Имеется некоторое тематическое дерево, заполняемое пользователями.Базу редактируют администраторы. Администраторы БД сами образуют некое дерево:

каждая ветка дерева администраторов должна будем иметь свой доступ к ветке БД движения.
Сейчас БД движения выглядит не очень структурированно: существуют три группы базы данных: БД. и две медиатеки - УНП и МП.

В поле «внутренние» (второй стоблец справа) есть три группы по сбору и хранению инфы. в каждой просто свой хозяин, который с другими группами мало пересекается. И всё это связано с тем, что:
1. сам вк никак не приспособлен к серьезным накоплениям инфы (максимум 4-5 уровней вложенности и иеррхического ветвления инфы).
2. продумана стратегия получения статей, да. Продумана политическая стратегия, под которую статьи подбираются. но общей теории мэносферы нет. Это как начинать социализм и марксизм без теории Маркса.
3. В итоге статьи делаются под политические цели (идиология). Отражают основные направления работы МП. Но направлений работы гораздо меньше, чем направлений развития реальности. Потому ожидаемо статьи не отражают реального сущестования вещей- не отражают реальность в полном её обьеме. В итоге, когда в группу поступает какая то инфа, которая не подходит под "политические" цели МП, её не знают, куда сувать и отправляют в такие вот группы. Такой инфы должно быть много БОЛЬШЕ, чем структурированных постов, потому что мир вокруг много разнобразнее наших целей. но пока что мы не выходим в окружающий мир его щупать поглубже, а находися около идеологического скелета. так и надо. Но надо готовить дорожки в лес, вглубь неизведанного. что я и делаю ща.
4. Политическая часть движения и научная часть движения реагируют по типу "политик заказал ученому идеологию." Тогда как на самом деле, например, открытие того, что земля вращается вокруг солнца, а люди произошли от обезьян, изменило идеологию. А не наоборот, идеология изменила науку.
Чувствуется противобороство людей науки и людей идеологии?Потому между реальностью и идеологией лежит пустое место. Его видно на картинке, это третий стоблец слева или второй справа.
Его пытались заткнуть группами для временного сбора инфы. Эти три группы тянут инфу с уже существующих МП групп, и совсем немного- снаружи тянут инфу. Тогда как они призваны тянуть инфу В ОСНОВНОМ снаружи. Чётких правил, что куда, в какие группы постить, на мой взгляд, нет
Теперь картинка показывает возможные направления потоков информации между существующей структурой взводов и рот МП и созданными базами данных.:
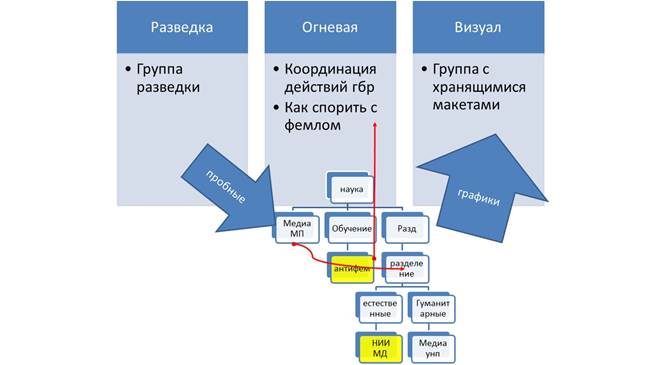
формируется группа "разведка МП". Туда разведка постит свои материалы. Оттуда тот, кто является участником и разведки, и УНП, постит в Унп
то, что материал находиться на одной из веток не значит, что ссылка на него не может сущестовать в другой ветке. Ведь один и тот же пример может быть использован в обьяснении разных закономерностей. Так, то, что бабы красят губы в красный цвет. Это, как минимум две ветки:
Ветка этология
ветка промышленная революция.
Чем ветки отличаются от Тэгов, я хз. Наверное, это одно и тоже.
Пользователи низших ступеней могут предлагать отдельные ветки этого дерева, администратор будет утверждать их в общее пользование или не утверждать.
С одной стороны, нужно достигнуть максимальной демократизации, что бы не было как на маскулисте или на МД вк группах, с другой стороны, нужно избежать мусора. Потому встает вопрос, а что будет, если пользователь не может определить место дерева, куда будет засунут данный материал? Ведь если он не увидит, что его материал опубликован, зачем ему тогда вообще что то делать?
Сразу после добавления материала он должен его увидеть на сайте. Это будет отличать этот сайт от других- демократичность. Он предлагает новую ветку, или даже ствол. Тогда создается фантомный ствол, ветка, которая будет называться «непроверенная ветка»
Это решается так:
1) материал будет материалом, если в нем есть пруфы и есть связь этого материала с двумя другими материалами темы. Связь может быть в виде алгоритма (это влияет на то), или, если в материале присутствуют цифры, она может быть в виде примерного соотношения.
2) материал должен иметь определенное место в древе базы или иметь не менее 4х тегов.
Кроме демократизации, есть фантастическая цель функционирования базы – база сама «генерирует» черновики статей и модели общества.
Есть две галочки для материалов, колонок и строк базы данных:
«не проверено» или песочная база (ПБ) и «проверено» - обкатанная база (ОБ).
Что такое материал?
Это кусок текста. Текст может быть найден на любом сайте, электронном источнике, книге, статье. Плагин добавления материала в базу ПЗБ должен уметь автоматически выискивать инфу о материале, что бы потом было понятно, откуда он взялся. Материал должен описывать один какой-то вопрос. Со временем должны быть опубликованы ясные правила, как нужно отделять в тексте статьи один материал от другого. Материал будет иметь несколько обязательных тегов.
1. частный пример известной и уже опубликованной в базе закономерности
2. частный пример не опубликованной в базе закономерности
3. закономерность на уровне разных систем:
a. Химическая
b. Биохимическая
c. Физическая
d. Органы
e. Ткани
f. Клетки
g. Организм
h. Цнс организма
i. Врожденные инстинкты
j. Социальные инстинкты
k. Отрицание инстинктов, научение
l. Взаимодействие внутри популяции
m. Взаимодействие между популяциями
n. Между содружеством популяций (города)
o. Между городами
p. Между областями
q. Между странами
r. Между анклавами стран
s. Всемирное сотрудничество
t. Взаимодействие нескольких особей, в том числе:
i. М-Ж
ii. Самцовая кооперация
iii. Кооперация самок
iv. Бесполоая кооперация
v. Дружба
vi. Любовь
vii. Соперничество за (указать ресурс)
3.1.5 Типы пользователей.
3.1.6 8 типов Пользователей по принадлежности к тому или иному взводу, роте МП: Разведка, Огевая, Визуал, Научная, Безопасность, Психологический, PR, Региональные.
выше в пункте 4.1.3 три мы обсуждали, какие группы пользователей могут общаться с какими группами.
Пользователей по уровню доступа к БД есть 5 типов.
первые два типа пользователей не связаны с созданием научного продукта, не являются научными сотрудниками. С третьего по пятый- являются, четвертый пятый типы должны быть профильными студентами аспирантами кандидатами.
Четвертый тип может быть математиком, либо закончившим вуз социологом биологом.
1. Юзер1,юзер ПБ (пробной базы - ЮзПБ). Обычный пользователь. Но он может создавать пробную базу ПБ. У него есть плагин заполнения базы нулевого уровня - ПЗБ0. юзер может сам творить базу. Просто тогда то, что он делает, будет иметь статус ПБ. Юзер ПБ с помощью ПЗБ0 через выделение и правую кнопку (или лучше сочетание клавиш)заполняет базу данных всем, чем придется, создает строки и столбцы невпопад на основе существующей системы ОБ делает ПБ. Вставляет туда любую понравившуюся инфу. Он может просматривать базу ОБ, но не может просматривать базы ПБ других пользователей. Он может просматривать только свою базу ПБ.

v выходит окошко, в котором видна вся база данных ПБ в виде дерева. он выбирает, куда ставить свои данные
v если дерева нету, ему предлагается создать ответвление на основе существующих тем или новый ствол. Есть рекомендуемые темы. те, которые надо составлять в первую очередь.
v после того, как определено, куда вставлять, просят обязательные вещи:
§ пруф ссылка (если со статьи, то ссылка на статью, автор и название, DOi, isbn, можно прикрепить файл энд ноте). возможно взаимодействие с библиографическими программами. (у меня есть крякнутый энд ноте)
§ Если внутри данной инфы есть цифровые данные, к ним надо относиться особо. Хорошо было бы, что бы можно было выделить данные цифры и пометить их как цифровую информацию. Тогда для цифр из выделенного текста, должно быть определено свое место в базе данных. Для каждой цифры будет предложено определить два соотношения с уже имеющимися в базе числовыми или логическими параметрам (4 типа - пряма обратная регрессия, парабола, гипербола) – эти математические соотношения между переменными потом будут верефицированы админом более высокого порядка. Если пользователь низшего порядка не может сказать, как между собой связаны три уже существующих цифровых параметра в базе, он оставляет поле пустым, его потом заполнит админ выше рангом
§ он должен определить обязательные теги для материала (описаны выше)
2. админ ПБ.. Видит изменения, которые совершил юзер ПБ. Если ветка так себе, оставляет в песочнице ПБ. Если норм, то он ее и все соотношения переносит в ОБ. У него должны быть инструменты переноса такие, что бы не понимать программирование. Он может добавлять туда материалы, ветки, он сразу будут иметь статус ПБ. Может так же добавлять материал. Верифицирует математические соотношения. Если админ низшего порядка не может сказать, как между собой связаны три уже существующих цифровых параметра в базе, он оставляет поле пустым, его потом заполнит админ выше рангом
3. админ ОБ Видит изменения, которые совершил админ ПБ. Может исправлять то, что сделал тот админ, которые рангом ниже. Лишает права администрирования нижних админов, переводя их в пользователи. Смотри за заполнением различных веток форума. Есть какое то автоматически просчитываемое число, параметр, который говорит о том, что данная ветка базы данных – форума уже хорошо проработана и надо переходить к следующей. Направляет силы нижних баз наверх
4. математический админ. Смотри за всем соотношениями параметров внутри базы данных. Вставляет полученные данные в математические модели и проверяет на сходимость результатов. Пытается получить одни параметры базы через другие параметры базы в ходе работы мат моделей. В курсе математических моделей общества, знает их пару тройку штук, периодически проверяет на сходимость полученные данные с помощью не нейросетевых моделей. Если какие либо соотношения параметров дают хорошую параметризацию математических моделей общества, объясняют ранее не объяснённые факты, данный снимок базы данных называется стабильным и становиться каноном.
5. алгоритмический админ. Смотрим за алгоритмами и параметрами, не связанными математикой, или связанными не явным образом. Смотрит, какие каноны лучше.
Админы третьего четвертого типа должны иметь связи с учеными и студентами.
Админы четвёртого пятого типа должны постоянно учавстовать либо в создании мат моделей, либо в написании статей.
Структура базы НИИ есть сверху вниз и снизу вверх.
Сверху вниз на примере биологии такая (можно и на соционике создать)
наверху два три главных алгоритмщика, они спускают вниз задания. (Это не жестские задания. ими могут заниматься, могут нет). Например, стоит вопрос. Скажем «как альфы в племени отбирают ресурсы у всех». На основе запроса админы первой ступени.формируют первичное ТЗ для второй ступени.
1. «Найти, как отбираются ресурсы. «
Внизу на второй ступени сидят кодеры и математики первого уровня. Они думают, как реализовать это в коде и каких данных, каких чисел им не хватает. Тогда на третий уровень они спускают расширенное ТЗ:
1.1 Отбираются ли ресурсы?
1.2. сколько отбирается (цифры)
1.3. в каких условиях отбираются
пнукт 1.1 делают все, кому не лень. Пункт 1.3. – математики второго уровня.
Внизу после 1.3. сидит куча простых болтателей в интернете.
Они что то говорят.
Например, они говорят с натаЩей о том, что Баборабы все обеспечивают баб, а тем им за это дают пиписечку. Кто то находит пруфы. У него есть плагин "добавлялка в базу данных". Он, довольный, выделяет кусок текста и правой кнопкой мыши нажимает "добавить в базу данных мд".
Если это так себе текст, то в "сырую базу". Если считает, что текст норм, есть цирф и алгоритмы то в в "научную базу". он указывает, в какую тему и подтему входит данный кусок текста, какие цифры и алгоритмы в нем есть. Какие пруфы. без этого всего система в "научную базу" данный материал не добавит.
Может так случайно оказаться, что среди сотен срущихся в инетиках пользователей базы данных двое трое в угаре спора найдут какие то норм цифры с пруфами.
Когда те, кто сидят на уровне 1.3. полают инфу, они ее перепроверят, выставляют ее математическое соотношение с другими параметрами, находящимися в базе.
когда все подтверждено. второй уровень поднимает все навернх на первый уровень математиков и биологов. а оттуда все идет наверх двум трем алгоримщикам.
Надо спроектировать такую базу данных, куда потом можно будет добавлять строки стоблцы без знания программирования, приблизительно как в майкрософт акцесс.
то есть SQL с онлайн интерфейсом. Или джанго питон
Потом плагин, который можно добавить в хром или фаерфокс..
я могу оплачивать ежемесмячно какой нить сайт. на котором будет храниться все.
или же вообще файл в дропбоксе.просто все удалено будут туда вносить изменения. тогда и сайта не надо
сначала мона будет спроектировать сырую базу данных и посмотреть, что будет. через год посмотреть, как сделать научную базу данных.
а в ней нужно, что бы автоматически в нее всталвлось, с какого сайта все береться, а если со статьи, то туда надо подрубать данные EndNote библиографии с указанием страницы.
• это будет сайт
• с базой данных
Простые запросы в гугл достаточно просто обрабатываются. а вот чуть попроще...
это если запрос простой. а когда идет научный запрос на конкретные цифры и алгоритмы, он может находиться в неожиданном месте
если попробовать попользоваться гугл академией и поискать на английском через переводчик. "транспорт азота и фосфора через микоризу гриба в чернику" с учетом биомассы гриба...То из 50 ти статей только одна будет иметь нормальный текст. и все их приходиться закачивать и просматривать вручную
а тут будет автомат. за счет этого скорость работы научного сотрудника при обработке литературы повыситься в десятки раз.
Если это будет мат модель, то одна мат модель по доказательному потенциалу будет выше любой статьи в сотни раз.
Если сделать сеть, базу данных, она эффективнее обычных статей и монографий в десять раз.
Так как база данных- древо, то будет так.
Основа древа- факты. Измерения.
ЧТо бы обьяснить измерение, могут быть несколько гипотез и теорий.
Каждый делает свою ветку базы данных, туда кладет свои пруфы и расччеты.
Когда ветка каждой базы данных заполняется, проводиться некое моделирование и решается, какая ветка предсказывает и обьясняет лучше. Это делает автомат или консулиум.
Если вопрос не решился, он выноситься на обсужение.
Есть важные и не очень важные ветки.
Есть ветки, от которых зависит все.
Например:
Человек чистый лист или у него есть генетические способности и инстинкты?
Береться 500-100 фактов, и каждый обьясняется в том или ином ключе. потом все суммируется и у кого больше обьяснений, тот и выиграл.
Обьяснения должны быть построены по логической структуре. Например, должна быть бритва оккама.
Тогда внешнее обсуславливание будет заставлять людей меньше сраться, а больше соблюдать внешние правила системы. Просто если она увидит, что одно обьяснение соответствует бритве оккама, а другое нет, она повышает рейтинг того, которое соовтетствует.
И когда чел будет сраться в инетиках, то ему будут скорее предоставлять Окамное обьяснение. таких логических правил может быть много. Немного о логических правилах говориться в блоке о оценивании пользователей.
Кратко что нужно по компонентам и процессам в БП
Есть 8 групп вк. Между ними надо настроить ступенчатые потоки информации через поэтапный перепост все сокращающейся инфы из группы в группу. При этом пользователь должен обязательно указать несколько видов ТЭГОВ, иначе материал не будет принят в базу данных. Эти 8 групп пользователей в конце концов будут постить материал в 5 групп вк и одновременно в базу данных, которая более разветвлена, чем 5 групп вк.
При этом пользователи разделяются на 5 групп доступа к базе данных.
Есть база сырая, которая делается админами низшего уровня, админы высшего эти изменения либо применяют. Либо нет.
Требование к физической структуре
По возможности база данных экологической документации должна быть организована на основе трехкомпонентной структуры (таблица 4.1).
Первый уровень – хранения данных, обеспечивает сервис физического хранения. К этому уровню относятся сервера баз данных, файловые и ленточные хранилища.
Второй уровень – обработки данных, обеспечивает функционирование бизнес-логики на уровне базовых операций с данными.
Третий уровень – представления данных, обеспечивает интерфейсы и сервисы конечному пользователю.
Физически подсистемы каждого уровня могут быть, как объединены в рамках одного, так и разнесены по разным серверам.
Таблица 4.1
Распределение задач в 3-х уровневой платформе обработки данных
| Уровень | Задачи | Реализация |
| Хранения данных | Постоянное хранение данных | СУБД, файловое, ленточное хранение. Обеспечение для уровня обработки данных сервиса хранения документов, объектов информации и их атрибутов/ Желательно что бы можно было сменить потом SQL реализацию на Джанго реализацию или, может, Postgress- реализацию. |
| Обработки данных | Выполнение над данными базовых операций | Бизнес-логика модулей, интерфейсы с уровнем представления данных и другими модулями: Вырезка данных с одной ветки и вставка в другую ветку Прикрепление тэгов Указание, с какиими другими ветками и столбцами связана данная ветка Запрет различным группам пользователей каких либо действий. Так, с группы визуала люди не могут что то отправить в группу УНП, а УНП в визуал может направить всё, что угодно Модуль расширения базовой функциональности |
| Представления данных | Организация интерфейса БП, навигации в нём, вставки в него материалов | Плагин к гугл хрому или фаервфоксу, или же устанавливаемая на компьютер программа или же чат бот вк. |
Техническое обслуживание серверов и архивов системы, включая архивирование и резервное копирование, должно осуществляться силами Заказчика.
Требования к надёжности системы
Система должна обеспечить возможность восстановления данных при внештатных ситуациях, связанных с выходом из строя серверов, ленточных и дисковых хранилищ, ошибочного удаления данных.
Для обеспечения надёжного функционирования базы данных экологической документации техническому персоналу Заказчика необходимо предусмотреть:
Ежедневный импорт базы в XML файл
Ежедневный импорт (заголовков?) базы в mindmap-публичный файл
Общую папку в Dropbox и гуглДиске
Требования к лингвистическому обеспечению
Взаимодействие ПО базы данных экологической документации и пользователя должно осуществляться на русском языке. Допускается выводить сообщения на иных языках, сгенерированные средствами разработки ПО (СУБД, компиляторы, web-серверы, web-обозреватели и т.д.), если они не имеют средств настройки языка сообщений или находятся вне зоны ответственности обслуживающего персонала.
Требования к техническому обеспечению
База данных экологической документации должна обеспечивать следующие политики безопасности:
В случае необходимости и наличия технической возможности аутентификация пользователей должна осуществляться по имени и паролю средствами ВК
Права на чтение и запись информации должны раздаваться на уровне отдельных групп пользователей;
В случае необходимости должна выполняться регистрация действий пользователей системы.