Степенное уравнение регрессии имеет следующий вид:
 , где
, где 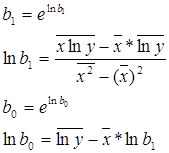
Для этого надо еще добавить в таблицу значения lny и x* lny, рассчитать общую сумму по 28 предприятиям и их среднее значение.
При вычислении b1 и b0 получены результаты:
b1 = 0, 90
b0 = 167325, 81
Значит степенное уравнение регрессии примет вид:
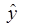 = 167325,81*0,90х
= 167325,81*0,90х
1. Рассчитаем коэффициент корреляции:

Следовательно, rxy = 0,96. Значит можно сделать вывод, что между Х и у, то есть между постоянными расходами и объемом выпускаемой продукции связь не тесная.
2. Рассчитаем коэффициент детерминации:
D = r2xy * 100
D =92, 95830 (%)
Следовательно, величина постоянных расходов только на 92, 27 % объясняется величиной объема выпускаемой продукции.
3. Рассчитаем дисперсионное отношение Фишера:
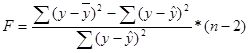
F расч = 343,233.
Fтабл = 4, 20. (нахождение см. в линейной регрессионной модели)
Так как Fрасчетное > Fтабличное значит уравнение статистически значимо.
4. Рассчитаем стандартные ошибки коэффициентов регрессии:

, где 
При вычислении Sост было получено, что
Sост = 6758,991.
Следовательно,
Sb1 = 316,97
Sb0 = 3563,99.
6. Рассчитаем доверительные границы коэффициентов регрессии:
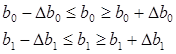 , где
, где 
табл находится по таблице t-критерия Стьюдента при уровне значимости 0,05 и числе степенной свободы равной 26.
Значит tтабл = 2,0555.
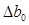 = 7325,59
= 7325,59
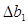 = 651,33
= 651,33
Следовательно, можно рассчитать доверительные границы коэффициентов регрессии:

Значит можно сделать вывод, что коэффициенты b1 и b0 значимы, так как они лежат в этих интервалах, то есть модель адекватна.
5. Рассчитаем t — статистики Стьюдента:
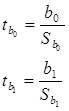
Получается, что  = 33,61,
= 33,61, 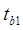 = -18,53. Значит коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 значим, так как больше tтабл, следовательно, один коэффициент tb0 оказывает воздействие на результативный признак.
= -18,53. Значит коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 значим, так как больше tтабл, следовательно, один коэффициент tb0 оказывает воздействие на результативный признак.
Рассчитаем индекс корреляции:
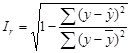
В результате получаем, что Ir = 0,96351 = rxy. Следовательно, индекс корреляции и коэффициент корреляции рассчитаны, верно.
7. Рассчитаем значение коэффициента эластичности:
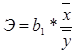
В результате Э = 0,000161736. Коэффициента эластичности показывает, что на 0,000161736 % изменится результат постоянных расходов (у) при изменении на 1% объема выпускаемой продукции (х.).
8. Оценить качество модели можно с помощью коэффициента аппроксимации:
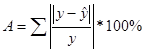
В результате получаем, что А = 0,341604171, следовательно, коэффициент аппроксимации не принадлежит интервалу [0,7;1]. Значит можно сделать вывод о том, что модель не качественная.
Рассчитаем точность прогноза:
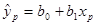 , где
, где 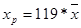
хр= 13,5687
 =46432,58
=46432,58
Значит точность прогноза удельных постоянных расходов при прогнозном значении объема выпускаемой продукции, составляющей 142,7% от среднего уровня составляет 168444,9249.
Рассчитаем ошибку прогноза:

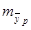 = 6947,015806
= 6947,015806
Значит, ошибка прогноза составляет 6907,6. Вычислим теперь на основе выше рассчитанного доверительный интервал:

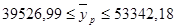
3. Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа»
Если сравнивать между собой результаты, полученные при расчетах линейной и степенной регрессионной модели, то можно выделить следующее:
1. Значение b1 в линейной регрессионной модели < b1 в степенной регрессионной модели, т.е. -5870,33<0,90 на 5871,23
2. Значение b0 в линейной регрессионной модели < b0 в степенной регрессионной модели, т.е 119784,3<167325,81 на 47541,51
3. rxy в линейной регрессионной модели >rxy в степенной регрессионной модели,
4. т.е 0,964148>0,96056 на 0,003588
5. D в линейной регрессионной модели < D в степенной регрессионной модели, т.е 92.95825<92, 95830 на 0.00005
6. F в линейной регрессионной модели > F в степенной регрессионной модели, т.е 310,27>343,233.на 32.963
7. Sост в линейной регрессионной модели > Sост в степенной регрессионной модели, т.е 6758.98>6758,991на 0,011
8. Sb1 в линейной регрессионной модели < Sb1 в степенной регрессионной модели, т.е 316.87<316,97 на 0,10
9. Sb0 в линейной регрессионной модели > Sb0 в степенной регрессионной модели, т.е 89,52>89,51 на 0,01.
Так же за счет того, что 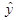 в линейной регрессионной модели отличается от
в линейной регрессионной модели отличается от 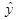 в степенной регрессионной модели доверительные границы коэффициентов регрессий разные, так же различаются
в степенной регрессионной модели доверительные границы коэффициентов регрессий разные, так же различаются 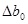 и
и 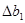 .
.
1. в линейной регрессионной модели < в степенной регрессионной модели, т.е 33,61>40,63 на 7.02
2. 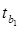 в линейной регрессионной модели < в степенной регрессионной модели, т.е. -18,53<1,18 на 19.71
в линейной регрессионной модели < в степенной регрессионной модели, т.е. -18,53<1,18 на 19.71
3. Ir в линейной регрессионной модели < Ir в степенной регрессионной модели, т.е 0,960563<0,96351 на 0, 002947
4. Э в линейной регрессионной модели > Э в степенной регрессионной модели, т.е -1,06>0,000161736 на 1.2058
5. А в линейной регрессионной модели < А в степенной регрессионной модели, т.е 2,83<0,341604 на 2.488396
Из выше сказанного, можно сказать, что практически все значения, полученные в степенной регрессионной модели больше, чем результаты, полученные в ходе вычисления линейной регрессионной модели. Прежде всего, это происходит за счет того, что в линейной регрессионной модели больше в степенной регрессионной модели.
Если сравнивать значения, полученные в линейной регрессионной модели с помощью Excel с «Пакетом анализа», то значения получаются те же самые, т.е. наблюдается полное совпадение результатов.
При построении графиков исходных данных с теоретической прямой можно сказать, что есть небольшое различие при построении теоретической прямой в линейной регрессионной модели и в степенной регрессионной модели. В степенной регрессионной модели теоретическая прямая немного отклоняется от прямой в линейной регрессионной модели. Так же можно наглядно увидеть, что на промежутке от 900 до 1050 (ед.) наблюдается наибольшая концентрация «наших значений», т.е. на этом промежутке происходит наибольшее пересечение объема выпускаемой продукции с постоянными расходами.