О задачах поиска и сортировки для массивов и файлов
Задачи поиска и сортировки для массивов и файлов - очень часто встречающиеся задачи при работе с данными. Примерами множеств данных могут служить телефонные справочники, оглавления в книгах, списки книг в библиотеках, списки сотрудников организаций и т. д. Вот пример описания типа для информации о некоторой книге в библиотеке:
type Книга = record
Автор: string;
Название: string;
ГодИздания: word;
Тема: (Математика, Биология, ОБЖ);
Стеллаж: word; {номер стеллажа, где эта книга находится в библиотеке}
Количество: word; {штук в библиотеке}
end;
Здесь можно было бы “более детально” организовать почти все из имеющихся полей данных, например, тип поля Автор сделать таким:
record
Фамилия, Имя, Отчество: string [20];
end;
однако ни здесь, ни ниже мы не будем заниматься подобной детализацией.
Из таких записей на Паскале может быть создана база данных, например, для описанного в ыш е типа Книга:
array [1..N] of Книга;
для некоторой (достаточно большой) константы N, или
file of Книга;
Все поля в приведённом примере можно заменить на другие, удалить, записать новые и т. п. – для дальнейшего конкретный тип используемых данных несущественен.
Когда имеется много данных описанного типа, практически всегда удобно работать с отсортированными данными. Отметим, что для разных задач может потребоваться сортировка по разным полям. Например, для массива (или файла) данных – элементов типа Книга могут потребоваться такие виды сортировки:
– по отношению «меньше» - по одному из полей ГодИздания, Стеллаж или Количество,
– алфавитное - по одному из полей Автор или Название
В любом случае можно считать, что имеется некоторое отношение порядка, и именно по этому отношению производятся сортировка и поиск в отсортированном массиве (файле) данных.
Всюду ниже будем для упрощения записи сортировать массивы (файлы) по отношению “меньше” для типа word, и поиск в уже отсортированном массиве проводить также для этого отношения. Таким образом, «не ограничивая общности рассуждений», в дальнейшем можно будет работать только с данными следующего типа:
type Элемент = record
Ключ: word;
Информация: ТипИнформации;
end;
Здесь Ключ – поле, по которому ведётся сортировка (поиск), а тип ТипИнформации – абстракция для всех остальных полей типа. Например, для типа Книга вместо поля Ключ может быть применено поле ГодИздания, а поле Информация в этом случае обозначает совокупность полей Автор, Название, Тема, Стеллаж и Количество. Подробнее ТипИнформации конкретизировать не будем – приведённые далее программы работают с различными типами данных. Иногда будем называть элемент массива по его ключу (т. е. если Ключ=51, то будем говорить “элемент 51”).
Выше были описаны четыре возможные задачи – задачи сортировки и поиска для массивов и файлов данных. При этом имеются в виду последовательные файлы (что подчёркивается употреблением записи file of): действительно, задачи сортировки (поиска) для файлов прямого доступа аналогичны соответствующим задачам для массивов. Задача поиска для последовательных файлов тривиальна: никаких других алгоритмов, кроме последовательного просмотра всех элементов файла, придумать невозможно. Таким образом, из четырёх задач остаются три. Ниже (т.е. в данной части 1) будут рассмотрены две из них – обе задачи для массивов, они значительно проще задачи сортировки файлов, которая будет рассмотрена в одной из следующих частей.
Далее в обеих задачах про массивы мы не будем использовать никаких дополнительных структур данных (например, вспомогательных массивов), кроме, возможно, нескольких переменных простых типов - word, boolean и т.п., а также одной переменной описанного выше типа Элемент (эта переменная будет использоваться для обмена двух элементов массива). При этом, однако, алгоритмы сортировки вовсе не усложняются - т.е. они не сложнее тех алгоритмов, которые можно было бы создать, применяя вспомогательные массивы. А сложность алгоритмов - т.е. различные способы оценки их эффективности - будет рассмотрена в следующем разделе.
О способах оценки сложности (эффективности) алгоритмов
Определения сложности или эффективности алгоритмов, приводимые в разных монографиях ([5, 9, 15] и др.), весьма отличаются друг от друга, поэтому имеет смысл говорить не о строгом определении эффективности, а о различных подходах к её определению. А при необходимости в каждом конкретном случае один из подходов можно будет “развить” до строгого математического определения. Ниже приведены альтернативные варианты таких подходов. Альтернативы обозначены буквами (A,B,C,D) с нижними индексами, т.е. например, можно создать строгое определение на основе приведённых ниже альтернатив A2, B1,2, C2 и D1. Но в любом случае эффективность - некоторая функция, зависящая от размерности задачи (эта функция обычно является возрастающей)[1] Пока будем считать размерность зафиксированной.
Во-первых, исследование эффективности можно проводить:
(A1) аналитическое;
(A2) статистическое, на основе специальных тестов. Большинство дальнейших примеров этого раздела основаны на статистической оценке (при этом примеры более наглядны, кроме того, аналитическое исследование не всегда возможно). В следующих разделах, наоборот, будем оценивать эффективность аналитически, однако несколько различных программ для статистических оценок читателям всё же полезно написать самостоятельно.
Во-вторых, измерять эффективность можно:
(B1) по времени;
(B2) по объёму занимаемой памяти.
По-видимому, временная оценка эффективности алгоритмов на практике требуется значительно чаще, поэтому ниже в настоящем пособии будем рассматривать именно её.
В [5] можно найти таблицу зависимости максимальной размерности задачи, выполняемой за единицу времени (секунду, минуту, час), от временной сложности алгоритма (n, n2, n [2] , 2n или nlogn), а также таблицу возможного увеличения максимальной размерности при использовании более быстрого вычислительного устройства. При желании такие таблицы легко построить самостоятельно.
Имеются различные подхо ды к «единицам измерения» временной эффективности. В первом подходе для этого выбираются «обычные» временные единицы (например, миллисекунды), и для программы, соответствующей рассматриваемому алгоритму, измеряется время работы. Недостатки такого подхода следующие. Во-первых, имеется очень большая зависимость от качественного программирования, т.е. от эффективности реализации алгоритма. Во-вторых, даже при оптимальных (или близких к ней) реализациях эффективность зависит от применяемых компьютеров: сравнительные результаты работы двух разных алгоритмов могут сильно отличаться на компьютерах различных типов.
(B1,2) Попробуем избавиться от всех отмеченных недостатков предыдущего подхода, выбирая характерные для нескольких однотипных алгоритмов операции и подсчитывается число применений каждой из них (ср. измерение длины удава «в попугаях»)[3]. Различные способы подсчёта числа применений некоторой операции будут описаны ниже.
И у этого подхода легко заметить недостаток: где гарантия, что нами действительно были выбраны «самые важные» операции? Ведь во время работы алгоритма выполняются и другие операции, и, может быть, время выполнения остальных операций сравнимо со временем выполнения выбранных.
Итак, вряд ли может существовать оптимальный во всех отношениях способ измерения времени выполнения алгоритмов, – конкретный критерий приходится выбирать в каждой задаче свой.
Для любого из отмеченных способов оценки времени можно измерять:
(C1) усреднённую;
(C2) худшую
эффективность для нескольких измерений. (Далее будем говорить «эффективность в среднем» и «в худшем».) При этом могут быть получены разные сравнительные результаты, один из подобных примеров имеется и в настоящем пособии - см. раздел 5.
Какие же случаи нужно рассматривать для выбора худшего из них или усреднения получаемой эффективности? Здесь тоже имеются по крайней мере два подхода:
(D1) случайным образом генерируются несколько различных вариантов входных данных;
(D2) Рассматриваются (или с помощью некоторой комбинаторной процедуры генерируются) все принципиально различные возможные входы. [4] Однако очевидно, что из-за «комбинаторного взрыва» такой способ можно применять только для очень малых размерностей задачи.
Сравнительная эффективность каких-либо двух алгоритмов часто зависит и от размерности задачи, которую мы пока считали зафиксированной. Так, при достаточно малых размерностях обычно лучше работают простые алгоритмы, а при больших размерностях – более сложные, не сразу очевидные алгоритмы. Иллюстрирующие примеры можно легко получить на основе алгоритмов из настоящего пособия[5]. Вследствие этого факта часто говорят о предельной эффективности алгоритма как некоторой функции f (n) - в случае, если предел
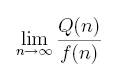
существует и отличен от 0 и ∞ (здесь n - размерность, а Q(n) - эффективность рассматриваемого алгоритма). Или в других обозначениях: Q(n)=O(f (n)).
В заключение отметим, что далее в настоящем пособии будет применяться то определение эффективности алгоритмов, которое может быть записано на основе следующих альтернатив: A 1, B 1,2, C2 и D2.