Общие положения
При кодировании оцифрованные звуковые сигналы преобразуются к виду, основанному на использовании формализованной системы кодовых символов, что обеспечивает уменьшение суммарного количества бит данных для их представления. Основная цель кодирования звуковых сигналов – сжатие цифрового потока при одновременном удовлетворении требований к качеству последующего воспроизведения.
Методы сжатия учитывают статистическую и психоакустическую избыточность оцифрованных звуковых сигналов. Статистическая избыточность присутствует по причине свойств непосредственно двоичного звукового потока, а психоакустическая – по причине особенностей слухового восприятия.
Статистическая избыточность обусловлена наличием корреляционной связи между соседними отсчетами звукового сигнала при его дискретизации. Алгоритмы преобразования, основанные на учете этого факта, используются в методах сжатия ”без потерь” (lossless compression), когда исходный сигнал представляется в более компактной форме, но при восстановлении выходной сигнал равен исходному. Такой подход позволяет в итоге сократить размер цифрового потока на 15-25%, что часто оказывается недостаточным для широкого практического применения.
Наиболее производительными являются методы, учитывающие свойства слухового восприятия звука человеком. Такие методы допускают потерю некоторой части аудио информации и, следовательно, это всегда кодирование с потерями качества. Восстановленный сигнал при воспроизведении звучит похожим на исходный оригинальный, но технически сигналы существенно различаются. Соответствующие методы относятся к типу под названием ”сжатие с потерями” (lossy compression). При кодировании учитываются требования к качеству восстановленного аудио сигнала, которые зависят от конкретных целей и области использования (например, в телефонии, интернете, в портативных или бытовых устройствах). В общем случае, при lossy-сжатии цифровой звуковой сигнал упрощается, который затем сжимается lossless-методом.
Для оценки качества сжатия цифровых звуковых данных используются отрывки звуковых сигналов из компакт-диска EBU-SQAM, Cat.№422204-2, созданный группой MPEG специально для этой цели, а также руководствуются рекомендацией ITU-R “Method for objective Measurements of Perceived Audio Quality” (Doc. 10-14/19-E, 19/03/1998).
Основы психоакустики
Основные задачи психоакустики – изучить механизм работы слуховой системы при распознавании звуковых образов, установить соответствия между физическими стимулами и слуховыми ощущениями, определить наиболее значимые параметры звукового сигнала для передачи смысловой и эмоциональной информации.
9.2.1. Структура слуховой системы и ее работа
Звуковая информация распознается с помощью периферической слуховой системы и высших отделов мозга. Структура периферической слуховой системы состоит из внешнего, среднего и внутреннего уха (рис.1).


Рис.1 Периферическая слуховая система
Внешнее ухо состоит из ушной раковины и слухового канала, заканчивающегося мембраной, называемой барабанной перепонкой. Внешние уши и голова - это компоненты внешней акустической антенны, которая соединяет барабанную перепонку с внешним звуковым полем. Основные функции внешних ушей - пространственная локализация звукового источника и усиление звуковой энергии, особенно в области средних и высоких частот. Слуховой канал представляет собой изогнутую цилиндрическую трубку длиной 22,5мм, которая имеет резонансную частоту, равную примерно 2,6кГц. Поэтому в этой области частот звук существенно усиливается, а в диапазоне частот от 2кГц до 4кГц чувствительность слуха максимальна.
Барабанная перепонка представляет собой пленку толщиной 74мкм, имеющую вид конуса, обращенного острием в сторону среднего уха. На низких частотах она движется как поршень, а на более высоких частотах на ней образуется система узловых линий.
Среднее ухо - заполненная воздухом полость, соединенная с носоглоткой евстахиевой трубой для выравнивания атмосферного давления. При изменении атмосферного давления воздух может входить или выходить из среднего уха. Поэтому барабанная перепонка не реагирует на медленные изменения давления, такие как спуск-подъем в лифте и т.п. В среднем ухе находятся три слуховые косточки: молоточек, наковальня и стремечко. Молоточек прикреплен одним концом к барабанной перепонке, а вторым соприкасается с наковальней, которая при помощи связки соединена со стремечком. Основание стремечка соединено с овальным окном внутреннего уха.
Среднее ухо выполняет функции согласования импеданса воздушной среды с жидкой средой улитки внутреннего уха, защиты от громких звуков, усиления по принципу действия рычагового механизма (звуковое давление, передаваемое во внутреннее ухо, усиливается почти на 38дБ).
Внутреннее ухо находится в лабиринте каналов в височной кости и содержит орган равновесия (вестибулярный аппарат) и улитку.
Улитка (cochlea) играет основную роль в слуховом восприятии. Улитка представляет собой трубку переменного сечения, свернутую три раза подобно спирали. В развернутом состоянии улитка имеет длину 3,5см. По всей длине улитка разделена двумя мембранами на три полости, называемые лестница преддверия, срединная полость и барабанная лестница (рис.2). Все полости заполнены жидкостью. Верхняя и нижняя полости соединены через отверстие (геликотрему) у вершины улитки. В верхней полости находится овальное окно, через которое стремечко передает колебания во внутреннее ухо, а в нижней полости находится круглое окно, выходящее обратно в среднее ухо. Сверху срединная полость закрыта мембраной Рейсснера, а снизу - базилярной мембраной. Базилярная мембрана состоит из нескольких тысяч поперечных волокон. Базилярная мембрана имеет длину 32мм, а ширина равна 0,05мм - у стремечка (этот конец узкий, легкий и жесткий) и 0,5мм - у геликотремы (этот конец толще и мягче). На внутренней стороне базилярной мембраны находится орган Корти, а в нем - специализированные слуховые рецепторы, т.е. волосковые клетки (более 20 тысяч). Волокна слухового нерва контактируют с волосковыми клетками. Внутри улитки находятся до 4000 нервных окончаний.

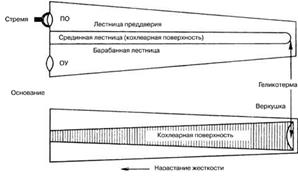
Рис.2 Улитка и ее схематическое изображение
(по – окно преддверия, оу – окно улитки)
Слуховой нерв представляет собой перекрученный ствол, сердцевина которого состоит из волокон, отходящих от верхушки улитки, а наружные слои - от нижних ее участков.
Звуковые волны проходят звуковой канал и возбуждают колебания барабанной перепонки. Эти колебания через систему косточек среднего уха передаются овальному окну. Мембрана овального окна толкает жидкость в верхнем отделе улитки (лестнице преддверия). Импульс давления заставляет жидкость переливаться из лестницы преддверия в барабанную лестницу через геликотерму. Движение жидкости в виде бегущей волны вызывает колебания базилярной мембраны. Преобразование механических колебаний мембраны в дискретные электрические импульсы нервных волокон происходят в органе Корти. При вибрации базилярной мембраны реснички на волосковых клетках изгибаются, что вызывает поток нервных импульсов, передающих в мозг информацию о поступившем звуковом сигнале.
Таким образом, периферическую часть можно рассматривать как систему, состоящую из следующих подсистем:
· акустическая антенна, принимающая, локализующая и усиливающая звук;
· микрофон (барабанная перепонка и среднее ухо);
· частотный и временной анализатор (улитка);
· аналого-цифровой преобразователь, преобразующий аналоговый сигнал в нервные импульсы - электрические разряды (улитка).
Высшие отделы слуховой системы (включая слуховые зоны коры), можно рассматривать как звуковой сопроцессор, который декодирует полезные звуковые сигналы на фоне шумов и определяет их информационную ценность.
9.2.2. Психоакустические свойства
Чувствительность. Чувствительность слуховой системы зависит от частоты, громкости, длительности звука и окружающих условий. На рис.3 изображено семейство кривых, называемых изофонами, которые представляют собой графики стандартизированных зависимостей уровня звукового давления от частоты при заданном уровне громкости (международный стандарт ISO 226:2003 “Акустика - Нормальные кривые равной громкости”).
Изофоны называются кривыми равной громкости и были получены Флетчером и Мэнсоном в результате обработки данных большого числа экспериментов, проведенных среди нескольких сотен посетителей Всемирной выставки 1931 года в Нью-Йорке. Например, чтобы звук с частотой 100Гц казался таким же громким, как звук с частотой 1000 Гц с уровнем 40дБ, его уровень должен быть около 50дБ. Равногромкий звук частоты 50Гц должен иметь уровень 65дБ и т.п. При увеличении уровня эталонного звука с частотой 1кГц до 60дБ формируется кривая равной громкости, соответствующая уровню 60фон.
Каждая изофона показывает уровень равной громкости полезного звукового сигнала с начальной точкой отсчета на частоте 1кГц в присутствии некоторого шума внешнего фона. Например, линия «10 фон» показывает уровни громкости полезного сигнала на разных частотах, воспринимаемых слушателем как равные по громкости сигналу с частотой 1кГц и уровнем 10дБ. Таким образом, с изменением уровня шума (фона) изменяется порог чувствительности (слышимости). Частотные составляющие с амплитудой ниже порога слышимости, т.е. находящиеся под кривой, незаметны на слух.
Порог слышимости в тишине показан на рисунке пунктирной кривой. Например, порог слышимости сигнала на частоте около 3кГц составляет чуть менее 0дБ, а на частоте 200Гц – около 15дБ. В свою очередь, болевой порог мало зависит от частоты и колеблется в пределах 120…140дБ.
С помощью изофон можно определить уровень громкости гармонического колебания какой-либо частоты по известному уровню создаваемого им звукового давления. Уровень громкости звука - относительная величина, выражается в фонах и численно равна уровню звукового давления (в децибелах), создаваемого синусоидальным колебанием частотой 1кГц такой же громкости, как и измеряемый звук, имеющий другую частоту в пределах звукового диапазона.

| Например, если синусоидальный сигнал частотой 100Гц создаёт звуковое давление с уровнем 60дБ, то звук имеет уровень громкости 50 фон. Изофона "0 фон", обозначенная пунктиром, указывает на порог слышимости звуков разной частоты для нормального слуха. |
| Рис.3 График кривых равных громкостей |
При малых уровнях звукового давления оценка уровня громкости в значительной степени зависит от частоты, т.к. слух менее чувствителен к низким и высоким частотам, и требуется создать большие уровни звукового давления, чтобы звук стал звучать равногромко с эталонным звуком 1кГц. При больших уровнях изофоны выравниваются, подъем на низких частотах становится менее крутым. Таким образом, при больших уровнях низкие, средние и высокие звуки оцениваются по уровню громкости более равномерно.
Влияние интенсивности. При повышении интенсивности звука громкие низкие звуки воспринимаются еще ниже, а высокие звуки - несколько выше. Для средних частот 1-2кГц изменение интенсивности незаметно.
И нерционность. Восприятие высоты зависит от длительности звука. Кратковременные звуковые волны не способны заставить мембрану резонировать и воспринимаются на слух как сухой щелчок. Минимальное время, требуемое для распознавания высоты, зависит от длины волны. Чем меньше длина звуковой волны, т.е. выше частота звука и тем быстрее устанавливаются колебания базилярной мембраны.
Для низких частот (до 500Гц) для распознания высоты требуется примерно 60мс, для частот от 1кГц до 2кГц - 15мс. На распознавание тембра требуется около 200мс. Для распознавания характеристик речи требуется 20-30мс (частотный спектр речи - от 500Гц до 2кГц, низкие частоты - басы и гласные, а высокие частоты – согласные).
Восприятие громкости улучшается в соответствии с длительностью сигнала почти линейно.
Частотная разрешающая способность. Слуховая система различает два звука по высоте с пиками возбуждения на базилярной мембране, смещенными на 52мкм (рис.4).

| Частоты двух различимых звуков могут отличаться всего на 0,2%.Такая разрешающая способность слуха позволила установить, что ниже частоты 500Гц можно выделить примерно 140 градаций высоты, в диапазоне от 500Гц до 16кГц - примерно 480 градаций (всего 620 градаций). |
| Рис.4 Частотная разрешающая способность слуха |
Нейрон может возбуждаться не чаще чем 500 раз в секунду. На частотах до 500Гц колебания непосредственно переходят в нервные импульсы. На частотах до 1,5кГц к одному нервному окончанию подключаются одновременно до 3 нейронов. Нейроны в данном случае возбуждаются последовательно, один за другим и, соответственно, помогают улучшить частотное разрешение.
Бинауральный эффект. Это способность слуховой системы различать направление прихода звуковых сигналов. В полосе частот до 1,5кГц для определения направления звука достаточно разницы в 1мс во времени прихода сигнала в разные уши. На частотах более 1,5кГц регистрируется только амплитуда сигнала и, следовательно, источником информации о местоположении служит разница амплитуд сигнала для левого и правого уха (источник звука находится со стороны того уха, в котором он слышен лучше).
Эффект маскирования. Маскирование, т.е. неслышимость звуков определенных частот, возникает при доминировании одних частот над другими. Различают частотное и временное маскирование. В основе обоих вариантов находится механизм восприятия звука слуховой системой. Мощный по амплитуде сигнал вызывает сильные возмущения базилярной мембраны на некотором ее отрезке. Близкий по частоте, но более слабый по амплитуде сигнал с другой частотой не способен повлиять на колебания мембраны, и поэтому остается "незамеченным" нервными окончаниями и мозгом.
Частотное маскирование возникает при одновременном присутствии маскирующего и маскируемого сигналов (частот). На рис.5а показано влияние маскирующего сигнала с частотой 1кГц различной громкости (от 20 до 100дБ) на слышимость маскируемогосигнала различной частоты – от 1,1кГц до 4.1кГц (сплошная линия показывает границу слышимости при наличии маскирования, а штриховая – без маскирования).

| 
|
| а) Маскирование звуком 1кГц | б) Маскирование полосой 90Гц с центральной частотой 410Гц |
Рис.5 Частотное маскирование сигналом различной интенсивности
На рис.6 приведены результаты экспериментов по маскировке сигналов при наличии маскирующего синусоидального сигнала частоты 1.2кГц с уровнем звукового давления 80дБ. Область, в которой контрольный звук не слышен, на графике обозначена «только помеха». В этой области происходит полная маскировка и слышен только звук с частотой 1.2кГц. Вне этой области контрольный сигнал прослушивается как отдельный звук или в виде биений.

Рис.6 Экспериментальные результаты маскирования
Ширина маскируемой области зависит не только от интенсивности, но и от частоты сигнала. Ширина области маскирования равна примерно 100Гц для низких частот и более 4кГц – для высоких частот. На рис.7 показаны зависимости маскирования для различных частот маскирующего сигнала одинаковой интенсивности 60дБ.

Рис.7 Маскирование различными частотами одинаковой интенсивности
Следовательно, можно считать, что периферическая слуховая система содержит банк полосовых фильтров ("слуховых фильтров") с перекрывающимися полосами. С шириной слуховых фильтров связано важное понятие " критических полос ", внутри которых звуковая информация воспринимается слухом равномерно, а при выходе за их пределы происходит скачкообразное изменение слуховых ощущений. В итоге, критические полосы образуют некоторые меры восприятия частот.
Весь частотный диапазон слухового восприятия может быть разделен на 27 критических полос:
| Полоса | Частоты | Полоса | Частоты | Полоса | Частоты | Полоса | Частоты | |||
| 0-50 | 560-660 | 1735-1970 | 5440-6375 | |||||||
| 50-95 | 660-800 | 1970-2340 | 6375-7690 | |||||||
| 95-140 | 800-940 | 2340-2720 | 7690-9375 | |||||||
| 140-235 | 940-1125 | 2720-3280 | 9375-11625 | |||||||
| 235-330 | 1125-1265 | 3280-3840 | 11625-15375 | |||||||
| 330-420 | 1265-1500 | 3840-4690 | 15375-20250 | |||||||
| 420-560 | 1500-1735 | 4690-5440 |
По причине инерционности слуха некоторая частотная составляющая может маскировать другую близкую частотную составляющую даже тогда, когда они появляются в спектре не одновременно, а с некоторой задержкой во времени. Такой эффект называется временн о ймаскировкой. Присутствие во времени маскирующего звука раньше маскируемого приводит к эффекту пост-маскировки. В случае же, когда маскирующий звук появляется позже маскируемого, эффект называет пре-маскировкой.
На рис.8 показаны значения времени, необходимого для того, чтобы услышать маскируемый сигнал различного уровня после исчезновения или перед появлением маскирующего сигнала различной частоты и интенсивности. Например, звук уровня 20дБ будет различим только через 14мс после исчезновения маскирующего сигнала 40дБ частоты 500Гц. Пост-маскировка может продолжаться до 250мс. В свою очередь, эффективная длительность пре-маскировки составляет примерно 20мс.

Рис.8 Эффект временной маскировки
Теория маскирования верна в случае рассмотрения стационарных сигналов, а для сигналов с резко меняющимися параметрами она неприменима. Разновидностью таких сигналов являются речевые сигналы, которые предполагают резкие увеличения амплитуды сигнала с быстрым затуханием.
9.3 Сжатие звука “с потерями данных”
Методика сжатия “с потерями” основана на учете психоакустических особенностей человеческого слуха, в первую очередь частотного маскирования, указывающего на избыточность данных, полученных в результате оцифровки звукового сигнала.
На рис.9 показан пример обработки звука согласно психоакустической модели.

Рис.9 Пример спектра и его полосной обработки
Спектр звука (SPL) представлен вертикальными линиями с точками, абсолютный (L0) и относительный (LТ) пороги слышимости показаны соответствующими кривыми, а допустимый шум квантования в частотных полосах - заштрихованными фрагментами.
В примере полезным сигналом является тональный звук с основной частотой 200Гц и рядом сопутствующих обертонов. Штриховая линия показывает абсолютный порог слышимости звука в тишине (L0). Относительный порог слышимости (LТ) получается из учета уровней спектральных частей (основного тона и обертонов) сигнала, попадающих в каждую отдельную полосу частот. Все спектральные компоненты сигнала, оказавшиеся в одной полосе, обрабатываются совместно с одинаковым шагом квантования. В разных полосах шаг квантования может быть различен, что предполагает различный уровень шума квантования.
Согласно эффекту частотного маскирования не все одновременно существующие частоты сигнала могут быть восприняты слухом, несмотря на расположение спектральных компонент выше абсолютного порога слышимости. Частоты сигнала и шумы, расположенные ниже относительного порога слышимости, не воспринимаются на слух и поэтому при кодировании их допустимо удалить.
Таким образом, для сокращения объема цифровой информации с учетом психоакустической модели необходимо решить следующие задачи:
1. Расчет спектральных компонентов.
2. Указание абсолютного порога слышимости.
3. Разделение сигнала на частотные полосы.
4. Определение уровня интенсивности сигнала в каждой частотной полосе.
5. Вычисление уровня маскирования для каждой полосы.
6. Выделение тональных и маскируемых частей спектра.
7. Удаление спектральных компонент.
8. Расчет отношения сигнал/шум для каждой частотной полосы.
На рис.10 показана структура lossy-кодировщика.

Рис.10 Структурная схема lossy-кодировщика
В блоке временной и частотной сегментации исходный сигнал разделяется на субполосные составляющие и сегментируется по времени. Длина кодируемой выборки зависит от временной формы сигнала. При отсутствии резких выбросов по амплитуде используется “длинная” выборка. При наличии резких изменений амплитуды сигнала длина кодируемой выборки уменьшается. Решение об изменении длины выборки принимает блок психоакустического анализа на основе значения энтропии сигнала.
После сегментации субполосные данные нормируются, квантуются и кодируются. Как правило, используется энтропийное кодирование, при котором учитываются как свойства слухового восприятия, так и статистические характеристики звукового сигнала. Основную задачу при этом решают процедуры устранения психоакустической избыточности.
Особенности слухового восприятия учитываются в блоке психоакустического анализа, в котором для каждого субполосного сигнала рассчитывается максимально допустимый уровень погрешности (шума) квантования.
Блок динамического распределения бит в соответствии с требованиями психоакустической модели выделяет для каждой субполосы кодирования минимально возможное количество бит, при котором уровень погрешности квантования не превышает порога слышимости, рассчитанного психоакустической моделью.
На основе результатов исследований психоакустики первыми были разработаны следующие методы цифрового представления сигналов:
- АSРЕС - Audio Spectral Perceptual Entropies Coding (фирма АТ&Т)
- МUSICAM - Маking Pattern Universal Subband Integrated Coding And Multiplexing (Институт техники радиовещания в Мюнхене, фирма Филипс и ССЕТТ).
Эти методы получили дальнейшее развитие и практическую реализацию в lossy-кодекахMPEG (“codec” – “CODer/DEcoder” - программный или аппаратный блок, предназначенный для кодирования и декодирования данных). В общем случае, алгоритм работы кодеков предполагает расчет психоакустической модели, разделение сигнала на частотные полосы и квантование сигнала.
Семейство стандартов MPEG
Методы кодирования MPEG разработаны коллективом, объединяющим несколько сотен специалистов, “Moving Picture Coding Experts Group” - "группа специалистов по кодированию подвижных изображений" (создана в 1988г.).
Метод MPEG-1 принят в качестве стандарта ISO/ICE 11172-3 (International Standards Organization). Рекомендуется для кодирования одно- и двухканальных сигналов. Частота дискретизации сигналов равна 32, 44.1, 48кГц. Метод MPEG-2 ISO/ICE 13818-3 – дополнительно к MPEG-1 использует частоты дискретизации 16, 22.05 и 24кГц, обеспечивает качественное кодирование в широком наборе стерео форматов, совместим с MPEG-1.
Метод MPEG-2 ISO/ICE 13818-7 AAC – высококачественное кодирование звуковых сигналов в полной полосе звуковых частот (до 20кГц).
Метод MPEG-4 ISO/ICE 14496-3 – качественное кодирование на основе современных математических решений.
9.4.1 Кодирование по методу MPEG-1
Аудио часть MPEG-1 (помечается цифрой 3 после дефиса в шифре стандарта) предписывает три методики обработки, согласно которым различают три уровня реализации: Layer 1, Layer 2 и Layer 3 ("MP3"). Структура кодирования одинакова для всех уровней MPEG-1, но уровни различаются по целевому использованию и использованным алгоритмам. Для каждого уровня определен свой формат выходного потока данных и, соответственно, свой алгоритм декодирования.
Например, в Layer 3 входной звуковой сигнал (PCM, частота дискретизации 48кГц, 16бит/отсчет, v=768кбит/с) разделяется на временные фрагменты – кадры (фреймы), содержащие 1152 отсчета ИКМ сигнала (длительность выборки равна 24мс). Каждый фрейм блоком цифровых полифазных квадратурных зеркальных фильтров разделяется на 2 блока по 576 отсчетов в каждом, а затем - на 32 субполосные составляющие. В первую полосу попадают 18 отсчетов отсчетов с номерами 0, 32, 64, 96, 128 и т.д. с шагом, равным 32. Во вторую полосу – 1, 33, 65, 97, 129, … В третью полосу - 2, 34, 66, 98, 130, … В тридцать вторую полосу - 31, 63, 95, 127, 159, … Уменьшение количества отсчетов означает соответствующее уменьшение частоты дискретизации сигнала в каждой субполосе.
В Layer-3 по отношению к отсчетам каждой субполосы выполняется МДКП (MDCT – Modified Discrete Cosine Transform). Таким образом, по окончании частотной сегментации в каждом из 2 блоков имеется 32 группы коэффициентов МДКП по 18 коэффициентов МДКП в каждой (общее количество коэффициентов на выходе частотных фильтров в Layer-3 равно 2х576=2х18х32).
При отсутствии всплесков в фрагменте сигнала, соответствующем выборке, выполняется единое МДКП для отсчетов субполосы ("длинное" преобразование). При наличии всплесков субполоса разбивается на три подгруппы каждая ("короткое" преобразование). Далее три подблока объединяются в гранулу, содержащую 576 коэффициентов преобразования. Решение о назначении длины преобразования принимает психоакустическая модель, вычисляя для каждого фрейма величину психоакустической энтропии.
Коэффициенты МДКП после банка фильтров масштабируются (нормируются), квантуются и кодируются.
Преобразование учитывает параметры психоакустической модели. После определения уровней сигнала в частотных субполосах рассчитывается относительный порог слышимости. Сигнал анализируется на соответствие тональных и шумовых частей. Затем вычисляется отношение SNR, при котором шум маскируется полезным сигналом. На основе значений SNR и уровней сигнала для каждой субполосы устанавливается шаг квантования (выбирается из таблицы) и необходимое для кодирования число бит исходя из требований к скорости передачи сигнала и маскировки шумов в каждой субполосе. Кодируются масштабные коэффициенты и распределение разрядов. Цифровые данные сжимаются. При форматировании из сжатых данных и сигналов управления компонуется звуковой поток в формате МРEG.
Структура кодера МРEG-1 Layer-3 представлена на рис.11.

Рис.11 Структура кодера МРEG-1 Layer-3
Данные в MPEG кодируются поблочно, т.е. выходной поток имеет кадровую структуру. Фреймы могут быть закодированы с битрейтом, входящем в таблицу стандартных битрейтов от 32 до 320кбит/с Layer-3 на один канал (кодирование на произвольных промежуточных битрейтах стандартом не предусмотрено, но возможно). Популярным является битрейт 128кбит/с, при котором одна минута звучания занимает на носителе один мегабайт.
Применяется сжатие данных с постоянным (CBR) и переменным (VBR) битрейтом. CBR (Constant Bitrate - постоянный битрейт) - все фреймы кодируются с одинаковым результирующим битрейтом. VBR (Variable Bitrate - переменный битрейт) - каждый фрейм кодируется со своим битрейтом. Оптимальный для кодирования битрейт назначается кодером на основе анализа сложности сигнала в каждом фрейме.
Существует также режим ABR (Average bitrate – средний битрейт), при котором аудиопоток кодируется с переменным битрейтом, но с сохранением неизменности усредненного значения.
Каждый аудиофрейм МРEG-1 Layer-3 имеет заголовок (служебную информацию), блок дополнительных данных и блок цифровых аудиоданных, состоящий из двух гранул. Каждая гранула содержит информацию о 576 коэффициентах МДКП (рис.12).

Рис.12 Структура цифрового звукового потока по стандарту MPEG-1 Layer-3
Заголовок (32 бита) содержит синхрослово (12 бит равных 1) и информацию о состоянии, относящуюся к структуре данных фрейма (20 бит):
- бит идентификации – ID, равный 1, если поток аудиоданных полностью соответствует стандарту ISO/МРЕG 11172-3, и 0 в противном случае;
- код уровня (2 бита), идентифицирующий уровень кодирования - L1, L2, L3;
- бит защиты, равный 1, если не применяется помехоустойчивое кодирование и 0 в противном случае;
- значение скорости цифрового потока (4 бита);
- частоту дискретизации - 44,1 или 48, либо 32 кГц (2 бита);
- "паддинг" бит, равный 1, если частота дискретизации 44,1 кГц и 0 в противном случае;
- бит для использования в специальных целях, например передачи дополнительной информации;
- код режима передачи (2 бита): стерео, объединенное стерео, два независимых канала, один канал;
- код режима расширения (2 бита) при передаче в режиме объединенное стерео;
- бит права копирования, равный 0, если копирование запрещено;
- бит "оригинал/копия", равный 1, если передается оригинал;
- код предискажения (2 бита).
Количество бит, выделяемое для кодирования каждого вида служебной и дополнительной информации, представлено отдельными таблицами (табл. А.7 и А.8 стандарта ISO/МРЕG 11172-3). Например, следующие 16 бит после преамбулы используются для помехоустойчивого кодирования.
Декодер сигналов (рис.13) разделяет закодированный поток на управляющую и информационную части. Затем в каждой полосе сигналы преобразуются в исходную форму. В инверсном блоке фильтров различные спектральные части звукового сигнала вновь объединяются в первоначальный сигнал. Результатом этого является цифровой поток аудиоданных на выходе декодера, который уже подготовлен для цифро-аналогового преобразования.

Рис.13 Структурная схема декодера MPEG-1
Стандарт MPEG-1 предусматривает многоканальную передачу звука. В самом простом случае ощущение мнимого источника звука между физическими создается двумя источниками звука. Причем мнимый источник звука можно "расположить" в любой точке на линии, соединяющей два физических источника. Для этого одна аудио запись воспроизводится через оба физических источника с некоторой временн о й задержкой в одном из них и соответствующей разницей в громкости. Такую двухканальную запись называют стереофонической.
Различают следующие методы кодирования стерео аудиоинформации в стандарте MPEG-1:
Dual Channel. Предполагает кодирование стерео каналов, как абсолютно независимых. В этом режиме аудиоданные кодируются в каждом канале независимо друг от друга. Этот режим предназначен для кодирования двух параллельных, но различных каналов (например, речь на английском и немецком языках), а не стерео.
Stereo. В режиме Stereo сигнал кодируется с учетом корреляции значений отсчетов в обоих каналах.
MS Stereo. Кодируются суммарная (постоянная) составляющая (mid-канал) и разностная (side-канал) обоих каналов:  ,
,  . MS Stereo не вносит в сигнал дополнительных погрешностей, поскольку при изменении стерео сигнала из формата <левый> + <правый> в mid и side выполняются несложные и обратимые математические вычисления.
. MS Stereo не вносит в сигнал дополнительных погрешностей, поскольку при изменении стерео сигнала из формата <левый> + <правый> в mid и side выполняются несложные и обратимые математические вычисления.
Intensity Stereo. В этом режиме весь кодируемый сигнал разбивается на полосы и фактическому кодированию подвергается только нижний диапазон частот side-канала, а в верхнем частотном диапазоне начиная с определенной частоты происходит не кодирование, а лишь регистрация корреляции значений сигнала в каждой полосе. Стерео сигнал в нижнем частотном диапазоне кодируется в режиме MS-Stereo или Stereo. Высокочастотная составляющая восстанавливается исходя из значений масштабных коэффициентов.
В структуре цифрового кодированного потока варианты стерео отражаются как последовательная передача данных для каждого из каналов.
Для качественного обеспечения реалистичного пространственного звучания обычной стереофонической записи оказывается не достаточно. Основная причина этого в том, что стерео сигнал, приходящий к слушателю от двух физических источников звука, определяет расположение мнимых источников лишь в той плоскости, в которой расположены реальные физические источники звука. Для воссоздания реалистичного, действительно объемного звучания прибегают к применению принципиально других подходов, основанных на психоакустической модели и физических особенностях передачи звуковых сигналов в пространстве.
9.4.2. Кодирование звука по методу MPEG-2 ISO/IEC 13818-3
Стандарт MPEG-2 (13818-3) является развитием стандарта MPEG-1. В дополнение к двум аудиоканалам R и L (правый и левый фронтальные) сигнал кодируется также по каналам C, LS, RS (центральный фронтальный (C-center), левый (LS-leftsurround) и правый (RS-rightsurround) пространственные (тыловые)). К ним может добавляться канал усиления сверхнизкочастотных частот (LFE-subwoofer) и до 7 многоязыковых каналов или каналов комментариев.
Пространственные сигналы LS и RS имеют полосу частот 100...7000Гц. Полоса частот сигнала С ограничивается значением 9кГц, сигналы L и R имеют полную полосу частот от 20Гц до 20кГц, а сигнал LFE – 15…125Гц.
Частота дискретизации при передаче основных каналов L и R равна 32, 44.1 или 48кГц, C, LS, RS - 16кГц, 22.05 кГц или 24 кГц, LFE - fд/96, где fд - частоте дискретизации по основным каналам (динамический диапазон LFE - более 20 бит/отсчет).
Сигналы от источников звука до кодирования комбинируются в линейную матрицу. Эти комбинированные сигналы и каналы их кодирования обозначаются Т1, Т2, Т3, Т4, Т5, причем Т1 и Т2 – это базовые каналы MPEG-1, а Т3, Т4 и Т5 формируют данные многоканальной аудиосистемы.

Рис.14 Структурная схема кодера MPEG-2
При кодировке исходный пятиканальный сигнал преобразуется по следующим формулам:
 ,
,  ,
,
 ,
,  ,
,  ,
,
где  - коэффициенты матрицирования, значения которых зависят от режима работы системы передачи:
- коэффициенты матрицирования, значения которых зависят от режима работы системы передачи:
- Режим 0:  ,
,  ,
,  .
.
- Режим 1:  ,
,  ,
,  .
.
- Режим 2:  ,
,  , .
, .
- Режим 3:  .
.
В частности, режим 2 соответствует передаче сигналов системы Dolby-Surround. В этом режиме перед кодированием формируется сигнал окружения Surround  , который в противофазе добавляется к L и R.
, который в противофазе добавляется к L и R.
После матрицирован