(долгая краткосрочная память)
 |
Рекуррентная НС состоит из срезов, и информация (hi) передается из левых блоков в правые:
Вдохновляясь сверточной НС ResNet, в которой очередной слой НС информация от первого слоя до далеко идущего вперед слоя не может дойти без потерь, поэтому в ResNet есть прямая связь между далекими слоями, которая просто копирует выход этого слоя:
 |
Это позволяет распростронять информацию дальше. Если константа t в RNN очень большая, то в процессе тренировки сеть может забить на слишком далекую информацию, поэтому, нужно сделать то же самое, что и в ResNet: нужно научиться перекидывать информацию из далеких ячеек в последнюю ячейку xt. Это непросто, потому что далеких ячеек у нас много, и непонятно, какую взять из них и перекинуть из неё информацию дальше, поэтому нужно брать всю информацию из всех далеких ячеек и передавать её в последние ячейки, но из-за последующего очень сильного усложнения архитектуры НС так не делают.
На практике используется следующее: информацию, которая содержится в самых первых ячейках, будем архивировать (для экономии) и передавать дальше. Помимо вектора h пустить ещё вектор c, который в сжатом виде содержит информацию из всех предыдущих ячеек, в том числе, из самых дальних. Но по какому принципу понять, какую информацию архивировать, и какая ячейка – наиболее важная, т.е. будут давать больше информации, а какие – неважные? Вектор с имеет фиксированный размер, то есть, если у нас каждый слой нейронной сети передает дальше число h, то и c должно быть число. Если h – вектор, то и c должен быть вектором той же размерности.
По каким правилам будем складировать информацию в архив ci?
1) Нужно посчитать % данных для удаления.
2) Нужно посчитать % новых данных
3)
 |
С помощью ci вычислить новое hi
Проценты подбираются опытным путем, их оптимальные значения достигаются во время тренировки. Эти данные определяются по следующим формулам. Промежуточное c’:

Окончательное c считается так:

где 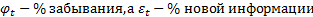
То есть, с такой интенсивностью мы забываем информацию, которая пришла из старых ячеек. То есть, вероятность забыть и вероятность добавить. Процент забывания информации считается с помощью сигмоиды:

Процент новой информации считается также с помощью сигмоиды:

Далее с помощью ct считаем новый h, который подается на вход в следующий слой и на выход.
Грубо говоря, LSTM – метод, который позволяет в заархивированном виде информацию из далеких ячеек подогнать в очередную ячейку xt, при чем архивация умная – в процессе сортировки она сама отмеряет, сколько на каждом шаге забыть, сколько новой информации – добавить. Она этому учится, потому что возникают новые параметры, которые тоже учатся в процессе тренировки НС. После этого, когда будут найдены оптимальные значения параметров, мы получим оптимальный способ архивации наших данных из далеких ячеек - наиболее значимая информация передается без потерь.