Введение
Статистикой называется наука, изучающая количественные показатели развития общества и общественного производства. Статистическим исследованием называют внутренне соотношение явлений в отрыве от их развития, движения.
Для того, чтобы провести статистическое исследование, необходима научно обоснованная информационная база. Она формируется в результате статистического наблюдения, которое является начальной стадией экономико-статистического исследования. Статистическим наблюдением называется планомерно научно обоснованный сбор данных или сведений о социальных экономических явлениях и процессах.
Статистическое наблюдение проводится строго в соответствии с планом статистических исследований. При подготовки и проведении статистического наблюдения необходимо решить целый ряд вопросов, которые можно подразделить на:
1. программно-методологические;
2. организационные.
Общая цель статистического наблюдения состоит в информационном обеспечении управления. Объект наблюдения состоит из отдельных единиц, каждая из которых представляет собой элемент совокупности, по которому собираются необходимые данные.
Организационный план – это основной документ, отражающий вопросы организации и проведения статистического наблюдения.
Эта контрольная работа основана на статистическом наблюдении, в частности – это выборочный способ.
Сводка и группировка
Сводка – систематизация единичных фактов, позволяющая перейти к обобщающим показателям, относящимся ко всей изучаемой совокупности и ее частям, и осуществлять анализ и прогнозирование изучаемых явлений и процессов.
Статистическая сводка в широком ее понимании предполагает систематизацию и группировку цифровых данных, характеристику образованных групп системой показателей, подсчет соответствующих итогов и представление результатов сводки в виде таблиц, графиков.
В зависимости от задач, решаемых с помощью группировок, выделяют 3 типа группировок: типологические, структурные и аналитические. В данной курсовой работе я применяю типологический метод группировки. Типологическая группировка решает задачу выявления и характеристики социально-экономических типов.
Сгруппируем опрошенных респондентов по трем сегментам в зависимости от их дохода и составим статистическую таблицу, где респонденты будут распределены не только по доходам, но и по их предпочтениям в цене за использование экспертных систем в обучении.
| Доход, руб. | Цена товара, руб. | |||
| До 3000 | ||||
| От 3000 до 7000 | ||||
| Более 7000 | ||||
| Значения спроса наращенным итогом | ||||
| Доход, руб. | Цена товара, руб. | |||
| До 3000 | ||||
| От 3000 до 7000 | ||||
| Более 7000 |
Расчет I сегмента
Аппроксимация
| p | |||
| q | |||
| pq |
p – значение максимальной цены, которую потребители готовы заплатить за данный товар;
q – количество человек, которые готовы купить данный товар по указанной цене;
pq – выручка.
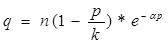
30 = n(1 – 40/k)*2-40α
20 = n(1 – 50/k)*2-50α
6 = n(1 – 60/k)*2-60α
1,5 = (k – 40)/(k – 50)*240α
3,3 = (k – 50)/(k – 60)*240α
0,45 = (k – 40)*(k – 60)/(k – 50)2
k2 – 100k +2400 = 0,45k2 – 45k + 1125
0,55k2 – 55k + 1275 = 0
D = 220
k1,2 = (55±√220)/2*0,55 = (55±14,83)/1,1
k1= (55+14,83)/1,1 = 63,48 k2= (55-14,83)/1,1 = 36,52
1,5 = (k – 40)/(k – 50)*240α
ln1,5 = ln240α + ln(k – 40) – ln(k – 50)
40α ln2 = ln1,5 + ln(k – 40) – ln(k – 50)
α = (ln(1,5(k – 40))/(k – 50))/40 ln2
α ≈ 0,01
n = (q*240α)/(1 – 40/k)
n ≈ 107
Оптимальная цена, выпуск, максимальная выручка
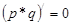


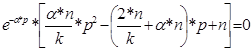 , причем
, причем 

Из этого выражения можно получить значение p:

p1,2 = ((2*107/63,48 + 0,01*107) ± √[(2*107/63,48 + 0,01*107)2 – 4*0,01*1072/63,48])/((2* 0,01*107)/63,48) ≈ (4,44 ± 3,54)/0,03
p1 = 236,66 p2 = 26,82 – оптимальная цена (модальная)
q = n(1 – p/k)*e-αp = 107(1 – 26,82/63,48)*2-0,01*26,82 ≈ 51 – оптимальный выпуск
p*q = 51*26,82 = 1367,82 – максимальная выручка
Средняя ошибка доли
Все население РТ составляет 3761500 человек.
I сегмент с доходами до 3000 рублей составляет 23,53%.

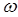 - выборочная доля
- выборочная доля
n - объем выборки
N – генеральная совокупность

m – единица выборки, обладающая изучаемым признаком
n – общая численность выборки
Значение доли стандартных изделий по всей партии продукции определяется по формуле:

Предельная ошибка выборки определяется по формуле:

t – коэффициент доверия
Доверительный интервал определяется по формуле:
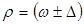
ω = 51/107 ≈ 0,477
Генеральная совокупность:
N = 3761500/4 = 940375 (население Татарстана деленное на число членов стандартной семьи)
μω = √[(0,477*(1 – 0,477))/107 * (1 – 107/940375)] ≈ 0,048
p = 0,477 ± 2*0,048
p1 = 0,477 - 2*0,048 = 0,38 p2 = 0,477 + 2*0,048 = 0,573
0,38<p<0,573
∆ω = 2* √(0,477*(1 – 0,477))/107 ≈ 2 * 0,0483 = 0,0966
p = (0,477 ± 0,0966)
p1= 0,477 – 0,0966 = 0,3804 p2 = 0,477 + 0,0966 = 0,574
0,3804<p<0,574
Расчет II сегмента
Аппроксимация
| p | |||
| q | |||
| pq |
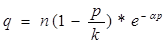
31 = n(1 – 40/k)*2-40α
13 = n(1 – 50/k)*2-50α
5 = n(1 – 60/k)*2-60α
2,38 = (k – 40)/(k – 50)*240α
3,25 = (k – 50)/(k – 60)*240α
0,73 = (k – 40)*(k – 60)/(k – 50)2
k2 – 100k +2400 = 0,73k2 – 73k + 1825
0,27k2 – 27k + 575 = 0
D = 108
k1,2 = (27±√108)/2*0,27 = (27±10,39)/0,54
k1= (27+10,39)/0,54 = 69,24 k2= (27-10,39)/0,54 = 30,76
3,25 = (k – 40)/(k – 50)*240α
ln3,25 = ln240α + ln(k – 40) – ln(k – 50)
40α ln2 = ln3,25 + ln(k – 40) – ln(k – 50)
α = (ln(3,25(k – 40))/(k – 50))/40 ln2
α ≈ 0,01
n = (q*240α)/(1 – 40/k)
n ≈ 97