просматривать весь список, в то время как первый подходящий может оказаться в любом месте, и среднее время поиска будет меньше.
Кроме того, в общем случае best fit увеличивает фрагментацию памяти. Действительно, если мы нашли блок с размером больше заданного, мы должны отделить «хвост» и пометить его как новый свободный блок. Понятно, что в случае best fit средний размер этого хвоста будет маленьким, и мы в итоге получим большое количество мелких блоков, которые невозможно объединить, так как пространство между ними занято.
При использовании first fit с линейным двунаправленным списком возникает специфическая проблема. Если каждый раз просматривать список с одного и того же места, то большие блоки, расположенные ближе к началу, будут чаще удаляться. Соответственно, мелкие блоки будут иметь тенденцию скапливаться в начале списка, что увеличит среднее время поиска. Простой способ борьбы с этим явлением состоит в том, чтобы просматривать список то в одном направлении, то в другом. Более радикальный и еще более простой метод состоит в том, что список делается кольцевым, и поиск каждый начинается с того места, где мы остановились в прошлый раз. В это же место добавляются освободившиеся блоки.
В ситуациях, когда размещаются блоки нескольких фиксированных размеров, алгоритмы best fit оказываются лучше. Однако библиотеки распределения памяти рассчитывают на худший случай, и в них обычно используются алгоритмы first fit.
В случае работы с блоками нескольких фиксированных размеров напрашивается такое решение: создать для каждого типоразмера свой список.
Интересный вариант этого подхода для случая, когда различные размеры являются степенями числа 2, как 512 байт, 1Кбайт, 2Кбайта и т.д., называется алгоритмом близнецов. Он состоит в том, что мы ищем блок требуемого размера в соответствующем списке. Если этот список пуст, мы берем список блоков вдвое большего размера. Получив блок большего размера, мы делим его пополам. Ненужную половину мы помещаем в соответствующий список свободных блоков. Одно из преимуществ этого метода состоит в простоте объединения блоков при их освобождении. Действительно, адрес блока-близнеца получается простым инвертированием соответствующего бита в адресе нашего блока. Нужно только проверить, свободен ли этот близнец. Если он свободен, то мы объединяем братьев в блок вдвое большего размера, и т.д.
Алгоритм близнецов значительно снижает фрагментацию памяти и резко ускоряет поиск блоков. Наиболее важным преимуществом этого подхода является то, что даже в наихудшем случае время поиска не превышает. Это делает алгоритм близнецов труднозаменимым для ситуаций, когда необходимо гарантированное время реакции - например, для задач реального времени. Часто этот алгоритм или его варианты используются для выделения памяти внутри ядра ОС. Например, функция kmalloc, используемая в ядре ОС Linux, основана именно на алгоритме близнецов.
Разработчик программы динамического распределения памяти обязан решить еще одну важную проблему, а именно - объединение свободных блоков. Наилучшим из известных универсальных алгоритмов динамического распределения памяти является алгоритм парных меток с объединением свободных блоков в двунаправленный кольцевой список и поиском по принципу first fit. Этот алгоритм обеспечивает приемлемую производительность почти для всех стратегий распределения памяти, используемых в прикладных программах. Такой алгоритм используется практически во всех реализациях стандартной библиотеки языка C и во многих других ситуациях. Другие известные алгоритмы либо просто хуже, чем этот, либо проявляют свои преимущества только в специальных случаях.
К основным недостаткам этого алгоритма относится отсутствие верхней границы времени поиска подходящего блока, что делает его неприемлемым для задач реального времени.
Некоторые системы программирования используют специальный метод освобождения динамической памяти, называемый сборкой мусора. Этот метод состоит в том, что ненужные блоки памяти не освобождаются явным образом. Вместо этого используется некоторый более или менее изощренный алгоритм, следящий за тем, какие блоки еще нужны, а какие - уже нет.
Самый простой метод- отличать используемые блоки от ненужных - считать, что блок, на который есть ссылка, нужен, а блок, на который ни одной ссылки не осталось - не нужен. Для этого к каждому блоку присоединяют дескриптор, в котором подсчитывают количество ссылок на него. Каждая передача указателя на этот блок приводит к увеличению счетчика ссылок на 1, а каждое уничтожение объекта, содержавшего указатель - к уменьшению.
Все остальные методы сборки мусора так или иначе сводятся к поддержанию базы данных о том, какие объекты на кого ссылаются. Использование такой техники возможно практически только в интерпретируемых языках типа Lisp или Prolog, где с каждой операцией можно ассоциировать неограниченно большое количество действий.
Многозадачная или многопрограммная ОС также должны использовать тот или иной алгоритм размещения памяти. Такие алгоритмы могут быть похожи на работу malloc. Однако режим работы ОС может вносить существенные упрощения в алгоритм.
Так, например, пpоцедуpа управления памятью MS DOS рассчитана на случай, когда программы выгружаются из памяти только в порядке, обратном тому, в каком они туда загружались. Это позволяет свести управление памятью к стековой дисциплине.
Каждой программе в MS DOS отводится блок памяти. С каждым таким блоком ассоциирован дескриптор, называемый MCB - Memory Control Block. Этот дескриптор содержит размер блока, идентификатор программы, которой принадлежит этот блок и признак того, является ли данный блок последним в цепочке. Нужно отметить, что программе всегда принадлежит несколько блоков, но это уже несущественные детали. Другая малосущественная деталь та, что размер сегментов и их адреса отсчитываются в параграфах размером 16 байт. После запуска.com-файл получает сегмент размером 64К, а.exe - всю доступную память. Обычно.exe-модули сразу после запуска освобождают ненужную им память и устанавливают brklevel на конец своего сегмента, а потом увеличивают brklevel и наращивают сегмент по мере необходимости. Естественно, что наращивать сегмент можно только за счет следующего за ним в цепочке MCB, и MS DOS разрешит делать это только в случае, если этот сегмент не принадлежит никакой программе.
При запуске программы DOS берет последний сегмент в цепочке, и загружает туда программу, если этот сегмент достаточно велик. Если он недостаточно велик, DOS «говорит» Not enough memory и отказывается загружать программу.
При завершении программы DOS освобождает все блоки, принадлежавшие программе. При этом соседние блоки объединяются. Пока программы, действительно, завершаются в порядке, обратном тому, в котором они запускались, - все вполне нормально. Другое дело, что в реальной жизни возможны отклонения от этой схемы.
Например, неявно предполагается, что TSR-программы (Terminate, but Stay Resident) никогда не пытаются завершиться. Другой пример - отладчики обычно загружают программу в обход обычной DOS-овской функции LOAD & EXECUTE, а при завершении отлаживаемой программы сами освобождают память из-под нее.
В системах с динамической сборкой первые две проблемы не так остры, потому что память выделяется и освобождается небольшими кусочками, по блоку на каждый объектный модуль, поэтому код программы обычно не занимает непрерывного пространства. Соответственно, такие системы часто разрешают и данным программы занимать несмежные области памяти.
Для достижения гибкого динамического распределения памяти, устранения ее фрагментации, а также создания значительных удобств для программирования в современных ОС широко используется виртуальная память. При этом на всех этапах подготовки программ, включая загрузку в оперативную память, программа представляется в виртуальных адресах и лишь при самом исполнении машиной команды производится преобразование виртуальных адресов в адреса действующей памяти (в так называемые физические адреса). Это преобразование составляет содержание динамического распределения памяти.
Объем виртуального адресного пространства может даже превосходить всю доступную реальную память на ЭВМ. Содержимое виртуальной памяти, неиспользуемой программой, хранится на некотором внешнем устройстве (внешней памяти). По необходимости части этой виртуальной памяти отображаются в реальную память. Ни о внешней памяти, ни о ее отображении в реальную память программа ничего не знает. Она написана так, как будто бы виртуальная память существует в действительности (рис. 2.).
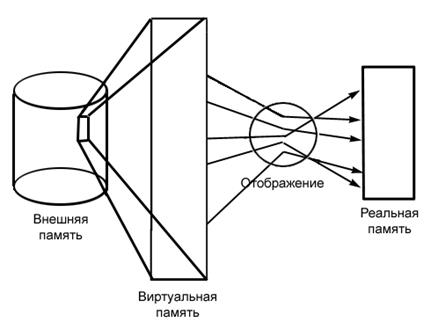
Рис.2. Основная концепция виртуальной памяти
При страничной организации основная память делится на блоки фиксированного размера, обычно называемые рамка страниц. Каждая программа пользователя делится на блоки сответствующего размера, называемые страницами. Страницы организуются в логическом адресном пространстве, а рамки cтраниц - в физическом. Поскольку страницы и рамки страниц имеют различные идентификаторы, возникают интересные ситуации, касающиеся взаимосвязи между логическим адресным пространством (ЛАП) и физическим адресным пространством ФАП).
1. ЛАП < ФАП. В этом случае основной акцент делается на повышение эффективности использования памяти.
2. ЛАП = ФАП. Страничная организация служит не только для увеличения эффективности использования памяти, но и для расширения возможности разделенного использования процедур (т.е. несколькими пользователями). Возможно использование эффективного оверлейного механизма, реализованного аппаратно.
3. ЛАП > ФАП. Этот случай предполагает виртуальную память и дает наибольшие преимущества.
Мы будем рассматривать управление страницами применительно к последнему случаю. Выбор между случаями 1 и 2 обычно находится в зависимости от структуры Устройства Управления Памятью (УУП) и задач проектировщика операционной системы. Пользователь, располагая ЛАП из m страниц, будет иметь k страниц, отведенных под интерпретатор, и m - k страниц рабочего пространства. Описанный подход эффективен для системы с разделением времени.
Идентификация. Страницы и рамки страниц с набжают числовыми идентификаторами, устанавливаемыми по следующему правилу.
Пусть p есть размер страницы в словах (например, 512).
Пусть т есть размер основной памяти в словах, такой, что m=n*p по модулю 1024 есть 0; р по модулю 2К есть 0 и i*p=j*1024. Таким образом, основная память состоит из участков по 1К слов в каждом. Кроме этого, размер страницы есть степень числа 2, а 1К памяти содержит четное число страниц. Набор целых чисел 0, 1, 2,..., п- 1 соответствует идентификаторам страничных рамок.
Пусть М есть размер программы пользователя в словах. Для размещения этой программы в памяти необходимо N страниц, так что М=N*p. Набор целых чисел от 0 до п- 1 соответствует идентификаторам страниц пользователя. Заметим, что требование равенства нулю m по модулю р не является обязательным. Это означает, что программа пользователя не должна заполнять целиком все страницы. Последняя страница может быть заполнена лишь частично.
Используя двоичную арифметику, - представление страницы степенью числа 2 легко реализуемо. Фактически в большинстве машин имеются команды сдвига, делающие генерацию виртуального адреса очень простой операцией. Требование задания М кратным 1К является результатом стандартизации. В последнее время принято считать, что размер 8К, 16К и даже 64К более предпочтителен.
Конструкция виртуального адреса. Виртуальный адрес - это адрес логического пространства процесса пользователя (обычно для случая ЛАП >ФАП). Все ссылки к логическому пространству должны быть преобразованы в физический адрес основной памяти. Для этого системе необходимы идентификатор рамки страницы и смещение внутри нее. Система должна преобразовать виртуальный адрес в физический. Каждый виртуальный адрес есть пара (р, i), где р - номер страницы процесса пользователя, а i- индекс страницы (такой, что i<w, где w -размер страницы).
Предположим, что машина имеет 16-бит слово, позволяющее ей адресоваться к 64К слов. Если размер страницы составит 512 слов, то логическое адресное пространство будет состоять из 128 страниц. Для идентификатора р необходимо 7 бит, а для индекса 9 бит. Полное 16-бит слово будет иметь вид
| Идентификатор - страницы | Индекс - слова |
Отметим, что случай ЛАП<ФАП возможен, если устройство управления памятью обеспечивает размер слова, больший чем 18 бит. На ЭВМ серии PDP-11/70 ЛАП каждого пользователя ограничено 64К байт, в то время как УУП поддерживает 128К слов. В ЭВМ серии VAX-11/780 фирмы DEC адресное пространство каждого пользователя составляет 232, а максимальный физический размер основной памяти может достигать 16М байт. В ЭВМ серии VAX-11/780 используется 32-бит слово, имеющее следующую конструкцию:
| Вид виртуальной Страницы | Байт в странице |
где биты 31 и 30 имеют специальное назначение для;VAX/VMS;биты 29 - 9 адресуются к одной из 220страниц;биты 7 - 0 выбирают один из 512 байт в странице.
На ЭВМ, имеющей 16-бит размер слова, большой виртуальный адрес может быть составлен из двух слов. Он может иметь, например, такой вид:
| Номер | страницы |
| Байт в | странице |
Роль таблицы страниц. Одним из достоинств страничной организации является динамическое распределение страниц пользователя в любом месте памяти. Так, страница Р процесса
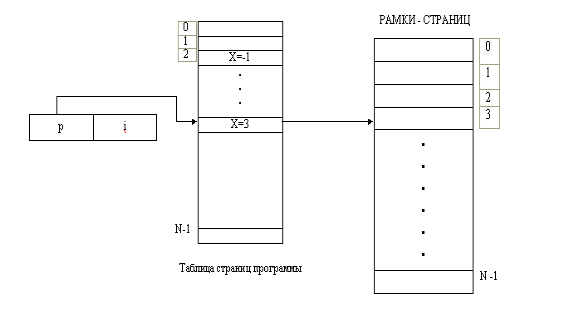
Рис. 3.Отображение страницы на основную память.
Виртуальный адрес = (р,i). Физический адрес - x = размер страницы + i. Отрицательное значение идентификатора рамки страницы указывает на то, что страница в данный момент отсутствует в памяти
пользователя может в некоторый момент занимать страничную рамку р в физической памяти. Поскольку у каждого из пользователей имеется свой набор страниц, каждой программе необходима карта, отображающая взаимосвязь между страницами и рамками страниц. На рис. 1 виртуальный адрес (p, i) преобразовывается в физический, поиском в таблице страниц идентификатора х для рамки страницы. Реальный адрес образуется умножением х на размер страницы и прибавлением к полученному результату индекса i.
Важно отметить, что эти операции осуществляются УУП согласованно с программой пользователя. Для этого копия таблицы страниц процесса должна быть загружена в УУП.

Рис. 3. Обобщенная процедура страничного обмена. Блок # - это адрес рамки страницы в основной памяти (поэтому умножения на размер страницы не требуется).
Например, предположим, что УУП располагает пространством для 16 карт памяти, а каждая карта памяти содержит поля (элементы) для 64 страниц по 512 слов в каждой. Карта с номером 0 всегда принадлежит ядру операционной системы. Такой подход не может быть реализован для систем с большим объемом виртуальной памяти, так как стоимость УУП будет чрезмерно большой. В этом случае карта остается в основной памяти, а УУП управляет текущей картой пользователя с помощью указателей. На рис.2 приведена структура, соответствующая такой схеме.
По этой схеме УУП поддерживает список адресов таблиц для n пользователей. Аппаратно реализованный регистр служит для указания текущего пользователя, т.е. пользователя, чья таблица страниц является в настоящий момент активной. Элемент таблицы, содержащий карту пользователя (в УУП), загружается в аппаратный регистр базы таблицы страниц. Каждый адрес памяти содержит идентификатор страницы и индекс. Идентификатор страницы в комбинации с содержимым базового регистра таблицы страниц указывает на элемент таблицы страниц. Содержимым этого элемента является адрес рамки страницы в памяти. Добавляя индекс к адресу рамки страницы, мы получаем физический адрес.
Отметим, что при такой схеме каждая ссылка таблицы страниц требует дополнительного доступа к памяти для извлечения адреса рамки страницы. В предыдущем случае все вычисления основывались на использовании аппаратных регистров УУП. Таким образом, применение виртуальной памяти большого объема может привести к временным задержкам в системе и увеличению общего времени работы программы. Разработчик системы должен учитывать эти факторы при выборе способа управления памятью на этапе проектирования системы.
Контрольные биты страниц. С каждым элементом таблицы связывается набор контрольных битов. Эти биты служат для указания стратегии управления страницами. Количество и тип этих битов определяются примененным УУП. Биты, приведенные ниже, характерны для аппаратной части большинства систем.
1. БИТ-ПРИСУТСТВИЯ указывает, находится ли страница в данный момент в основной памяти.
2. БИТ(Ы)-АКТИВНОСТИ указывает на использование за последнее время данной страницы процедурами страничного обмена.
3. БИТ-ИЗМЕНЕНИЯ указывает на то, что содержимое страницы памяти изменялось (или не изменялось) с момента ее загрузки в память.
Бит присутствия анализируется при каждой адресной ссылке программы пользователя. Равенство его нулю означает, что страница была удалена из памяти. Бит изменения определяет необходимость записи страницы на диск при ее замене в памяти. Единичное его значение означает, что в содержимом страницы были сделаны изменения, и, следовательно, она должна быть записана на диск. (Нулевое значение предполагает использование прежней копии.) В системах, в которых страницы инструкций (в противоположность страницам данных) являются реентерабельными, бит изменения никогда не устанавливается.