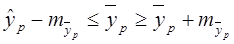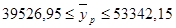ОПИСАНИЕ ЗАДАНИЯ
На основании данных нижеприведенной таблицы построить линейное и степенное уравнения регрессии.
Для построенных уравнений вычислить:
1) коэффициент корреляции;
2) коэффициент детерминации;
3) дисперсионное отношение Фишера;
4) стандартные ошибки коэффициентов регрессии;
5) t — статистики Стьюдента;
6) доверительные границы коэффициентов регрессии;
7) усредненное значение коэффициента эластичности;
8) среднюю ошибку аппроксимации.
На одном графике построить исходные данные и теоретическую прямую.
Дать содержательную интерпретацию коэффициента регрессии построенной модели. Все расчеты провести в Excel с использованием формул и с помощью «Пакета анализа». Результаты, полученные по формулам и с помощью «Пакета анализа», сравнить между собой.
По нижеприведенным данным исследуются данные по среднедневной заработной плате yi, (усл.ед.) и среднедушевому прожиточному минимуму в день одного трудоспособного xi, (усл.ед.):
| Yi | ||||||||||||||
| Xi | ||||||||||||||
| Yi | ||||||||||||||
| Xi | ||||||||||||||
| Yi | ||||||||||||||
| Xi |
а) Выполнить прогноз заработной платы yi при прогнозном значении среднедушевого прожиточного минимума xi, составляющем 117% от среднего уровня.
б) Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
2 ОПИСАНИЕ РЕШЕНИЯ ЛАБОРАТОРНОЙ РАБОТЫ
|
|
Построение линейной регрессионной модели
Линейное уравнение регрессии:
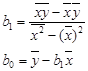
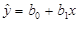
,
где
Чтобы рассчитать значения 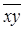 ,
, 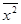 мы добавляем к таблице дополнительные столбцы x*y, х2, рассчитываем их общую сумму по 36 регионам и их среднее значение.
мы добавляем к таблице дополнительные столбцы x*y, х2, рассчитываем их общую сумму по 36 регионам и их среднее значение.
При вычислении b1 и b0 получены результаты:
b1 = 0,991521606,
b0 = 54,33774319
Значит линейное уравнение регрессии примет вид:
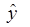 = 54,33774319 + 0,991521606x
= 54,33774319 + 0,991521606x
Индекс b1 = 0,991521606 говорит нам о том, что при увеличении заработную плату на 1 ед. прожиточный минимум увеличивается на 0,991521606.
Зная линейное уравнение регрессии, заполняем соответствующую колонку 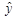 для каждого из регионов. В результате мы можем посчитать общую сумму
для каждого из регионов. В результате мы можем посчитать общую сумму 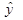 для 36 регионов. Она равна 2320 (усл.ед.). Эта сумма равна общей сумме y для 36 регионов, т.е.
для 36 регионов. Она равна 2320 (усл.ед.). Эта сумма равна общей сумме y для 36 регионов, т.е. 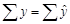 , следовательно, коэффициенты регрессии b1 и b0 рассчитаны, верно.
, следовательно, коэффициенты регрессии b1 и b0 рассчитаны, верно.
1. Рассчитаем коэффициент корреляции:
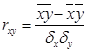 , где
, где 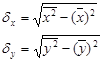
Для этого надо еще добавить в таблицу значения y2 и рассчитать общую сумму по 36 регионам и его среднее значение.
При вычислении 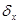 и
и 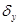 получены результаты:
получены результаты:
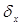 =9,765812498
=9,765812498
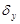 = 93,87081405
= 93,87081405
Следовательно, rxy = 0,103152553. Значит можно сделать вывод, что между х и у, то есть между постоянными расходами и объемом выпускаемой продукции не наблюдается никакой связи.
Рассчитаем коэффициент детерминации:
D = r2xy * 100
D = 1,064044912%
Следовательно, величина постоянных расходов только на 1,064044912% объясняется величиной объема выпускаемой продукции.
2. Рассчитаем дисперсионное отношение Фишера:
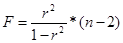 , где n – число регионов
, где n – число регионов
Следовательно, n = 36
F расч = 0,150568403
Найдем Fтабличное: k1 = m, m = 1(т.к. на y влияет только один фактор х),
|
|
k2 = n- m-1. Значит k1 = 1, k2 = 36-1-1= 34. Находим табличное значение F на пересечении k1 и k2. Получаем, что Fтабличное = 2,145.
Так как Fрасчетное < Fтабличное значит уравнение статистически не значимо.
3. Рассчитаем стандартные ошибки коэффициентов регрессии:
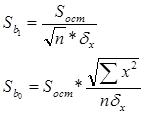
где 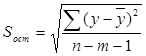
Для этого надо еще добавить в таблицу значения y - 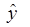 , (y -
, (y - 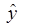 )2, и рассчитать общую сумму по 36 регионам и их среднее значение.
)2, и рассчитать общую сумму по 36 регионам и их среднее значение.
При вычислении Sост было получено, что
Sост = 382,9325409.
Следовательно,
Sb1 = 27,7984546,
Sb0 = 918,3564058
4. Рассчитаем доверительные границы коэффициентов регрессии:
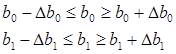 , где
, где 
tтабл находится по таблице t-критерия Стьюдента при уровне значимости 0,05 и числе степенной свободы равной 34.
Значит tтабл =2,145.
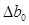 = 1969,87449
= 1969,87449
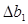 = 59,62768512
= 59,62768512
Следовательно, можно рассчитать доверительные границы коэффициентов регрессии:
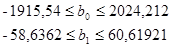
Значит можно сделать вывод, что коэффициенты b1 и b0 значимы, так как они лежат в этих интервалах, то есть модель адекватна.
5. Рассчитаем t — статистики Стьюдента:
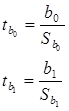
Получается, что 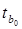 = 0,05916847,
= 0,05916847, 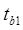 = 0,035668228. Значит коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 не значим, так как меньше tтабл, .
= 0,035668228. Значит коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 не значим, так как меньше tтабл, .
Рассчитаем индекс корреляции:
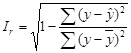
Для этого надо еще добавить в таблицу значения y - 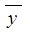 , (y -
, (y - 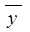 )2, и рассчитать общую сумму по 36 регионам и их среднее значение.
)2, и рассчитать общую сумму по 36 регионам и их среднее значение.
В результате получаем, что Ir =0,103152553=rxy. Следовательно, индекс корреляции и коэффициент корреляции рассчитаны, верно.
6. Рассчитаем значение коэффициента эластичности:
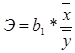
В результате Э = 0,625256944. Коэффициента эластичности показывает, что на 0,625256944% изменится среднедневная заработная плата (у) при изменении на 1% среднедушевой прожиточный минимум(х).
|
|
7. Оценить качество модели можно с помощью коэффициента аппроксимации:
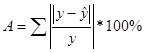
Для этого надо еще добавить в таблицу значения |(y - 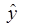 )/y| и рассчитать общую сумму по 36 регионам.
)/y| и рассчитать общую сумму по 36 регионам.
В результате получаем, что А = 3,100451368, следовательно, коэффициент аппроксимации не принадлежит интервалу [0,7;1]. Значит можно сделать вывод о том, что модель не качественная.
Рассчитаем точность прогноза:
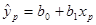 , где
, где 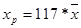
хр= 10698,1875
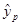 =-46434,55
=-46434,55
Значит точность прогноза удельных постоянных расходов при прогнозном значении объема выпускаемой продукции, составляющей 119% от среднего уровня составляет 46434.
Рассчитаем ошибку прогноза:
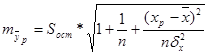
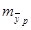 = 6907,6
= 6907,6
Значит, ошибка прогноза составляет 6907,6. Вычислим теперь на основе выше рассчитанного доверительный интервал: