1.6.2 Порты и сокеты
За передачу данных в сети Интернет отвечают два протокола транспортного уровня - UDP (User Datagram Protocol) и TCP (Transmission Control Protocol). Данные передаются программами-приложениями этим протоколам, помещаются в "конверты" с набором соответствующих заголовков и только после этого передаются по сети.
UDP - это не очень надежная служба передачи данных. Отправитель данных не получает подтверждения их доставки получателю. Этот протокол не упорядочивает передаваемые пакеты, некоторые из них могут быть потеряны или, наоборот, возможно дублирование пакетов без попыток уведомления об ошибках отправителя данных. Протокол IP ведет себя так же. Единственное достоинство UDP - это поддержка номеров портов, что обеспечивает абсолютную идентификацию конкретных программ - приложений, работающих на компьютере, подключенном к сети, и подсчет контрольной суммы для простейшего контроля над ошибками. Но UDP работает быстрее, чем TCP (ведь заголовки пакетов у него в пять раз короче - 8 против 40 байт!), и используется приложениями, которым не нужен надежный транспорт, например управляющими сетью, службой определения сетевых адресов либо приложениями со встроенной надежностью. Каждая программа, которая использует в качестве транспорта протокол UDP, должна сама позаботиться о подтверждении получения данных и об упорядочивании и сортировке пакетов принимающей стороной.
Протоколы транспортного уровня имеют свой заголовок, и его формат не зависит от других протоколов. Вот общий вид заголовка UDP пакета:

Длина сообщения - это сумма размера заголовка (8 байт) и передаваемого блока данных. Минимальный размер пакета UDP равен восьми байтам, размеру заголовка. Если контрольная сумма не используется, значение этого поля может быть равным нулю.
Протокол транспортного уровня (UDP или TCP) получает данные от программы-приложения, форматирует их (формирует заголовок) и передает их IP протоколу для передачи по сети. Если UDP получает данные от сети (от IP протокола), то в зависимости от порта назначения он передает их соответствующему приложению.
Обратимся к сетевым стандартам (а конкретно - к RFC 814). Так как различные сетевые приложения могут выполняться на одном компьютере, имеющем один IP адрес, возникает необходимость в способе адресации пакетов данных этим приложениям. Один IP адрес и много приложений? Как разобраться, какому приложению адресовать какой пакет???
Может быть, раздать уникальные IP адреса всем приложениям и сетевым процессам или изменить саму систему адресации в сети Интернет и включить в нее указатель - идентификатор приложения? Вместо этого, протоколы UDP и TCP предлагают понятие, известное как "номер порта", port number. Комбинация IP адреса компьютера и номера порта позволяет абсолютно точно идентифицировать любую программу или приложение, выполняемую на любом компьютере, подключенном к сети.
Существует три вида номеров портов:
- назначенные (assigned)
- зарегистрированные (registered)
- динамические (dynamic)
Назначенные и зарегистрированные номера портов регламентируются отдельным серьезным документом - RFC 1700. Первые 1024 номера (с 0 по 1023) отведены под назначенные и не могут использоваться другими приложениями, кроме тех, за которыми они закреплены. Оставшаяся область делится между зарегистрированными и динамическими номерами (отведенные на номер порта 16 бит дают возможность использовать всего 65535 виртуальных портов). А следит за порядком в этой области специальная организация - IANA (Internet Assigned Numbers Authority). Именно к ее услугам прибегают все компании-производители сетевого программного обеспечения, когда хотят зарезервировать за своим продуктом определенный номер порта.
Примеры назначенных номеров портов:
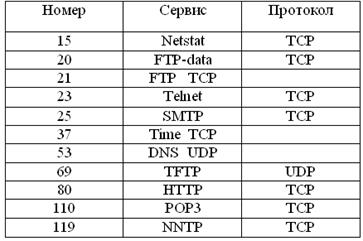
Когда любой компьютер хочет вступить во взаимодействие с любым удаленным приложением, он должен идентифицировать это приложение в своих пакетах с запросом на получение информации.
Например, если рабочая станция хочет использовать простой протокол передачи файлов, известный как TFTP (Trivial File Transfer Protocol), на компьютере с адресом 192.1.1.1, то пакеты будут адресованы этому компьютеру, но с указанием номера порта назначения (69 для протокола TFTP) в заголовке UDP пакета.
Порт источника будет указывать на приложение, работающее на этой рабочей станции и отправившее запрос на передачу файла, и все пакеты, полученные из сети для этого приложения, будут идентифицированы по этому номеру порта. Обычно номер порта источника выбирается случайным образом из диапазона динамических номеров. Если порт источника не используется его значение равно "0".
Недостаток при использовании динамических номеров портов может проявиться при широковещательной рассылке по сети пакетов данных, в которых в качестве порта назначения используется динамический адрес. Ведь этот порт может уже использоваться любой программой на любом компьютере в локальной сети и пакет будет доставлен "не по адресу".
Случай это весьма редкий, но все же иногда происходит.
Динамические номера портов назначаются сетевыми программами - приложениями на компьютере - рабочей станции, причем различные приложения на различных компьютерах могут использовать одни и те же номера портов, так как любое приложение на любом компьютере может быть идентифицировано при помощи комбинации IP адреса компьютера и номера порта программного приложения.
Вот эта комбинация и называется сокетом (socket), например, 192.1.1.1:25 - это адрес SMTP сервера на компьютере с адресом 192.1.1.1.
Если для упрощения провести аналогию между взаимодействием двух компьютеров по сети и телефонным соединением, то сокет выступает в роли телефонной линии, а номер порта заменяет номер телефона.
1.6.3 Http, ftp и др. протоколы прикладного уровня
Для человека, пользующегося Интернетом каждый день, просмотр веб-страниц или чтение почты не требуют огромных усилий или специального образования. Можно и не подозревать, что каждый щелчок мыши или нажатие кнопки порождает множество разнообразных процессов, связанных друг с другом, иногда конфликтующих и борющихся за ресурсы. От глаз пользователя все это хитрое взаимодействие скрыто, доступен лишь конечный результат. Чтобы понять, как на самом деле происходит то, что предстает перед нами в виде цепочки тривиальных действий, заглянем внутрь Сети...
В основе любого взаимодействия лежит протокол – некие правила, определяющие порядок обмена информацией и ее вид. При общении между людьми такой протокол называется этикетом. Он зависит от культурных традиций, характера взаимоотношений собеседников, текущей ситуации. В компьютерных сетях протокол определяется задачей, для выполнения которой он создавался.
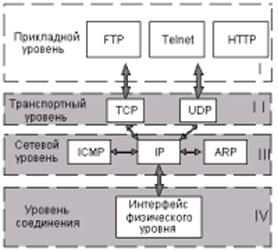
Рис. 6.1. Сетевая модель TCP/IP.
Чтобы передать информацию от одной системы к другой, например, от вашего подключенного к Интернету компьютера на сайт www.shkolazhizni.ru, используется целое многоуровневое семейство протоколов.
На самом верхнем уровне, называемом прикладным, вы набираете адрес (или ищете в журнале, или пользуетесь избранными ссылками) в программе Internet Explorer, Opera, Firefox или другой, жмете клавишу Enter и ждете. Протокол прикладного уровня хватает этот адрес, добавляет к нему служебную информацию, разбивает при необходимости получившиеся данные на кусочки, упаковывает каждый кусочек особым образом и передает протоколу, лежащему уровнем ниже. Такая процедура повторяется несколько раз, в результате чего ваши кусочки превращаются в колебания напряжения в линиях передачи, например, телефонных, или радиосигналы в случае беспроводного Интернета.
Именно в таком виде их получает система, для которой данные предназначены. Она проделывает с ними то же самое, что и ваша, только в обратном порядке. Данные через серию преобразований поднимаются на прикладной уровень, где их можно интерпретировать. Например, сообразить, что вы запросили у веб-сервера файл index.html, находящийся в каталоге www. После чего описанным уже способом отправить вам долгожданную страницу. Если надо, с картинками.
В общем виде так работает любой протокол прикладного уровня семейства TCP/IP, которое в силу исторических причин большинство из нас используют при обращении к сети Интернет. Наиболее часто мы сталкиваемся с протоколами HTTP, FTP, POP3, SMTP, реже – telnet.
HTTP – протокол передачи гипертекста. С его помощью ваша программа веб-навигатор общается с веб-серверами. Общение представляет собой отправку запросов и получение ответов. Ответы содержат запрашиваемые данные – документы, рисунки, исполняемые файлы и другое. Именно этот протокол позволяет вам просматривать веб-страницы.
FTP – протокол передачи файлов. Его мы используем, чтобы отправить или получить файлы с удаленного компьютера. Для этого на одном из компьютеров должна быть установлена, настроена и запущена служба, которая называется FTP-сервером, а второй компьютер с использованием программы, называемой FTP-клиентом, должен подключиться к первому.
POP3 – почтовый протокол. С помощью него мы получаем свою почту с почтовых серверов, например, mail.ru. Как и в предыдущем случае, на сервере запущена соответствующая служба, а у нас на компьютере установлена и настроена программа-клиент – например, MS Outlook.
SMTP – простой протокол передачи почты. Он позволяет нам отправлять почтовые сообщения со своего компьютера на почтовый сервер. Как и FTP и POP3, этот протокол требует, чтобы сервер «был знаком» с нами, то есть, хранил логическое имя и пароль, с помощью которого мы будем к нему обращаться. Только в некоторых случаях можно обратиться к серверу FTP или SMTP анонимно.
telnet – протокол сетевых телекоммуникаций. Один из старейших прикладных протоколов. С его помощью можно запускать различные процессы на удаленном компьютере, при соответствующих разрешениях, - например, отправить на печать 200 страниц текста «хочу печенья!».
1.6.4 MIME, типы и расширения
Как мы знаем, в World Wide Web доступна информация самого различного рода, закодированная во множестве разнообразных форматов. Некоторые из этих форматов "понимает" сама программа просмотра, другие она передает программам-помощникам. Возникает вполне законный вопрос о том, как программа просмотра распознает формат файла, загруженного с локального диска или с удаленного WWW-сервера. Ответ таков: При загрузке файлов с локального диска программа просмотра определяет тип по расширению имени файла. Если же файл приходит с удаленного WWW-сервера, то сервер высылает программе просмотра некоторую служебную информацию перед тем, как передавать собственно содержимое требуемого файла. Эта служебная информация включает стандартный идентификатор типа файла (Content-Type), на который в этом случае и ориентируется программа просмотра. Такой идентификатор типа получил название MIME-type, где MIME - аббревиатура начальных букв Multiporpose Internet Mail Extensions (Многоцелевые Расширения Электронной Почты Internet). Для MIME в последнее время используется также название Internet Media Types. Идентификатор типа MIME состоит из двух частей: идентификатора типа и идентификатора подтипа, разделенных косой чертой /. Некоторые из наиболее часто встречающихся типов файлов, их расширения и стандартные MIME-типы приведены в нижеследующей таблице.
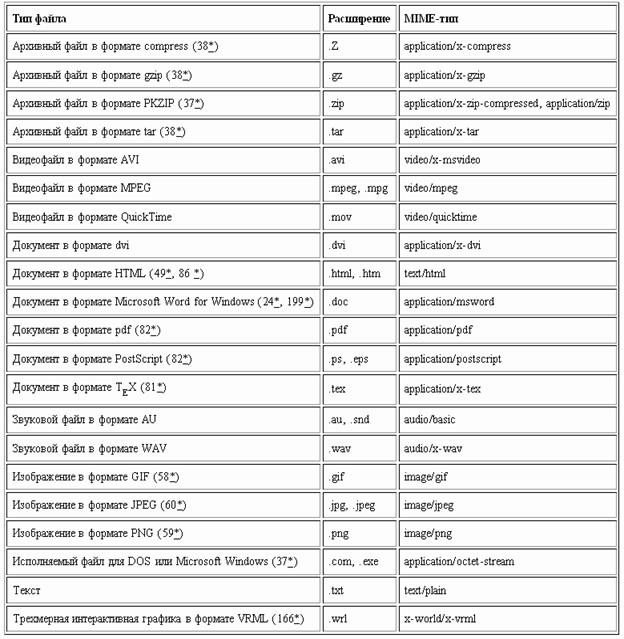
Вам, как пользователю программы просмотра, возможно, придется столкнуться с MIME-типами при настройке так называемых программ-помощников (Helper Applications, Helpers). Если программа просмотра не знает, у какой программы попросить помощи при интерпретации данного файла то она предлагает вам выбрать, какую программу, установленную на вашем компьютере, запускать для обработки файлов данного MIME-типа. Можно настроить программу-помощника для данного MIME-типа и заранее. В Netscape Navigator 3.0 для этого следует выбрать меню Options | General Preferences, а затем ввести соответствующую информацию в диалоговом окне в категории Helpers.
1.6.5 Этапы транзакции http
Сеанс взаимодействия клиента и сервера на основе протокола HTTP называется HTTP-транзакцией. В простейшем случае HTTP-транзакция состоит из четырех последовательных этапов:
- установка соединения (инициируется клиентом);
- передача сообщения запроса от клиента серверу;
- передача сообщения ответа от сервера клиенту;
- разрыв соединения (инициируется сервером).
В рамках HTTP 0.9 и 1.0 такая схема является единственно возможной. Она, однако, далека от совершенства. Судите сами — передача веб-страницы с 10 графическими изображениями в описываемом случае требует установить и разорвать TCP-соединение между одной и той же парой клиент — сервер как минимум 11 раз (по одному разу на HTML-код и каждую картинку). Это число, разумеется, возрастет, если с веб-страницей, помимо упомянутого десятка изображений, будут связаны и другие объекты — например, внешние листы стилей, сценарии на языке JavaScript, Flash-ролики и т. д.
В глобальных масштабах рассматриваемое явление, как вы понимаете, далеко не самым лучшим образом отражается на загруженности веб-серверов, каналов связи и промежуточного сетевого оборудования. Для конечного пользователя все это проявляется в виде ощутимых задержек при загрузке страниц.
Как уже говорилось выше, веб-сервер запускается обычно от имени суперпользователя. Сказанное относится, однако, только к главному исполняемому модулю сервера. Каждое соединение обрабатывается отдельным дочерним процессом, запускаемым от имени непривилегированного пользователя (в UNIX-системах это обычно пользователь с именем nobody). Чем больше соединений открывает сервер, тем большее количество обслуживающих их дочерних процессов порождается. (Предельное их число, разумеется, контролируемо при помощи соответствующего параметра конфигурации.)
Обсуждаемый недостаток был преодолен за счет механизма постоянных соединений, реализованного в HTTP 1.1. Благодаря этому нововведению стало возможным обрабатывать несколько HTTP-запросов в ходе одного TCP-соединения.
Конфигурация большинства современных веб-серверов по умолчанию разрешает постоянные соединения. Разрыв соединения производится сервером по тайм-ауту или же по факту превышения некоторого порогового количества HTTP-запросов, разрешенного к обработке в рамках одного соединения. Так, Apache 1.3x (в конфигурации по умолчанию) ожидает следующего запроса клиента в течение 15 секунд, после чего, в случае «молчания» клиента, разрывает соединение; максимально возможное количество запросов в ходе одного соединения при этом равно 100. Разумеется, администратор сервера может произвольным образом изменять указанные настройки, в том числе и таким образом, чтобы полностью отменить ограничение на количество запросов в рамках постоянного соединения.
Несмотря на то, что разрыв соединения является прерогативой сервера, как клиент, так и сервер должны корректно отрабатывать незапланированные разрывы соединений (например, при нажатии пользователем кнопки Остановить в панели инструментов браузера или же вследствие каких-либо программных или аппаратных сбоев).
Схема HTTP-транзакции нередко усложняется еще и за счет возможного применения пользователями прокси-серверов при доступе к ресурсам Web. В данном случае в цепочку клиент — сервер включается дополнительное звено (или даже несколько звеньев, поскольку один прокси-сервер может работать через посредство другого прокси-сервера).
1.6.6 Понятия URI, URL
Стандарт URI
Документ RFC3986, "Универсальный идентификатор ресурсов (URI): общий синтаксис" - это стандарт интернета. Так называемая серия "Запросы на комментарии" (Request for Comments - RFC) - это известная серия архивных документов, которая является основой процесса разработки стандартов в Проблемной группе проектирования Internet (Internet Engineering Task Force - IETF). Только несколько из тысяч документов RFC, такие как протокол управления передачей (Transmission Control Protocol - TCP) и почтовый формат (RFC821) и протокол (RFC822) интернета получили полный статус стандартов интернета. RFC3986 получил этот статус в январе 2005 г.
Согласно стандарту URI, первый из вышеприведенных примеров - https://www.cisco.com/en/US/partners/index.html является настоящим URI и включает несколько составляющих его частей:
- имя схемы (http);
- имя домена (www.cisco.com);
- путь (/en/US/partners/index.html).
Непротиворечивый процесс IETF управляет схемами. Официальный реестр схем URI Агентства по выделению имен и уникальных параметров протоколов Internet (Internet Assigned Numbers Authority - IANA) включает как общеизвестные схемы, такие как http, https и mailto, так и множество других, менее знакомых широкому кругу пользователей.
URI-путь выглядит как типичный путь доступа к файлу. URI унаследовали левую косую черту (a/b/c) из традиций UNIX, поскольку в конце 1980-х годов, когда они разрабатывались, в интернете преобладала культура UNIX, а не PC. Тогда существовало несколько распространенных представлений для доступа к удаленным файлам. Одно из них - это Ange-ftp, расширение emacs для редактирования удаленных файлов. Оно сводило воедино имена хост-узла и пользователя с путем доступа к файлу, и в результате получалась конструкция такого типа: /jbrown@freddie.ucla.edu:~mblack/. Синтаксис URI, разработанный для интернета, использовал двойную левую косую черту для перекрестного обращения к машинам (это унаследовано из диалекта Apollo Domain UNIX). Помимо этого, он ввел в обращение синтаксис схем для того, чтобы можно было унифицировать соглашения о присвоении имен из любого количества различных протоколов. Вот несколько примеров:
- mailto:mbox@domain
- ftp://host/file
- https://domain/path.
Второй пример во введении, www.yahoo.com/sports, на самом деле не является настоящим URI. Это удобное сокращение для https://www.yahoo.com/sports. Такой формат поддерживается пользовательскими интерфейсами распространенных Web-браузеров. Но если схема XSLT записана следующим образом:
<xsl:includehref="exslt.org/math/min/math.min.template.xsl"/>,
то она не будет работать, как ожидается, если только это выражение не является обращением к файлу в директории exslt.org, находящейся рядом с таблицей стилей XSLT. Атрибут href в XSLT означает URI-ссылку, которая может быть абсолютной или относительной. Если URI-ссылка начинается со схемы и двоеточия, то она является абсолютной, в противном случае - относительной. Относительная URI-ссылка очень похожа на путь доступа к файлу. Например,../noarch/config.xsd - это относительная URI-ссылка.
URL и URN
URI разработаны таким образом, чтобы выполнять функции и имени, и адреса. После того, как они поступили в IETF для стандартизации, их стали именовать унифицированными указателями информационных ресурсов (Uniform Resource Locators); одновременно началась работа над разработкой унифицированных имен ресурсов (Uniform Resource Names).
Для имен и ресурсов интернет-хостов существуют отдельные стандарты. Синтаксис имен хостов такой же, как и имен доменов (например, zork1.example.edu). Эти имена связаны с адресами типа 192.168.300.21 с помощью протокола системы имен домена (Domain Name System - DNS). Такая непрямая связь позволяет именам оставаться стабильными, когда хосты перемещаются в сети и их нумерация изменяется.
Случайные неработающие ссылки в интернете приводят к тому, что Web-адреса становятся больше похожими на указатели, а не на имена, поэтому в сообществе IETF возникли различные предложения:
- URI: запрос RFC1630, выпущенный в июне 1994 г., был назван "Универсальные идентификаторы ресурсов в WWW: единый синтаксис для выражения имен и адресов объектов в сети, используемый во Всемирной сети Интернет" (Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web). Это был информационный запрос, т.е. он не получил общего одобрения IT-сообщества;
- URL: запрос RFC1738, выпущенный в декабре 1994 г., был назван "Унифицированные указатели информационных ресурсов" (Uniform Resource Locators). Это был предлагаемый стандарт, т.е. он являлся результатом согласований, хотя еще и не был в достаточной степени проверенным и зрелым, чтобы стать стандартом для всего интернета;
- URN: запрос RFC1737, выпущенный в декабре 1994 г., был назван "Функциональные требования для унифицированных имен ресурсов".
В 1997 г. за запросом RFC1737 последовал предлагаемый стандарт RFC2141 - "Синтаксис URN", который описывал спецификацию еще одной схемы - urn, в дополнение к уже существовавшим http:, ftp: и другим.
Окончательный стандарт URI RFC3986 объясняет различие между этими понятиями в секции 1.1.3 - "URI, URL и URN":
URI может далее рассматриваться как указатель, имя или и то, и другое. Термин "унифицированный указатель информационных ресурсов" (URL) относится к подмножеству URI, которые, помимо идентификации ресурса, указывают способ его нахождения путем описания основных механизмов доступа к нему (т.е. его "положение" в сети). Термин "унифицированное имя ресурса" (URN) исторически использовался как для URI в пределах схемы urn, которые должны оставаться уникальными в мировом масштабе и оставаться стабильными, даже если ресурс прекращает существование или становится недоступным, так и для любых других URI со свойствами имени.
Отдельная схема не обязательно должна рассматриваться только как "имя" или "указатель". Конкретные URI из любой схемы могут иметь характеристики как имен, так и указателей, или обоих этих понятий. Часто это зависит от постоянства и тщательности в распределении идентификаторов полномочным органом по присвоению имен, а не от качества схемы. В будущих спецификациях и связанных с ними документах должен использоваться общий термин URI, а не более узкие понятия URL и URN.
1.6.7 Схемы http-сеанса
Центральным объектом в HTTP является ресурс, на который указывает URI в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя изначально данный протокол предназначен для передачи символьной информации. На первый взгляд это может показаться излишней тратой ресурсов. Действительно, данные в символьном виде занимают больше памяти, сообщения создают дополнительную нагрузку на каналы связи, однако подобный формат имеет много преимуществ. Сообщения, передаваемые по сети, удобочитаемы, и, проанализировав полученные данные, системный администратор может легко найти ошибку и устранить ее. При необходимости роль одного из приложений может выполнять человек, вручную вводя сообщения в требуемом формате.
В отличие от многих других протоколов, HTTP является протоколом без памяти. Это означает, что протокол не хранит информацию о предыдущих запросах клиентов и ответах сервера. Компоненты, использующие HTTP, могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами. Т.е клиентское веб-приложение, посылающее запросы, может отслеживать задержки ответов, а веб-сервер может хранить IP-адреса и заголовки запросов последних клиентов.
Все программное обеспечение для работы с протоколом HTTP разделяется на три основные категории:
1. Серверы - поставщики услуг хранения и обработки информации (обработка запросов).
2. Клиенты - конечные потребители услуг сервера (отправка запросов).
3. Прокси-серверы для поддержки работы транспортных служб.
Основными клиентами являются браузеры например: Internet Explorer, Opera, Mozilla Firefox, Netscape Navigator и другие. Наиболее популярными реализациями веб-серверов являются: Internet Information Services (IIS), Apache, lighttpd, nginx. Наиболее известные реализации прокси-серверов: Squid, UserGate, Multiproxy, Naviscope.
"Классическая" схема HTTP-сеанса выглядит так.
1. Установление TCP-соединения.
2. Запрос клиента.
3. Ответ сервера.
4. Разрыв TCP-соединения.
Таким образом, клиент посылает серверу запрос, получает от него ответ, после чего взаимодействие прекращается. Обычно запрос клиента представляет собой требование передать HTML-документ или какой-нибудь другой ресурс, а ответ сервера содержит код этого ресурса.
В состав HTTP-запроса, передаваемого клиентом серверу, входят следующие компоненты:
1. Строка состояния (иногда для ее обозначения используют также термины строка-статус, или строка запроса).
2. Поля заголовка.
3. Пустая строка.
4. Тело запроса.
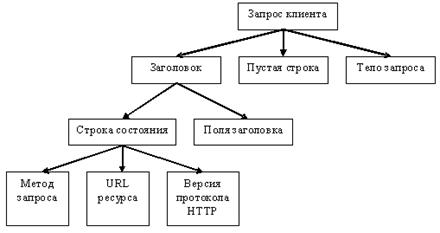
Рис. 6.2. Схема HTTP-сеанса.
Строка состояния имеет следующий формат:
метод_запроса URL_pecypca версия_протокола_НТТР
Рассмотрим компоненты строки состояния, при этом особое внимание уделим методам запроса.
Метод, указанный в строке состояния, определяет способ воздействия на ресурс, URL которого задан в той же строке. Метод может принимать значения GET, POST, HEAD, PUT, DELETE и т.д. Несмотря на обилие методов, для веб-программиста по-настоящему важны лишь два из них: GET и POST.
1. GET. Согласно формальному определению, метод GET предназначается для получения ресурса с указанным URL. Получив запрос GET, сервер должен прочитать указанный ресурс и включить код ресурса в состав ответа клиенту. Ресурс, URL которого передается в составе запроса, не обязательно должен представлять собой HTML-страницу, файл с изображением или другие данные. URL ресурса может указывать на исполняемый код программы, который, при соблюдении определенных условий, должен быть запущен на сервере. В этом случае клиенту возвращается не код программы, а данные, сгенерированные в процессе ее выполнения. Несмотря на то что, по определению, метод GET предназначен для получения информации, он может применяться и в других целях. Метод GET вполне подходит для передачи небольших фрагментов данных на сервер.
2. POST. Согласно тому же формальному определению, основное назначение метода POST - передача данных на сервер. Однако, подобно методу GET, метод POST может применяться по-разному и нередко используется для получения информации с сервера. Как и в случае с методом GET, URL, заданный в строке состояния, указывает на конкретный ресурс. Метод POST также может использоваться для запуска процесса.
3. Методы HEAD и PUT являются модификациями методов GET и POST.
Версия протокола HTTP, как правило, задается в следующем формате:
HTTP/версия.модификация
Поля заголовка, следующие за строкой состояния, позволяют уточнять запрос, т.е. передавать серверу дополнительную информацию. Поле заголовка имеет следующий формат: Имя_поля: Значение
1.6.8 Структура Запроса клиента
Имена некоторых наиболее часто встречающихся в запросе клиента полей заголовка и их назначение показаны на рис.

Рис 6.3. Поля заголовка запроса HTTP.
Во многих случаях при работе в Веб тело запроса отсутствует. При запуске CGI-сценариев данные, передаваемые для них в запросе, могут размещаться в теле запроса.
Получив от клиента запрос, сервер должен ответить ему. Знание структуры ответа сервера необходимо разработчику веб-приложений, так как программы, которые выполняются на сервере, должны самостоятельно формировать ответ клиенту.
1.6.9 Структура ответа сервера
Подобно запросу клиента, ответ сервера также состоит из четырех перечисленных ниже компонентов: