Все приведенные здесь примеры даны на псевдокоде, близком к языку СУБД Oracle (синтаксис для других СУБД мало чем отличается).
Хранимые (присоединенные, разделяемые и т.д.) процедуры. Использование хранимых процедур БД преследует четыре цели:
1) обеспечивается новый независимый уровень централизованного контроля доступа к данным, осуществляемый АБД;
2) одна процедура может использоваться несколькими ПП. Это позволяет существенно сократить время написания программ за счет оформления их общих частей в виде процедур БД (общих библиотек). Процедура компилируется и помещается в БД и становится доступной для многократных
вызовов. Так как план ее выполнения определяется единожды при компиляции, то при последующих вызовах процедуры фаза оптимизации опускается, что значительно экономит вычислительные ресурсы системы;
3) использование хранимых процедур БД позволяет значительно снизить трафик сети. Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры;
4) хранимые процедуры в сочетании с триггерами (правилами), о которых речь пойдет ниже, предоставляет администратору мощные средства поддержки целостности данных.
Различают хранимые процедуры, функции и пакеты. Функция, в отличие от процедуры, возвращает в вызывающую программу одно значение, а процедура ничего не возвращает. Процедуры и функции могут также возвращать значения через параметры. С помощью пакета описывается совокупность (библиотека) функций и/или процедур. Ниже приведены структуры хранимой процедуры и функции.
Процедура
CREATE PROCEDURE имя (параметры) IS
переменные процедуры;
BEGIN
тело процедуры, включающее операторы языка SQL,
условий (IF), циклов (LOOP, FOR и т.д.) и присваивания;
END;
Функция
CREATE FUNCTION имя (параметры) RETURN тип
возвращаемого значения IS
переменные функции;
BEGIN
тело функции, включающее операторы языка SQL,
условий (IF), циклов (LOOP, FOR и т.д.) и присваивания;
RETURN возвращаемое значение;
END;
Пример. Предположим, что перед выполнением операции банкомат запрашивает хранимую функцию для проверки номера счета и наличия требуемой суммы на счете. Спецификации этой функции имеют вид
CREATE FUNCTION проверка(номер IN NUMBER, сумма IN NUMBER)
RETURN NUMBER IS
numrows INTEGER;
i INTEGER;
BEGIN
SELECT COUNT(*) INTO numrows
FROM счет
WHERE номер счета = номер AND
сумма счета >= сумма;
IF(numrows>0)
THEN
/* разрешить операцию */
i:=1;
ELSE
/* запретить операцию */
i:=0;
END IF;
RETURN i;
END;
Здесь с помощью оператора SELECT определяется число таких записей в таблице «счет», у которых номер счета (столбец «номер счета») в записи совпадает с запрашиваемым номером (параметр «номер») и сумма на счете (столбец «сумма счета») была бы не меньше запрашиваемой суммы (параметр «сумма»). Если число таких строк (numrows) больше нуля, то операция выдачи денег разрешается, в противном случае запрещается.
Эта процедура запрашивается из ПП, обслуживающей банкомат. Ниже приведены спецификации запроса:
1) для языка PL/SQL:
j:= проверка(номер, сумма);
2) для языка Pro*C (Tuxedo):
EXEC SQL EXECUTE
BEGIN
j = проверка(:номер,:сумма);
END;
END-EXEC;
Хранимые процедуры могут быть включены в СУБД при создании БД и ее таблиц или позднее.
Триггеры (правила).Триггер – это процедура, автоматически запускаемая ядром СУБД при выполнении определенных условий изменения таблицы, задаваемых при описании триггера. Задача триггера – это реализация некоторых внешних правил.
Ниже приведена структура триггера.
CREATE TRIGGER имя
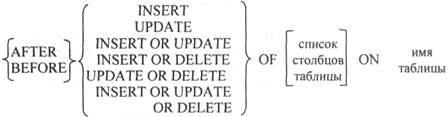
[FOR EACH ROW]
[WHEN (дополнительное условие срабатывания триггера)]
[DECLARE
переменные триггера;]
BEGIN
тело триггера, включающее операторы языка SQL, условий,
циклов, присваивания, вызова хранимых процедур или циклов;
FND;
Здесь фигурными скобками обозначены альтернативные значения ключевых слов, а квадратными скобками – необязательные параметры. В табл. 12.1 подробно представлены параметры описания триггера.
Таблица 12.1. Параметры описания триггера


Пример. Пусть требуется оповещать оператора банкомата в том случае, если число купюр в банкомате становится меньше 100. Ниже приведены спецификации соответствующего триггера.
CREATE TRIGGER оповещение
AFTER UPDATE OF кол.купюр ON банкомат
FOR EACH ROW
WHEN (:new.кол.купюр < 100)
BEGIN
сообщение(...);
END;
В данном случае хранимая процедура «сообщение» посылает оператору банкомата письмо (например, по электронной почте) о необходимости обслужить устройство.
Также как и хранимые процедуры, триггеры могут быть включены в СУБД при создании БД и ее таблиц. Следует помнить, что некоторые CASE-средства (например, Erwin) автоматически генерируют некоторые триггеры для поддержки ограничений целостности базы данных (см. ниже пример для Erwin).
Современные инструментальные средства разработки приложений. В настоящее время разработано много средств (более 50) для создания клиентских приложений в архитектуре клиент/сервер (К/С), являющейся основной для распределенных систем: Delphi, Uniface Six 6.1, SQL Windows, Gupta, Informix-4GL, Informix NewEra, JAM 7 (JYACC), MS Access Up-sizing Tools, Designer/2000, Developer/2000, Power Builder Desktop, Sybase APT Workbench и др.
Основные операторы манипулирования данными языка SQL. Язык SQL является основным языком описания и манипулирования данными в распределенных системах. Для обращения к данным используют четыре оператора: SELECT (найти), INSERT (вставить), UPDATE (обновить), DELETE (удалить). Кратко рассмотрим эти операторы.
Оператор SELECT (найти записи в таблицах БД).Оператор SELECT используется в приложениях очень часто. Упрощенное описание этого оператора имеет вид
SELECT список_столбцов_таблиц
FROM список_таблиц
[WHERE условие_поиска]
[ORDER BY список_столбцов]
[GROUP BY список_столбцов HAVING подусловие];
Пример. Пусть созданы две таблицы «Клиент» и «Счет».
Клиент (Код клиента, Адрес клиента)
Счет (Код клиента, Номер счета, Тип счета, Остаток)
Предположим, что необходимо реализовать следующий абстрактный запрос: найти адреса клиентов при условии, что код клиента меньше 1000, тип счета равен 1 и остаток на счете меньше 100; упорядочить результаты по адресам. Спецификации соответствующего оператора SELECT выглядят следующим образом:
SELECT Адрес клиента
FROM Клиент
WHERE Код клиента < 1000
AND
Код клиента IN
(SELECT Код клиента
FROM Счет
WHERE Тип счета = 1 AND Остаток < 100)
ORDER BY Адрес клиента;
Это пример сложного запроса, так как здесь имеется вложенный подзапрос SELECT. В данном примере операнд IN указывает на то, что будет выполняться операция соединения таблиц «Клиент» и «Счет» по столбцу «Код клиента».
Запрос будет выполняться ядром СУБД в такой последовательности.
1. В таблице «Клиент» выделяются строки с «Код клиента» < 1000, затем выполняется вложенный подзапрос SELECT к таблице «Счет».
2. Строится декартово произведение полученных промежуточных таблиц.
3. В соответствии с оператором IN из декартова произведения извлекаются строки с одинаковыми значениями столбцов «Код клиента» (выполняется операция соединения таблиц)
4. Из полученной таблицы выделяется столбец «Адрес клиента», его строки упорядочиваются по алфавиту и передаются либо программе (если запрос сделала программа), либо на экран (если пользователь закодировал этот запрос в диалоговой оболочке).
Рассмотренный пример будет использован в следующем пункте для демонстрации механизма оптимизации запросов в распределенной системе.
Оператор INSERT (вставить запись(и) в таблицу БД). Рассмотрим два варианта кодирования оператора INSERT:
1) INSERT INTO имя_таблицы (имя_столбца1,..., имя_столбцаN)
VALUES (значение1,..., значениемN);
2) INSERT INTO имя_таблицы1 (список_столбцов_таблицы1)
SELECT список_столбцов_таблицы2
FROM имя таблицы2
WHERE условие_поиска;
Второй вариант оператора INSERT обычно используют для заполнения временных таблиц. Ясно, что таблица1 должна быть заранее создана с помощью оператора CREATE TABLE.
Оператор UPDATE (изменение попей (столбцов) существующих записей таблицы):
UPDATE имя_таблицы SET имя_поля=значение,...,
имя_поля=значение
[WHERE условие поиска];
Оператор UPDATE обновляет все записи таблицы, удовлетворяющие условию поиска.
Оператор DELETE (удаление записей таблицы):
DELETE FROM имя таблицы
[WHERE условие поиска];
Оператор DELETE удаляет из таблицы все записи, удовлетворяющие условию поиска.

Рис. 12.17. Оптимальный план выполнения запроса
Оптимизация запросов к распределенной базе данных. Для сложных запросов к БД, содержащих предложения SELECT (операторы SELECT и INSERT, вложенные запросы в операнде WHERE операторов UPDATE и DELETE), сервер СУБД выполняет оптимизацию, т.е. строит оптимальный план реализации этого запроса. При этом СУБД выполняет следующие действия:
• декомпозирует предложение SELECT на несколько подзапросов, каждый из которых связан с одной таблицей БД;
• реализует параллельное выполнение этих подзапросов;
• выполняет соединение результатов обработки подзапросов.
Рассмотрим пример запроса SELECT (см. выше). Когда этот запрос поступает на обработку, то сервер СУБД строит для этого запроса оптимальный план выполнения (рис. 12.17).
Сначала исходный запрос S 1преобразуется в формулу реляционной алгебры. Используя законы этой алгебры, СУБД выполняет оптимизацию этой формулы, а затем преобразует оптимизированную формулу в совокупность подзапросов (S 2, S 3 и S 4).
Подзапросы S 2 и S 3 могут быть выполнены параллельно в следующих случаях.
1. Сервер СУБД функционирует на SMP-компьютере и задействовано средство параллельной обработки; подзапросы выполняются на разных процессорах.
2. Таблицы «Клиент» и «Счет» хранятся на разных компьютерах и в СУБД задействовано средство распределенной обработки; подзапросы выполняются на разных узлах системы. Затем таблица R2 (она имеет меньший объем данных) передается на узел, где получена таблица R1, и там выполняется соединение этих таблиц.
Оптимизация запросов повышает эффективность их выполнения. В данном случае это проявляется в следующем:
• подзапросы S 2и S 3 выполняются параллельно,
• соединяемые таблицы R 1и R 2имеют меньшую размерность (число строк и столбцов), чем исходные таблицы клиент и счет.
Подзапрос S 4, выполняющий соединение больших промежуточных таблиц, также может быть декомпозирован (рис. 12.18). В этом случае подзапрос S 5 будет соединять подтаблицы S 3 и S 4 с кодом клиента не более 500, а подзапрос S 6 – подтаблицы R 1и R 2с кодом клиента больше 500 и меньше 1000 (см. подзапрос S2).
Таким образом, подзапросы S 5и S 6 параллельно обрабатывают (например, на SMP-компьютере) как бы по половине (хотя на самом деле это может быть и не так) таблиц R 1и R 2.
Рекомендации по кодированию операторов SQL. Язык SQL относится к классу непроцедурных языков, т.е. программист указывает, что он хочет получить, но не определяет, как это сделать. Последовательность операций выполнения SQL-оператора определяет ядро СУБД. Поэтому с виду невинный SQL-оператор программы может вызвать перегрузку сервера СУБД.
Большинство рекомендаций по кодированию SQL-запросов связано с применением индексов. Поэтому прежде всего рассмотрим, как СУБД использует индексы для поиска данных.
Пусть в БД хранится некоторая таблица Счет (рис. 12.19). Числа в этой таблице вымышленные.
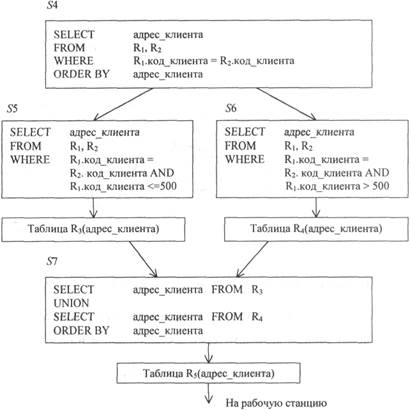
Рис. 12.18. Декомпозиция подзапроса соединения

Рис. 12.19. Пример первых девяти строк таблицы «Счет»

Здесь Номер счета – это первичный ключ таблицы. Для такого ключа СУБД, как правило, автоматически строит индекс. Предположим, что в системе часто выполняются запросы SELECT с ограничениями, которые накладываются на столбцы Код клиента и Тип счета. В этом случае целесообразно построить сложный (составной индекс):
CREATE INDEX имя индекса ON счет (код клиента, тип счета)
СУБД ведет индекс автоматически в специальном индексном файле. Индекс представляет собой совокупность иерархически связанных блоков данных, имеющих специальную структуру (рис. 12.20). Минимальное число уровней иерархии в индексе равно 3. Каждому оператору CREATE INDEX соответствует свой индекс. Рассмотрим организацию индекса.
Блоки всех уровней, кроме последнего, имеют следующую структуру: в первых двух столбцах хранятся значения атрибутов «Код клиента» и «Тип счета», а третий столбец содержит ссылку на блок индекса более высокого уровня. В третьем столбце блока последнего уровня индекса хранятся номера записей таблицы Счет. Например, номер записи 9 означает, что в 9-й записи таблицы Счет хранятся код клиента и тип счета, равные 1 и 1. Строки каждого блока индекса лексикографически упорядочены (упорядочены коды) по значениям атрибутов, т.е. сначала строки упорядочены по атрибуту «Код клиента», а затем – по атрибуту «Тип счета».
Рассмотрим, как выполняется поиск записей с помощью индекса. Пусть на сервер поступил запрос:
SELECT остаток
FROM счет
WHERE код клиента = 1 AND тип счета <= 4;
СУБД формирует код 14 и начинает поиск с корня индекса. В корне индекса выбирается первая строка, так как она единственная в блоке. Далее по указателю считывается блок индекса 2-го уровня. В этом блоке выполняется поиск первой строки, значения атрибутов которой превышают код 14, и затем выполняется возврат на строку выше. В данном случае будет выбрана 1-я строка, так как во второй строке блока хранится код 21 > 14. Далее по указателю считывается первый блок 3-го уровня и здесь выбираются строки, для которых выполняется неравенство 10 < (Код клиента, Тип счета) < 14. Этому требованию удовлетворяют все три строки считанного блока 3-го уровня. Таким образом, условию поиска удовлетворяют записи с номерами 9, 2, 3. Затем эти записи считываются из таблицы Счет и их поля Остаток помещаются в результирующую таблицу (см. рис. 12.19).
Использование индексов для больших таблиц очевидно. Предположим, что в таблице Счет хранится 1 млн записей. Если бы таблица Счет не была индексирована по атрибутам Код клиента и Тип счета, то для проверки условия серверу СУБД необходимо было бы считать 1 млн записей. В данном же случае СУБД просмотрела только три блока индекса и считала три записи.
Следует отметить, что использование индексов приводит к увеличению времени обновления таблицы. Предположим, выполняется оператор включения новой записи в таблицу Счет:
INSERT INTO счет (номер счета, код клиента, тип счета, остаток)
VALUES (15, 1, 3, 55);
Пусть номер первой пустой записи в таблице Счет равен 10. Сделаем упрощающее предположение, что максимальное число строк в каждом блоке индекса равно 3 (см. рис. 12.20). СУБД не только включает новую запись в таблицу, но и обновляет индекс.
Сначала ядро СУБД формирует код 13 (код клиента и тип счета в новой записи). В индексе выполняется поиск блока 3-го уровня, где хранится строка с наименьшим кодом, удовлетворяющим условию (код клиента, тип счета) > 13. Это третья строка первого блока 3-го уровня (14 > 13). Перед этой строкой и должна быть включена новая строка (1, 3, 10). Но этот блок заполнен. В этом случае СУБД выполняет следующие действия: запрашивается память под еще один блок 3-го уровня, верхняя половина строк первого блока (3-го уровня) остается в нем, а нижняя строка вместе с новой переписывается в новый блок. Так как появился новый блок 3-го уровня, то в блок 2-го уровня необходимо включить новую строку с указателем на этот новый блок. Но блок 2-го уровня заполнен. Поэтому создается новый блок 2-го уровня и в блок 1-го уровня помещается новая строка с указателем на этот новый блок. В результате формируется индекс, показанный на рис. 12.21.
Так как при включении новой строки в заполненный блок выполняется его «расщепление» (т.е. из одного блока получаются два), то индекс называется B -деревом (В означает Bindery).

Ниже приведены рекомендации по кодированию операторов SELECT.
1. Если таблица имеет много записей, то важно следить, чтобы в условии поиска хотя бы один аттрибут (столбец) был индексирован. Например, запрос
SELECT код клиента
FROM счет
WHERE остаток < 100 AND остаток > 80;
приведет к перебору всех записей таблицы Счет.
2. По возможности не используйте операцию NOT (не) для индексированных аттрибутов. Например, запрос
SELECT код клиента, остаток
FROM счет
WHERE NOT(номер счета = 3);
Будет выполняться долго, так как в этом случае СУБД будет работать по следующему алгоритму (здесь предполагается, что атрибут Номер счета индексирован):
• считать из индекса все номера записей (список U1); при большой таблице этих номеров может быть много;
• считать из индекса номера записей, удовлетворяющих условию «номер счета = 3» (список U2);
• найти разность списков (U3 = Ul - U2), т.е. исключить из U1 номера, содержащиеся в списке U2;
• читать записи с номерами из списка U3.
При выполнении запроса
SELECT код клиента, остаток
FROM счет
WHERE код клиента < 10 AND
тип счета =1 AND
NOT(номер счета = 3);
СУБД организует поиск записей по сложному индексу (код клиента, тип счета) и уже после их чтения отфильтрует записи с условием «номер счета = 3».
3. Если создан сложный индекс (см. выше), то не используйте второй атрибут отдельно от первого в условии поиска, например:
SELECT код клиента, остаток
FROM счет
WHERE тип счета = 3;
Отсюда можно было ожидать, что для выполнения запроса СУБД использует индекс. Однако, так как запрос не ссылается на первую часть сложного индекса (код клиента), СУБД не будет использовать этот индекс, что приведет к перебору всех записей таблицы Счет. Использование в условии поиска атрибутов Код клиента и Тип счета или одного атрибута Код клиента приведет к поиску записей с помощью индекса.
Приведем еще несколько рекомендаций по созданию индекса.
1. Индексируемая таблица не должна быть слишком маленькой. Если СУБД может записать все строки таблицы всего в несколько блоков данных, то создавать индекс нет смысла. Объем ввода/вывода при обращении к строкам таблицы от этого не уменьшится.
2. Если для работы с таблицей очень часто используются операторы INSERT, UPDATE, DELETE, то большое число индексируемых атрибутов может привести к существенному увеличению времени выполнения этих операторов из-за значительных временных затрат на модификацию индексов.
3. Если часто выполняется поиск по какой-либо группе атрибутов, то рекомендуется построить сложный индекс для этих атрибутов.
4. Рекомендуется индексировать атрибуты, которые имеют сравнительно большое число различных значений. В этом случае уменьшается число номеров записей на одно значение атрибута, что сокращает время выполнения операций с индексными списками.
По возможности следует не использовать соединения таблиц и вложенных подзапросов, при выполнении которых также применяется операция соединения. Известно, что эта операция является самой ресурсоемкой в реляционных СУБД. Чтобы уменьшить время поиска в больших связанных таблицах, эти таблицы объединяют в одну таблицу. Например, если таблицы Клиент и Счет объединить в одну таблицу Счет, то сложный запрос можно существенно упростить. При выполнении этого запроса соединять таблицы не требуется:
Счет (Номер счета, Тип счета, Код клиента, Адрес клиента, Остаток)
SELECT адрес клиента
FROM счет
WHERE код клиента < 1000 AND
остаток < 100 AND
тип счета =1
ORDER BY адрес клиента;
Особенности разработки приложений для работы с базой данных в сети. При многопользовательском доступе к серверу СУБД приложение и СУБД должны обеспечивать
• блокировку обновляемых записей БД,
• ведение логических транзакций,
• обработку тупиковых ситуаций.
Блокировка обновляемых записей БД. Большинство СУБД автоматически блокирует записи БД при их обновлении.
Пример. Пусть в БД хранится таблица Счет и две операционистки банка одновременно выполняют следующие операции: первая операционистка переводит со счета 100 на счет 1001 условную сумму 300, а вторая операционистка перечисляет со счета 1001 на счет 100 условную сумму 150.
Предположим, что разработана одна хранимая процедура на языке PL/SQL Oracle для выполнения указанных операций:
1 CREATE PROCEDURE проводка (номер 1 IN NUMBER, номер 2 IN NUMBER, сумма IN NUMBER) IS
2 CURSOR курсор (ном_счета 1 NUMBER, ном_счета 2 NUMBER) IS
SELECT номер, остаток
FROM счет
WHERE номер=ном_счета 1 OR номер=ном_счета 2
FOR UPDATE OF остаток;
3 запись курсор%ROWTYPE;
4 BEGIN
5 OPEN курсор (номер 1, номер 2);
6 LOOP
7 FETCH INTO;
8 EXIT WHEN курсор % NOTFOUND;
9 IF запись.номер = номер 1
THEN запись.остаток:=запись.остаток-сумма;
ELSE запись.остаток:=запись.остаток+сумма;
END IF;
10 UPDATE счет SET остаток=запись.остаток
11 END LOOP;
12 CLOSE курсор;
13 COMMIT;
14 END;
Обращение к этой процедуре может быть выполнено из программы, выполняющейся на рабочей станции:
1) на рабочей станции первой операционистки – проводка (100, 1001, 300);
2) на рабочей станции второй операционистки – проводка (1001, 100, 150);
Конечно, эту задачу можно решить и по-другому, но здесь демонстрируется использование курсора, связывающего непроцедурный язык SQL с процедурным языком (в данном случае – с PL/SQL).
Прежде чем рассказать, каким образом СУБД блокирует записи, поясним некоторые операторы рассмотренной процедуры:
1 – CREATE PROCEDURE: создание хранимой процедуры с параметрами «номер1» (номер счета «откуда»), «номер2» (номер счета «куда»), «сумма» (сумма проводки).
2 – CURSOR: декларативный оператор, который определяет курсор с именем «курсор». Курсор имеет входные параметры («ном_счета1» и «ном_счета2»), а также описывает оператор SELECT для обновления (FOR UPDATE OF).
3 – декларативный оператор, который строит в оперативной памяти переменную «запись». Структура записи совпадает со структурой списка атрибутов, описанных в операторе SELECT (номер, остаток).
4 – BEGIN: начало описания тела процедуры.
5 – OPEN: открыть курсор с параметрами, получаемыми процедурой при вызове. При открытии курсора оператор SELECT после подстановки параметров выполняется ядром СУБД. Результаты поиска возвращаются обратно процедуре в виде множества записей курсора.
6 – LOOP: начать цикл по записям курсора.
7 – FETCH: скопировать поля (номер и остаток) текущей записи курсора в переменную «запись».
8 – EXIT: выйти из цикла, если все записи курсора обработаны.
9 – IF: обновить поле «остаток» переменной «запись».
10 – UPDATE: обновить текущую запись курсора.
11 – END LOOP: завершить тело цикла LOOP.
12 – CLOSE: закрыть курсор.
13 – COMMIT: завершить транзакцию и снять все блокировки.
14 – END: завершить описание тела процедуры.
На рис. 12.22 показано, как с помощью блокировок СУБД корректно выполняет обновления записей таблицы Счет при одновременном обращении рабочих станций к процедуре «проводка».
Первый процесс открывает курсор, и ядро СУБД выполняет описанный в этом курсоре оператор SELECT. Все найденные записи автоматически блокируются, так как при описании курсора было указано FOR UPDATE OF. При открытии курсора другим процессом выполняется поиск записей, но так как они блокированы, выполнение оператора SELECT откладывается и второй процесс переходит в состояние ожидания. После выполнения первым процессом оператора COMMIT обновленные записи становятся доступными другим клиентам (т.е. перемещаются из сегмента отката в таблицу Счет), записи 100 и 1001 разблокируются и выполняется оператор SELECT, связанный со вторым процессом. При этом поиск ведется уже по обновленной таблице Счет.
Ведение логических транзакций (ЛТ). Логическая транзакция – это совокупность изменений в БД, которые должны быть все зафиксированы в БД либо ни одного. Все СУБД, поддерживающие распределенную обработку, обеспечивают ведение транзакций. Различные СУБД обеспечивают работу с ЛТ примерно по одной схеме. Рассмотрим реализацию этой схемы на примере Oracle,
В PL/SQL для работы с транзакциями используют два оператора:
• COMMIT – это многофункциональная команда; она используется, чтобы
а) завершить предыдущую транзакцию и начать новую,
б) отменить все блокировки, установленные предыдущей транзакцией,
• ROLLBACK – позволяет программным путем отменить изменения, выполненные текущей транзакцией.
Рассмотрим схему ведения транзакций (рис. 12.23).
Если программа выполняет изменение записи (программа 1), то это изменение фиксируется на диске в сегменте отката. Здесь сохраняются записи до и после изменений. СУБД ведет в сегменте отката одну транзакцию для каждого активного процесса. Если другой процесс выполняет при этом поиск той же записи, то она читается не из сегмента отката, а из базы данных, т.е. до завершения транзакции этот процесс «не видит» никаких изменений, выполненных первым процессом.
По команде COMMIT СУБД выполняет следующие действия.

Рис. 12.22. Схема обработки двух запросов процедурой «проводка»

Рис. 12.23. Схема ведения транзакций
1. Транзакция из сегмента отката переписывается в журнал транзакций. Переписываются записи после изменения (см. 1 на рис. 12.23). Если до этого активным являлся журнал транзакций на диске 2 и он полностью заполнен (журнал имеет фиксированный размер на диске), то СУБД автоматически переключается на журнал транзакций, размещенный на диске 1. Теперь на нем будут сохраняться записи транзакций «после обновления». При этом журнал на диске 2 будет автоматически архивироваться сервером СУБД на устройство высокой емкости. После архивирования журнал освобождается для приема записей транзакций (после переполнения журнала на диске 1), и т.д.
2. Записи БД «после обновления» запоминаются в таблицах БД (через буфер сервера СУБД), т.е. СУБД показывает изменения другим процессам.

Рис. 12.24. Схема восстановления данных в БД после сбоя
Необходимо отметить, что транзакция процесса 1 удаляется из сегмента отката не сразу после выполнения команды COMMIT. Это связано с использованием в Oracle версий записей. Пусть оператор SELECT (см. процесс 2) пытается читать запись, обновленную процессом 1. Если дата (время) обновления записи (дата выполнения COMMIT) позже даты начала выполнения SELECT, то запись «до обновления» читается из сегмента отката (см. 3 на рис. 12.23). Это связано с тем, что по SELECT уже могли быть прочитаны из БД другие записи той же транзакции, но до того как они были обновлены в БД. Чтобы сохранить целостность поиска (т.е. чтобы не было рассогласования), используется старая версия записи («до обновления»). Если дата обновления записи раньше даты начала выполнения SELECT, то читается запись из БД (см. 4 на рис. 12.23). Транзакция удаляется в сегменте отката (т.е. освобождается память в этом сегменте) в том случае, если сервером СУБД выполнены все команды, которые были начаты до завершения этой транзакции.
Рассмотрим, как СУБД восстанавливает данные в БД после сбоев или отказов (рис. 12.24). В сервере СУБД через определенный интервал времени запускается процесс, перезаписывающий измененные блоки из буфера сервера СУБД на диск. После этого в журнале транзакций делается соответствующая отметка. Предположим, что система «зависла» в момент перезаписи транзакции из сегмента отката в журнал транзакции (см. «неполная транзакция» на рис. 12.24). Это один из самых неприятных случаев. После восстановления и перезагрузки системы СУБД автоматически пытается восстановить потерянные данные и целостность БД.
1. СУБД находит в журнале транзакций последнюю (с конца файла журнала) отметку о перезаписи данных на диск и выполняет докат базы данных (см. рис. 12.24), т.е. начиная с этой отметки и до конца файла, СУБД читает из журнала транзакций записи после изменений и записывает их в БД (через буфер сервера СУБД). При этом в БД помещаются записи после изменений и из неполной транзакции.
2. СУБД выполняет откат БД, чтобы устранить изменения, вызванные восстановлением неполной транзакции. Для этого СУБД читает с конца и до начала сегмента отката записи «до обновления» и записывает их в БД, устраняя тем самым нежелательные изменения.
Обработка тупиковых ситуаций. Рассмотрим следующий пример. Предположим, что процедура «проводка», рассмотренная выше при обсуждении вопроса о блокировках, теперь выглядит следующим образом:
CREATE PROCEDURE (номер1 IN NUMBER, номер2 IN NUMBER,
сумма IN NUMBER) IS
BEGIN
UPDATE счет SET остаток=остаток – сумма
WHERE номер=номер1;
UPDATE счет SET остаток=остаток + сумма
WHERE номер=номер2;
END;
Тупиковая ситуация возникает при одновременном обращении рабочих станций к процедуре «проводка». В данном случае СУБД выполнит откат транзакции процесса с наименьшим приоритетом и выдаст этому процессу сообщение об ошибке.
В прикладной программе должны быть закодированы операторы распознавания ошибок. В PL/SQL для этого целей используется блок EXCEPTION:
EXCEPTION
-- если транзакция была прервана СУБД
WHEN TRANSACTION_BACKED_OUT
обработка ошибки;
WHEN идентификатор другой ошибки
обработка ошибки;
....
END;

Рис. 12.25. Окно Module Definition
Пример генерации приложений с помощью CASE*Generator. Продолжим рассмотрение примеров, приведенных в параграфах 10.3, 11.2 и 12.1, где были разработаны диаграмма потоков данных, концептуальная и логическая схемы БД. Ниже приводится описание модуля «Результаты торгов».
1. Перед проектированием нового модуля приложения необходимо зарегистрировать его имя в хранилище CASE*Dictionary (Oracle). Для этого выберите пункт Design/Module Design/Module Definition утилиты CASE*Dictionary. На экране появится форма Module Definition (рис. 12.25).
Заполните поля этого окна для модуля «Результаты торгов», включая сокращенное и полное имя нового модуля, а также его тип, формат и сложность. Перед сохранением данных следует указать признак Y в поле Define Data Usage.
2. В результате на экране появится окно Define Data Usage (рис. 12.26), позволяющее определить более детальную информацию о поддерживаемых этим модулем данных.

Рис. 12.26. Окно Define Data Usage
С помощью окна, представленного на рис. 12.26, можно ввести используемые модулем имена таблиц и соответствующих столбцов. Можно даже задать, какие столбцы выводить на экран, какие операции выполнять над каждым столбцом, формат вывода столбца, метку каждого столбца и многое другое. Окно Define Data Usage показывает, как модуль Результаты торгов использует таблицу SEC_COU (Курс продажи) и ее столбцы. Также можно описать использование столбцов таблицы SEC_ISS (Эмиссия ЦБ).
3. Сохраните описание модуля Результаты торгов.
4. Теперь необходимо сгенерировать приложение. Запустите продукт CASE*Generator, введите имя пользователя и пароль и выберите пункт меню CASE*Generator/SQL*Forms.
5. Перед тем, как начать реализацию новой системы, необходимо задать некоторые параметры. Выберите пункт Use Preferences. Введите имя прикладной системы (SECURITES) и номер версии. Далее в меню в центре экрана выберите U. После этого можно отредактировать параметры пользователя. В нижней части экрана CASE*Generator показывает продукты, для которых можно генерировать приложения. Позиционируйте курсор на CASE*Generator for SQL*Forms, version 3. Затем с помощью клавиши [Next Block] перейдите ко второй странице окна Use Preferences.
6. Здесь следует задать только один параметр: TEMFRM, указывающий шаблон формы для генерации приложения в SQL*Forms. Для этого с помощью клавиши [Next Block] перейдите к блоку параметров окна. CASE*Generator выведет диалог, в котором следует ввести имя параметра TEMFRM и нажать клавишу [Next Field]. После этого CASE*Generator возвращается к окну, которое содержит некоторую дополнительную информацию. Здесь просто следует стереть поле Value и с помощью клавиши [Commit] сохранить изменения. Вернитесь в меню CASE*Generator /SQL*Forms.
7. Выберите пункт CASE*Generator/SQL*Forms/CASE*Generator Utilities/DDL Command Generator. При этом CASE*Generator запускает утилиту командной строки, которая запрашивает некоторую простую информацию, такую, как имя прикладной системы, номер ее версии и тип базы данных (наряду с Oracle можно генерировать приложения для DB2 фирмы IBM), а также тип генерируемого объекта (user означает генерацию таблиц, представлений, индексов, последовательностей и кластеров; dba – генерацию БД, табличных областей, сегментов отката, пользователей и полномочий) и имя выходного файла для DDL-сценария.
8. Если DDL-сценарий вас удовлетворяет, создайте в БД Oracle соответствующую схему, запустив DDL-сценарий из SQL*Plus или SQL*DBA.
9. Когда все необходимые структуры готовы, выберите пункт CASE*Generator/SQL*Forms/CASE*Generator for SQL*Forms-Generate. Далее введите имя модуля HAGGLE и нажмите клавишу [Commit]. CASE*Generator выводит окно с парой простых подсказок. В нем запрашивается количество строк, которые вы хотите выводить в каждом блоке формы. Для блока SEC_ISS (эмиссия ЦБ) введите 1 (это означает вывод по одной записи о наименовании ЦБ), для блока SEC_COU – 5.
10. После ввода всей необходимой информации CASE*Generator автоматически создает приложение. После этого система запрашивает, хотите ли вы выполнить приложение. Выберите YES и система выведет окно приложения (рис. 12.27).
Генерация описания логической схемы БД и триггеров с помощью пакета Erwin. Продолжим рассмотрение примеров, приведенных в параграфах 11.2 и 12.1. Покажем, как с помощью пакета Erwin можно реализовать ссылочную целостность.
1. Выберите какую-либо связь (например, имеет), нажмите правую клавишу мыши и выберите пункт Referential Integrity. На экране появляется окно Referential Integrity. Здесь могут быть заданы требования к обработке операций INSERT, UPDATE, DELETE для родительской и дочерней сущности связи. Erwin предоставляет следующие варианты обработки:
• отсутствие проверки (NONE);
• проверка допустимости операции (RESTRICT);
• каскадное выполнение операции DELETE или UPDATE (CASCADE);
• установка пустого или заданного значения по умолчанию (SET NULL или SET DEFAULT).

Рис. 12.27. Выходная форма программы «Результаты торгов»
В соответствии с выбранным вариантом Erwin автоматически создает триггеры на диалекте целевой СУБД (см. распечатку в конце этого пункта).
2. Проектировщик может разработать собственный триггер для какой-либо таблицы. Выберите таблицу SEC_COU (курс продажи), щелкните правой кнопкой мыши, выберите пункт ORACLE Trigger и в появившемся окне нажмите кнопку ORACLE7 Entity Trigger. На экране появляется окно Entity
Trigger Editor.
В поле ввода Trigger введите имя триггера и нажмите кнопку New. Затем с помощью блоков Trigger On, Fire, Scope выберите условия срабатывания триггера. Если необходимо определить список столбцов таблицы, при изменении которых будет срабатывать триггер, выберите требуемые атрибуты из списка Column(s) и нажмите кнопку Add®. В окне Template Code формируется шаблон т