8. Случайная величина и выборка ее значений. Выборочные числовые характеристики среднее значение, исправленная дисперсия, выборочное среднее квадратическое отклонение (стандартное отклонение). Мода, медиана, асимметрия и эксцесс.
Случайной величиной называют функцию от элементарного события.
Случайной выборкой1 или просто выборкой1 объема n называется набор некоторого числа элементов генеральной совокупности, наблюденных при серии из n одинаковых экспериментов
Выборкой2 объема n называется набор 1,…,n случайных величин, определенных на натуральных числах 1,…,n, k-я с.в. принимает значение исхода ki-го эксперимента на числе i, при условии, что все эксперименты одинаковы.
Выборочные числовые характеристики среднее значение:
Пусть выборка объема n из генеральной совокупности с функцией распределения.
Рассмотрим выборочное распределение, т.е. распределение дискретной СВ, принимающей эти значения с вероятностями, равными. Соответственно числовые характеристики этого выборочного распределения называют выборочными (эмпирическими) числовыми характеристиками.
Замечание.
Выборочные числовые характеристики являются характеристиками данной выборки, но не являются характеристиками распределения генеральной совокупности.
“~” - при обозначении этих числовых характеристик.
- унимодального, т.е. одновершинного распределения называется элемент выборки, встречающийся с наибольшей частотой.
Выборочной медианой называется, которое делит вариационный ряд на две части, содержащие равное число элементов.
Если n - нечетное число, т.е. n = 2/+1, то.
Если n - четное число, т.е. n = 2/, то.
Можно доказать, что выборочные начальные и центральные моменты порядка s для негруппированных выборок объема и определяются по следующим формулам
Форма распределения СВ характеризуется выборочными коэффициентами асимметрии и эксцесса.
исправленная дисперсия: – называется число
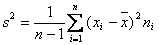
Объясняется это тем, что выборочная дисперсия является смещённой оценкой, тогда как исправленная нет.
выборочное среднее квадратическое отклонение (стандартное отклонение):
— неотрицательное значение корня квадратного из дисперсии случайной величины, которое часто обозначают через а. С. о. есть характеристика рассеяния той же размерности, что и сама случайная величина. Выборочное С. о. есть 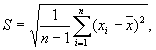 где xi,…,xп— выборка объема n,
где xi,…,xп— выборка объема n, 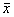 — выборочное среднее. С. о. используется весьма широко, является характеристикой устойчивости исследуемой случайной величины.
— выборочное среднее. С. о. используется весьма широко, является характеристикой устойчивости исследуемой случайной величины.
Мода, медиана, асимметрия и эксцесс:
Мода – величина признака, которая чаще всего встречается в данной совокупности. Применительно к вариационному ряду модой является наиболее часто встречающееся значение ранжированного ряда. Она показывает размер признака, свойственный значи–тельной части совокупности, и определяется по фор–муле:
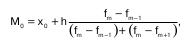
где х0 – нижняя граница интервала;
h – величина интервала;
f m – частота интервала;
f m-1 – частота предшествующего интервала;
f m+1 – частота следующего интервала.
Медианой называется вариант, расположенный в центре ранжированного ряда. Медиана делит ряд на две равные части таким образом, что по обе стороны от нее находится одинаковое количество единиц со–вокупности. При этом у одной половины единиц сово–купности значение варьирующего признака меньше ме–дианы, у другой – больше.
Описательный характер медианы проявляется в том, что она характеризует количественную границу значений варьирующего признака, которыми облада–ет половина единиц совокупности.
При определении медианы в интервальных ва–риационных рядах сначала определяется интервал, в котором она находится (медианный интервал). Этот интервал характерен тем, что его накопленная сумма частот равна или превышает полусумму всех ча–стот ряда. Расчет медианы интервального ва–риационного ряда производится по формуле:
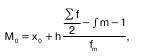
где х0 – нижняя граница интервала;
h – величина интервала;
f m – частота интервала;
f – число членов ряда;
? m- 1 – сумма накопленных членов ряда, предше–ствующих данному.
Наряду с медианой для более полной характери–стики структуры изучаемой совокупности применяют и другие значения вариантов, занимающих в ранжи–рованном ряду вполне определенное положение. К ним относятся квартили и децили. Квартили делят ряд по сумме частот на четыре равные части, а деци-ли – на десять равных частей. Квартилей насчитыва–ется три, а децилей – девять.
Медиана и мода в отличие от средней арифмети–ческой не погашают индивидуальных различий в зна–чениях варьирующего признака и поэтому являются дополнительными и очень важными характеристика–ми статистической совокупности. На практике они ча–сто используются вместо средней либо наряду с ней. Особенно целесообразно вычислять медиану и моду в тех случаях, когда изучаемая совокупность содер–жит некоторое количество единиц с очень большим или очень малым значением варьирующего признака.
Вычисление асимметрии и эксцесса позволяет установить симметричность распределения случайной величины 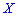 относительно
относительно 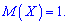 Для этого находят третий центральный момент, характеризующий асимметрию закона распределения случайной величины. Если он равен нулю
Для этого находят третий центральный момент, характеризующий асимметрию закона распределения случайной величины. Если он равен нулю 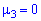 , то случайная величина симметрично распределена относительно математического ожидания
, то случайная величина симметрично распределена относительно математического ожидания 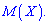 Поскольку
Поскольку 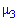 имеет размерность случайной величины в кубе, то вводят безразмерную величину — коэффициент асимметрии:
имеет размерность случайной величины в кубе, то вводят безразмерную величину — коэффициент асимметрии:
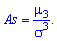
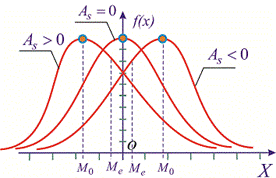
Центральный момент четвертого порядка используется для определения эксцесса, характеризует плосковершиннисть или гостровершиннисть плотности вероятности 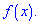 Эксцесс вычисляется по формуле
Эксцесс вычисляется по формуле
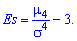
Число 3 вычитается для сравнения отклонения от центрального закона распределения (нормального закона), для которого подтверждается равенство:
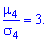
Итак,  для нормального закона распределения. Если эксцесс положительный
для нормального закона распределения. Если эксцесс положительный 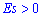 то на графике функция распределения остро вершину и для отрицательных значений
то на графике функция распределения остро вершину и для отрицательных значений 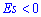 более пологую. Таким образом можно установить отклонения заданного закона от нормального. Для наглядности при различных значениях асимметрии и эксцесса графики плотности вероятностей
более пологую. Таким образом можно установить отклонения заданного закона от нормального. Для наглядности при различных значениях асимметрии и эксцесса графики плотности вероятностей 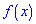 изображены на рисунках ниже
изображены на рисунках ниже
9. Построение интервального ряда для большой выборки, полигон и гистограмма, выборочные точечные оценки числовых характеристик случайной величины на примерах равномерного или нормального распределения.
На первом этапе статистической обработки экспериментальных данных производят ранжирование выборки, т.е. упорядочивание чисел (вариантов) x1, x2, …, xn по возрастанию. При этом частота варианта mi показывает сколько раз i-вариант встречается в выборке, а относительная частота (частость) wi - отношение частоты данного варианта к общей сумме частот всех вариантов (объему выборки).
Признак называется дискретно варьируемым, если его варианты отличаются друг от друга на некоторую конечную величину (обычно целое число). Вариационный ряд такого признака называется дискретным вариационным рядом.Признак называется непрерывно варьирующим, если его значения отличаются друг от друга на сколь угодно малую величину, т.е. признак может принимать любые значения в некотором интервале. Непрерывный вариационный ряд такого признака называется интервальнымросматривая результаты проведенных наблюдений, определяют, сколько значений вариантов попало в каждый конкретный интервал. Предполагается, что каждому интервалу принадлежит один из его концов: либо во всех случаях левые (чаще), либо во всех случаях правые, а частоты или частости показывают число вариантов, заключенных в указанных границах. Разности () называются частичными интервалами или интервальными разностями.
Для того чтобы интервальный вариационный ряд не был громоздким и в то же время позволял выявить характерные черты изменения значений случайной величины, обычно число частичных интервалов выбирают от 7 до 10. Длина частичного интервала (интервальная разность) зависит от размаха варьирования и выбранного числа интервалов:
Если окажется, что h – дробное число, то за длину частичного интервала следует брать либо ближайшее целое число, либо ближайшую простую дробь.
Полигон чаще всего используют для изображения дискретных рядов. Полигоном частот называют ломаную, отрезки которой соединяют точки с координатами (), где - варианты выборки и - соответствующие им частоты. Если полигон строят по данным интервального ряда, то в качестве абсцисс точек берут середины соответствующих интервалов.
Для построения полигона в прямоугольной системе координат в произвольно выбранном масштабе на оси абсцисс откладывают значения аргумента (варианты), а на оси ординат – значения частот. Масштаб выбирают такой, чтобы была обеспечена необходимая наглядность и желательный размер рисунка. Далее строят точки с координатами () и последовательно соединяют их отрезками прямой.
Полигоном относительных частот (частостей) называют ломаную, отрезки которой соединяют точки с координатами (), где - варианты выборки и - соответствующие им относительные частоты.
Гистограмму используют для изображения только интервальных рядов. Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длины h, а высоты равны отношению (плотность частоты). Площадь частичного i -го прямоугольника равна - сумме частот вариант, попавших в i -ый интервал. Площадь гистограммы частот равна сумме всех частот, т.е. объему выборки n.
Если соединить середины верхних оснований прямоугольников отрезками прямой, то можно получить полигон того же распределения, который будет являться выборочным аналогом дифференциальной функции распределения.
Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длины h, а высоты равны отношению (плотность относительной частоты). Площадь частичного i -го прямоугольника равна - сумме относительных частот вариант, попавших в i -ый интервал. Площадь гистограммы относительных частот равна сумме всех относительных частот, т.е. единице.
Точечные оценки
Определение. Точечной оценкой называют некоторую функцию результатов наблюдений, значение которой принимают за наилучшее приближение в данных условиях к значению параметра генеральной совокупности Х.
Поскольку - случайные величины, то и оценка (в отличие от оцениваемого параметра - величины неслучайной, детерминированной) является случайной величиной, зависящей от закона распределения случайной величины Х и числа наблюдений n.
Наиболее важными числовыми характеристиками случайной величины являются математическое ожидание и дисперсия, несколько реже используются начальные и центральные моменты.
10. Интервальные оценки числовых характеристик. Доверительная вероятность и доверительный интервал. Точность и надёжность оценки.
Интервал значений случайной величины, внутри которого с заданной вероятностью находится истинное значение погрешности результата измерения, называется доверительным интервалом погрешности результата измерения, а соответствующую ему вероятность - доверительной вероятностью Р.
Нижнюю и верхнюю границы доверительного интервала называют доверительными границами.
Доверительный интервал характеризует степень воспроизводимости результатов измерения.
Как следует из определения, для характеристики случайной погрешности необходимо иметь две характеризующие ее величины - доверительный интервал и доверительную вероятность.
Доверительным интервалом для выборки с распределением p(x, q) называется такой отрезок, что q принимает значение из этого отрезка с вероятностью 1-a, называемой доверительной вероятностью.
После получения точечной оценки θ* желательно иметь данные о надежности такой оценки. Особенно важно иметь сведения о точности оценок для небольших выборок (поскольку с возрастанием объема п выборки несмещенность и состоятельность основных оценок гарантируется утверждениями математической статистики). Поэтому точечная оценка может быть дополнена интервальной оценкой — интервалом (θ1, θ 2), внутри которого с наперед заданной вероятностью γ находится точное значение оцениваемого параметра θ. Задачу определения такого интервала называют интервальным оцениванием, а сам интервал — доверительным интервалом. При этом γ называют доверительной вероятностью или надежностью, с которой оцениваемый параметр θ попадает в интервал (θ 1, θ 2).
Зачастую для определения доверительного интервала заранее выбирают число α = 1 — γ, 0< α < 1, называемое уровнем значимости, и находят два числа θ 1 и θ 2, зависящих от точечной оценки θ*, такие, что
Р(θ 1< θ < θ 2) = 1- α = γ. (1)
В этом случае говорят, что интервал (θ 1, θ 2) накрывает неизвестный параметр θ с вероятностью (1 - α), или в 100(1 - α)% случаев. Границы интервала θ 1 и θ 2 называются доверительными, и они обычно находятся из условия Р(θ < θ 1) = Р(θ > θ 2) = α/2 (рис. 1) [2].
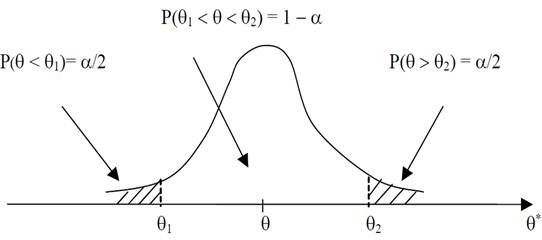
Рисунок 1 – Распределение параметра θ
Длина доверительного интервала, характеризующая точность интервальной оценки, зависит от объема выборки п и надежности γ (уровня значимости γ= 1 - α). При увеличении величины п длина доверительного интервала уменьшается, а с приближением надежности γ к единице — увеличивается. Выбор α (или γ = 1 - α) определяется конкретными условиями. Обычно используется α=0,1; 0,05; 0,01, что соответствует 90, 95, 99%-м доверительным интервалам.
Общая схема построения доверительного интервала:
1. Из генеральной совокупности с известным распределением f(x, θ) случайной величины X извлекается выборка объема п, по которой находится точечная оценка θ * параметра θ.
2. Строится случайная величина Y(θ), связанная с параметром θ и имеющая известную плотность вероятности f(у, θ).
3. Задается уровень значимости α.
4. Используя плотность вероятности случайной величины Y, определяют два числа с1 и с2 такие, что
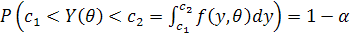 . (2)
. (2)
Значения с1 и с2 выбираются как правило, из условий
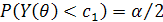 ;
; 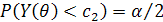 .
.
Неравенство с1 < Y(θ) < с2 преобразуется в равносильное θ*- δ < θ < θ + δ такое, что Р (θ*- δ < θ < θ*+ δ) = 1 – α [1].
Полученный интервал (θ *- δ < θ < θ *+ δ), накрывающий неизвестный параметр θ с вероятностью 1 - α, и является интервальной оценкой параметра θ.
Интервальная оценка также носит случайный характер, так как она напрямую связана с результатами выборки. Однако она позволяет сделать следующий вывод. Если построен доверительный интервал, который с надежностью γ = 1 - α накрывает неизвестный параметр, и его границы рассчитываются по К выборкам одинакового объема п, то в (1-α)К случаях построенные интервалы накроют истинное значение исследуемого параметра.
Поскольку в эконометрических задачах часто приходится находить доверительные интервалы параметров случайных величин, имеющих нормальное распределение, приведем схемы их определения.
11. Доверительные интервалы для оценки математического ожидания нормального распределения по критерию Стьюдента. Доверительные интервалы для оценки
среднеквадратического отклонения нормального распределения по q значениям.
Доверительным интервалом для выборки с распределением p(x, q) называется такой отрезок, что q принимает значение из этого отрезка с вероятностью 1-a, называемой доверительной вероятностью.
Доверительный интервал — это интервал, построенный с помощью случайной выборки из распределения с неизвестным параметром, такой, что он содержит данный параметр с заданной вероятностью.
Пусть  - выборка из некоторого распределения с плотностью
- выборка из некоторого распределения с плотностью 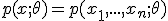 , зависящей от параметра
, зависящей от параметра 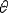 , который может изменяться в интервале
, который может изменяться в интервале 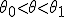 . Пусть
. Пусть 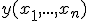 - некоторая статистика и
- некоторая статистика и 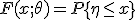 - функция распределения случайной величины
- функция распределения случайной величины 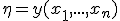 , когда выборка имеет распределение с плотностью
, когда выборка имеет распределение с плотностью 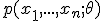 . Предположим, что
. Предположим, что 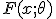 есть убывающая функция от параметра . Обозначим
есть убывающая функция от параметра . Обозначим  квантиль распределения , тогда есть возрастающая функция от . Зафиксируем близкое к нулю положительное число
квантиль распределения , тогда есть возрастающая функция от . Зафиксируем близкое к нулю положительное число 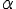 (например, 0,05 или 0,01). Пусть
(например, 0,05 или 0,01). Пусть 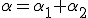 . При каждом неравенства
. При каждом неравенства
(1)
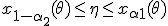
выполняются с вероятностью 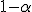 , близкой к единице. Перепишем неравенства (1) в другом виде:
, близкой к единице. Перепишем неравенства (1) в другом виде:
(2)
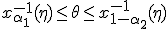
Обозначим 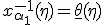 ,
, 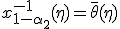 и запишем (2) в следующем виде:
и запишем (2) в следующем виде:
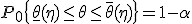
Интервал 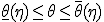 называется доверительным интервалом для параметра , а вероятность - доверительной вероятностью.
называется доверительным интервалом для параметра , а вероятность - доверительной вероятностью.
t-критерий Стьюдента — общее название для класса методов статистической проверки гипотез (статистических критериев), основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках.
t -статистика строится обычно по следующему общему принципу: в числителе случайная величина с нулевым математическим ожиданием (при выполнении нулевой гипотезы), а в знаменателе — выборочное стандартное отклонение этой случайной величины, получаемое как квадратный корень из несмещенной оценки дисперсии.
ля применения данного критерия необходимо, чтобы исходные данные имели нормальное распределение. В случае применения двухвыборочного критерия для независимых выбороктакже необходимо соблюдение условия равенства дисперсий. Существуют, однако, альтернативы критерию Стьюдента для ситуации с неравными дисперсиями.
Требование нормальности распределения данных является необходимым для точного 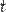 -теста. Однако, даже при других распределениях данных возможно использование -статистики. Во многих случаях эта статистика асимптотически имеет стандартное нормальное распределение —
-теста. Однако, даже при других распределениях данных возможно использование -статистики. Во многих случаях эта статистика асимптотически имеет стандартное нормальное распределение — 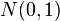 , поэтому можно использовать квантили этого распределения. Однако, часто даже в этом случае используют квантили не стандартного нормального распределения, а соответствующего распределения Стьюдента, как в точном -тесте. Асимптотически они эквивалентны, однако на малых выборках доверительные интервалы распределения Стьюдента шире и надежнее.
, поэтому можно использовать квантили этого распределения. Однако, часто даже в этом случае используют квантили не стандартного нормального распределения, а соответствующего распределения Стьюдента, как в точном -тесте. Асимптотически они эквивалентны, однако на малых выборках доверительные интервалы распределения Стьюдента шире и надежнее.
Кроме того, для случая нормального распределения мы можем пользоваться следующими формулами:
С вероятностью 95%
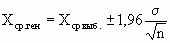
С вероятностью 99%
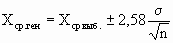
В общем виде c вероятностью Р(t)
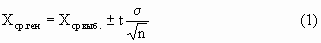
Связь значения t со значением вероятности Р(t), с которой мы хотим знать доверительный интервал, можно взять из следующей таблицы:

Таким образом, мы определили, в каком диапазоне находится среднее значение для генеральной совокупности (с данной вероятностью).
Если у нас нет достаточно большой выборки, мы не можем утверждать, что генеральная совокупность имеет s = Sвыб. Кроме того, в этом случае проблематична близость выборки к нормальному распределению. В этом случае также пользуются Sвыб вместо s в формуле:

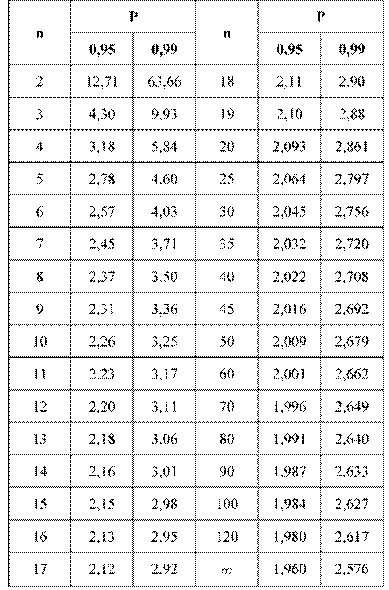
но значение t для фиксированной вероятности Р(t) будет зависеть от количества элементов в выборке n. Чем больше n, тем ближе будет полученный доверительный интервал к значению, даваемому формулой (1). Значения t в этом случае берутся из другой таблицы (t-критерий Стьюдента), которую мы приводим ниже:
Значения t-критерия Стьюдента для вероятности 0,95 и 0,99
12. Статистическая проверка статистических гипотез. Нулевая и конкурирующая гипотезы. Ошибки первого и второго рода. Уровень значимости и критическая область. Основной принцип проверки статистических гипотез.
Статистическая проверка гипотез
система приёмов в математической статистике предназначенных для проверки соответствия опытных данных некоторой статистической гипотезе. Процедуры С. п. г. позволяют принимать или отвергать статистические гипотезы, возникающие при обработке или интерпретации результатов измерений во многих практически важных разделах науки и производства, связанных с экспериментом. Правило, по которому принимается или отклоняется данная гипотеза, называется статистическим критерием. Построение критерия определяется выбором подходящей функции Т от результатов наблюдений, которая служит мерой расхождения между опытными и гипотетическими значениями. Эта функция, являющаяся случайной величиной, называется статистикой критерия, при этом предполагается, что распределение вероятностей Т может быть вычислено при допущении, что проверяемая гипотеза верна. По распределению статистики Т находится значение Т0, такое, что если гипотеза верна, то вероятность неравенства T > T0 равна α, где α — заранее заданный Значимости уровень. Если в конкретном случае обнаружится, что Т > T0, то гипотеза отвергается, тогда как появление значения Т ≤ T0 не противоречит гипотезе. Пусть, например, требуется проверить гипотезу о том, что независимые результаты наблюдений x1,..., xn подчиняются нормальному распределению) со средним значением а = a0 и известной дисперсией σ 2. При этом предположении среднее арифметическое  а = a0 и дисперсией σ2/n, а величина
а = a0 и дисперсией σ2/n, а величина 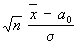 T0 и α по таблицам нормального распределения. Например, при гипотезе а = a0 событие Т > 1, 96 имеет вероятность а = 0,05. Правило, рекомендующее считать, что гипотеза а = a0 неверна, если Т > 1,96, будет приводить к ложному отбрасыванию этой гипотезы в среднем в 5 случаях из 100, в которых она верна. Если же Т ≤ 1,96, то это ещё не означает, что гипотеза подтверждается, т.к. указанное неравенство с большой вероятностью может выполняться при а, близких к a0. Следовательно, при использовании предложенного критерия можно лишь утверждать, что результаты наблюдений не противоречат гипотезе а = a0. При выборе статистики Т всегда явно или неявно учитывают гипотезы, конкурирующие с гипотезой а = a0. Например, если заранее известно, что а ≥ a0, т. е. отклонение гипотезы а = a0 влечёт принятие гипотезы а > a0, то вместо Т следует взять
T0 и α по таблицам нормального распределения. Например, при гипотезе а = a0 событие Т > 1, 96 имеет вероятность а = 0,05. Правило, рекомендующее считать, что гипотеза а = a0 неверна, если Т > 1,96, будет приводить к ложному отбрасыванию этой гипотезы в среднем в 5 случаях из 100, в которых она верна. Если же Т ≤ 1,96, то это ещё не означает, что гипотеза подтверждается, т.к. указанное неравенство с большой вероятностью может выполняться при а, близких к a0. Следовательно, при использовании предложенного критерия можно лишь утверждать, что результаты наблюдений не противоречат гипотезе а = a0. При выборе статистики Т всегда явно или неявно учитывают гипотезы, конкурирующие с гипотезой а = a0. Например, если заранее известно, что а ≥ a0, т. е. отклонение гипотезы а = a0 влечёт принятие гипотезы а > a0, то вместо Т следует взять 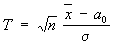 2 неизвестна, то вместо данного критерия для проверки гипотезы а = a0 можно воспользоваться т. н. критерием Стьюдента, основанным на статистике <="" div="" style="border-style: none;">
2 неизвестна, то вместо данного критерия для проверки гипотезы а = a0 можно воспользоваться т. н. критерием Стьюдента, основанным на статистике <="" div="" style="border-style: none;">
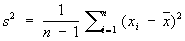
и подчинена Стьюдента распределению с n — 1 степенями свободы. Такого рода критерии называются критериями согласия и используются как для проверки гипотез о параметрах распределения, так и гипотез о самих распределениях.При решении вопроса о принятии или отклонении какой-либо гипотезы H0 с помощью любого критерия, основанного на результатах наблюдения, могут быть допущены ошибки двух типов. Ошибка «первого рода» совершается тогда, когда отвергается верная гипотеза H0. Ошибка «второго рода» совершается в том случае, когда гипотеза H0 принимается, а на самом деле верна не она, а какая-либо альтернативная гипотеза Н. Естественно требовать, чтобы критерий для проверки данной гипотезы приводил возможно реже к ошибочным решениям. Обычная процедура построения наилучшего критерия для простой гипотезы заключается в выборе среди всех критериев с заданным уровнем значимости и (вероятность ошибки первого рода) такого, который приводил бы к наименьшей вероятности ошибки второго рода (или, что то же самое, к наибольшей вероятности отклонения гипотезы, когда она неверна). Последняя вероятность (дополняющая до единицы вероятность ошибки второго рода) называется мощностью критерия. В случае, когда альтернативная гипотеза Н простая, наилучшим будет критерий, который имеет наибольшую мощность среди всех других критериев с заданным уровнем значимости а (наиболее мощный критерий). Если альтернативная гипотеза Н сложная, например зависит от параметра, то мощность критерия будет функцией, определенной на классе простых альтернатив, составляющих Н, т. е. будет функциейпараметра. Критерий, имеющий наибольшую мощность при каждой альтернативной гипотезе из класса Н, называется равномерно наиболее мощным, однако следует отметить, что такой критерий существует лишь в немногих специальных ситуациях. В задаче проверки гипотезы о среднем значении нормальной совокупности а = а0 против альтернативной гипотезы а > a0равномерно наиболее мощный критерийсуществует, тогда как при проверке той жегипотезы против альтернативы а ≠ a0 его нет. Поэтому часто ограничиваются поиском равномерно наиболее мощных критериев в тех или иных специальных классах (Инвариантных, несмещенных критериев и т.п.).
Теория С. п. г. позволяет с единой точки зрения трактовать выдвигаемые практикой различные задачи математической статистики (оценка различия между средними значениями, проверка гипотезы постоянства дисперсии, проверка гипотезы независимости, проверка гипотез о распределениях и т.п. Идеи последовательного анализа примененные к С. п. г., указывают на возможность связать решение о принятии или отклонении гипотезы с результатами последовательнопроводимых наблюдений (в этом случае число наблюдений, на основе которых по определённому правилу принимается решение, не фиксируется заранее, а определяется в ходе эксперимента)
Нулевая и конкурирующая гипотезы:
Часто необходимо знать закон распределения генеральной совокупности. Если закон распределения неизвестен, но имеются основания предположить, что он имеет определенный вид (назовем его А), выдвигают гипотезу: генеральная совокупность распределена по закону А. Таким образом, в этой гипотезе речь идет о виде предполагаемого распределения.
Возможен случай, когда закон распределения известен, а его параметры неизвестны. Если есть основания предположить, что неизвестный параметр 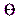 равен определенному значению
равен определенному значению 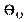 , выдвигают гипотезу:
, выдвигают гипотезу: 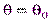 . Таким образом, в этой гипотезе речь идет о предполагаемой величине параметра одного известного распределения.
. Таким образом, в этой гипотезе речь идет о предполагаемой величине параметра одного известного распределения.
Возможны и другие гипотезы: о равенстве параметров двух или нескольких распределений, о независимости выборок и многие другие.
Статистической называют гипотезу о виде неизвестного распределения, или о параметрах известных распределений.
Например, статистическими будут гипотезы:
1) генеральная совокупность распределена по закону Пуассона;
2) дисперсии двух нормальных совокупностей равны между собой.
В первой гипотезе сделано предположение о виде неизвестного распределения, во второй - о параметрах двух известных распределений.
Гипотеза «в 1980 г. не будет войны» не является статистической, поскольку в ней не идет речь ни о виде, ни о параметрах распределения.
Наряду с выдвинутой гипотезой рассматривают и противоречащую ей гипотезу. Если выдвинутая гипотеза будет отвергнута, то имеет место противоречащая гипотеза. По этой причине эти гипотезы целесообразно различать. Нулевой (основной) называют выдвинутую гипотезу 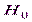 . ^ Конкурирующей (альтернативной) называют гипотезу
. ^ Конкурирующей (альтернативной) называют гипотезу 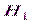 , которая противоречит нулевой.
, которая противоречит нулевой.
Например, если нулевая гипотеза состоит в предположении, что математическое ожидание а нормального распределения равно 10, то конкурирующая гипотеза, в частности, может состоять в предположении, что 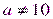 . Коротко это записывают так:
. Коротко это записывают так:
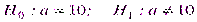
Различают гипотезы, которые содержат только одно и более одного предположений.
Простой называют гипотезу, содержащую только одно предположение. Например, если 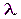 параметр показательного распределения, то гипотеза
параметр показательного распределения, то гипотеза 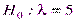 простая. Гипотеза
простая. Гипотеза 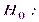 математическое ожидание нормального распределения равно 3 (
математическое ожидание нормального распределения равно 3 (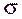 известно) - простая.
известно) - простая.
Сложной называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез. Например, сложная гипотеза 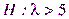 состоит из бесчисленного множества простых вида
состоит из бесчисленного множества простых вида 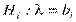 , где
, где 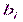 любое число, большее 5. Гипотеза
любое число, большее 5. Гипотеза 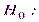 математическое ожидание нормального распределения равно 3 (
математическое ожидание нормального распределения равно 3 (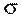 неизвестно) - сложная.
неизвестно) - сложная.
Ошибки первого и второго рода:
При проверке статистических гипотез можно допустить ошибки первого или второго рода
Ошибкой первого рода называется ошибка, состоящая в опровержении верной гипотезы.
Ошибкой второго рода называется ошибка, состоящая в принятии ложной гипотезы.
Уровнем значимости а называется вероятность совершения ошибки первого рода.
Значение уровеня значимости а обычно задаётся близким к нулю (например, 0,05; 0,01;0,02 и т. д.), потому что чем меньше значение уровеня значимости, тем меньше вероятность совершения ошибки первого рода, состоящую в опровержении верной гипотезы Н0.
Вероятность совершения ошибки второго рода, т. е. принятия ложной гипотезы, обозначается ?.
При проверке нулевой гипотезы Н0 возможно возникновение следующих ситуаций:

Уровень значимости и критическая область:
Статистическим критерием называется случайная величина, которая используется с целью проверки нулевой гипотезы.
Статистические критерии называются соответственно тому закону распределения, которому они подчиняются, т. е. F -критерий подчиняется распределению Фишера-Снедекора, ?2 -критерий подчиняется ?2 -распределению, Т -критерий подчиняется распределению Стьюдента, U -критерий подчиняется нормальному распределению.
Наблюдаемым значением статистического критерия называется значение критерия, которое рассчитано по выборочной совокупности, подчиняющейся определённому закону распределения.
Множество всех возможных значений выбранного статистического критерия делится на два непересекающихся подмножества. Первое подмножество включает в себя те значения критерия, при которых основная гипотеза отвергается, а второе подмножество – те значения критерия, при которых основная гипотеза принимается.
Критической областью называется множество возможных значений статистического критерия, при которых основная гипотеза отвергается.
Областью принятия гипотезы или областью допустимых значений называется множество возможных значений статистического критерия, при которых основная гипотеза принимается.
Если наблюдаемое значение статистического критерия, рассчитанное по данным выборочной совокупности, принадлежит критической области, то основная гипотеза отвергается. Если наблюдаемое значение статистического критерия принадлежит области принятия гипотезы, то основная гипотеза принимается.
Критическими точками или квантилями называются точки, разграничивающие критическую область и область принятия гипотезы.
Критические области могут быть как односторонними, так и двусторонними.
Основной принцип проверки статистических гипотез:
Процедура проверки нулевой гипотезы в общем случае включает следующие этапы:
1. задается допустимая вероятность ошибки первого рода (Ркр=0,05)
2. выбирается статистика критерия (Т)
3. ищется область допустимых значений
4. по исходным данным вычисляется значение статистики Т
5. если Т (статистика критерия) принадлежит области принятия нулевой гипотезы, то нулевая гипотеза принимается (корректнее говоря, делается заключение, что исходные данные не противоречат нулевой гипотезе), а в противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза.[1] Это основной принцип проверки всех статистических гипотез.
Обычно первые три этапа выполняют профессиональные математики, а последние два – пользователи для своих частных данных.
В современных статистических пакетах на ЭВМ используются не стандартные уровни значимости, а уровни, подсчитываемые непосредственно в процессе работы с соответст