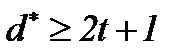Основной задачей теории кодирования в настоящее время является повышение надежности систем связи и вычислительных систем с помощью эффективного введения избыточности в процессе представления информации.
Различают три типа помехоустойчивых кодов: с обнаружением ошибок; с исправлением ошибок; с обнаружением и исправлением ошибок.
Принцип построения помехоустойчивых кодов заключается в том, что все возможные кодовые комбинации N делятся на две группы: разрешенные Nи (предназначенные для передачи полезной информации) и запрещенные Nк (для передачи информации, используемой для целей контроля).
Разрешенные и запрещенные кодовые комбинации подбираются таким образом, чтобы в результате действия любой помехи разрешенные комбинации перешли в запрещенные. Тогда на приемной стороне факт наличия ошибок всегда будет обнаружен.
Для синтеза помехоустойчивого кода необходимо определить: n - длину кодового слова (разрядность кода); кодовое расстояние d; минимально необходимое число контрольных символов nк и их значения; необходимое для передачи заданного множества сообщений число информационных символов nи; число и порядок проверок принятого сообщения.
Сначала определяется число информационных символов nи, затем - nк. Определяется оно на основании множества передаваемых сообщений 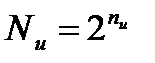 . (12.1)
. (12.1)
Из nк контрольных символов можно образовать 2 в степени nк двоичных комбинаций, которые должны дать ответы типа "да" или "нет" на вопросы: Принято ли данное кодовое слово правильно? Если в нем имеется ошибка, то на какой из n позиций, включая и контрольные? (Для этого надо задать n вопросов.)
 двоичных комбинаций должны дать ответы не менее, чем на n + 1 вопрос, т.е.
двоичных комбинаций должны дать ответы не менее, чем на n + 1 вопрос, т.е.  (12.2)
(12.2)
Поскольку n = nи + nк, 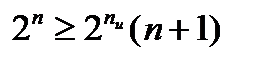 (12.3) или
(12.3) или  (12.4)
(12.4)
Код с проверкой на четность. Непомехоустойчивый код не имеет избыточности (n = nи и l =0) и все символы информационные. Кодовое расстояние d у такого кода равно 1 и он не в состоянии не только корректировать, но и обнаруживать ошибки.
Если контрольные символы составить по принципу: если в кодовом слове исходного кода число единиц нечетное, контрольный символ должен дополнять его до четного. В результате получится помехоустойчивый код с кодовым расстоянием d =2. Такой код может обнаруживать одну ошибку. Помехоустойчивость кода приобретена ценой избыточности. Результирующий код имеет избыточность
l = (n - nи) / n = 1 - nи/n =1 - 3/4 = 0,25. Такой код называют кодом с проверкой на четность (подобным же образом может быть организован код с проверкой на нечетность).
Смысл обнаружения ошибки состоит в том, что на приемной стороне производится контроль принятой комбинации на четное число единиц. Если в ней число единиц оказывается нечетным, то она "бракуется", так как в кодовой комбинации имела место ошибка.
Блоковые коды. Рассмотрим основные понятия блоковых кодов.
Двоичный код мощности «М» и длины «n» представляет собой множество из «М» двоичных слов длины «n», называемых кодовыми словами. Обычно 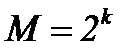 , где
, где 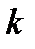 - некоторое целое число, такой код называется двоичным
- некоторое целое число, такой код называется двоичным 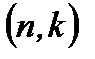 - кодом. Данный код можно использовать для представления 2-битовых двоичных чисел.
- кодом. Данный код можно использовать для представления 2-битовых двоичных чисел.
Если произошла ошибка, то мы получим 5-е битовое слово, отличающееся от кодовых слов. Тогда попытаемся найти наиболее вероятно переданное слово и возьмем его в качестве оценки исходных двух битов информации.
В общем случае блоковые коды определяются над произвольным конечным алфавитом из q символов {0, 1, 2,..., q-l}. Блоковый код мощности М над алфавитом из q символов определяется как множество из М q-ичных последовательностей длины n, называемых кодовыми словами. Если q=2, то символы называются битами.
О блоковом коде судят по трем параметрам: длине блока n; информационной длине k, минимальному расстоянию d* (расстояние Хемминга). Минимальное расстояние является мерой различия двух наиболее похожих кодовых слов.
Расстоянием по Хеммингу между двумя q-ичиыми последовательностями X и Y длины п называется число позиций, в которых они различны. Это расстояние обозначается через d(x,y).
Пусть  - код. Тогда минимальное расстояние кода G равно наименьшему из всех расстояний по Хеммингу между различными парами кодовых слов., т.е.
- код. Тогда минимальное расстояние кода G равно наименьшему из всех расстояний по Хеммингу между различными парами кодовых слов., т.е.

(n, k) - код с минимальным расстоянием d* называется также (n, k, d*) - кодом.
Если произошло t ошибок и если расстояние от принятого слова до каждого другого кодового слова больше t то декодер исправит эти ошибки, приняв ближайшее к принятому кодовое слово в качестве действительно переданного. Это всегда будет так, если