Лабораторная работа №7. Моделирование и исследование нейронной сети «Адаптивная резонансная теория».
Цель работы – изучение алгоритмов обучения и функционирования нейронной сети «Адаптивная резонансная теория» и ее моделирование для решения задачи распознавания образов.
Общие сведения
Сеть APT представляет собой векторный классификатор. Входной вектор классифицируется в зависимости от того, на какой из множества ранее запомненных образов он похож. Свое классификационное решение сеть APT выражает в форме возбуждения одного из нейронов распознающего слоя. Если входной вектор не соответствует ни одному из запомненных образов, создается новая категория посредством запоминания образа, идентичного новому входному вектору. Если определено, что входной вектор похож на один из ранее запомненных векторов с точки зрения определенного критерия сходства, запомненный вектор будет изменяться (обучаться) под воздействием нового входного вектора таким образом, чтобы стать более похожим на этот входной вектор.
Запомненный образ не будет изменяться, если текущий входной вектор не окажется достаточно похожим на него. Таким образом, решается дилемма стабильности-пластичности. Новый образ может создавать дополнительные классификационные категории, однако новый входной образ не может заставить измениться существующую память.
На рис. 1 показана упрощенная конфигурация сети APT, представленная в виде пяти функциональных модулей. Она включает два слоя нейронов, “слой сравнения” и “слой распознавания”. Приемник 1, Приемник 2 и Сброс обеспечивают управляющие функции, необходимые для обучения и классификации.
Рассмотрим функции отдельных модулей.
|
|
Слой сравнения. Слой сравнения получает двоичный входной вектор Х и первоначально пропускает его неизмененным для формирования выходного вектора C. На более поздней фазе в распознающем слое вырабатывается двоичный вектор R, модифицирующий вектор C.
Каждый нейрон в слое сравнения (рис. 2) получает три двоичных входа (0 или I): (1) компонента х i входного вектора X; (2) сигнал обратной связи R i – взвешенная сумма выходов распознающего слоя; (3) вход от Приемника 1 (один и тот же сигнал подается на все нейроны этого слоя).

Рис. 1. Упрощенная сеть АРТ.

Рис. 2. Упрощенный слой сравнения.
Чтобы получить на выходе нейрона единичное значение, как минимум два из трех его входов должны равняться единице; в противном случае его выход будет нулевым. Таким образом, реализуется правило двух третей. Первоначально выходной сигнал G1 Приемника 1 установлен в единицу, обеспечивая один из необходимых для возбуждения нейронов входов, а все компоненты вектора R установлены в 0; следовательно, в этот момент вектор C идентичен двоичному входному вектору X.
Слой распознавания. Слой распознавания осуществляет классификацию входных векторов. Каждый нейрон в слое распознавания имеет соответствующий вектор весов Bj. Только один нейрон с весовым вектором, наиболее соответствующим входному вектору, возбуждается; все остальные нейроны заторможены.
Как показано на рис. 3, нейрон в распознающем слое имеет, максимальную реакцию, если вектор C, являющийся выходом слоя сравнения, соответствует набору его весов, следовательно, веса представляют запомненный образ для категории входных векторов. Эти веса являются действительными числами, а не двоичными величинами. Двоичная версия этого образа также запоминается в соответствующем наборе весов слоя сравнения Tj (рис. 2).
|
|

Рис. 3. Упрощенный слой распознавания.
Приемник 2. G2, выход Приемника 2, равен единице, если входной вектор X имеет хотя бы одну единичную компоненту. Более точно, G2 является логическим ИЛИ от компонент вектора X.
Приемник 1. Как и сигнал G2, выходной сигнал G1 Приемника 1 равен 1, если хотя бы одна компонента двоичного входного вектора X равна единице; однако если хотя бы одна компонента вектора R равна единице, G1 устанавливается в нуль. Таблица, определяющая эти соотношения:
| ИЛИ от компонент вектора X | ИЛИ от компонент вектора R | G1 |
Сброс. Модуль сброса измеряет сходство между векторами X и C. Если они отличаются сильнее, чем требует параметр сходства, вырабатывается сигнал сброса возбужденного нейрона в слое распознавания.
В процессе функционирования модуль сброса вычисляет сходство как отношение количества единиц в векторе Х к их количеству в векторе C. Если это отношение ниже значения параметра сходства, вырабатывается сигнал сброса.
Рассмотрим более детально пять фаз функционирования сети АРТ: инициализацию, распознавание, сравнение, поиск и обучение.
1. Инициализация.
Перед началом процесса обучения сети все весовые векторы Bj и Tj, а также параметр сходства r, должны быть установлены в начальные значения.
|
|
Веса векторов Bj инициализируются одинаковыми, малыми значениями:
 для всех i, j,
для всех i, j,
где т – количество компонент входного вектора, L – константа, большая 1 (обычно L = 2).
Веса векторов Tj инициализируются единичными значениями:
t ij = 1 для всех j, i.
Параметр сходства r устанавливается в диапазоне от 0 до 1 в зависимости от требуемой степени сходства между запомненным образом и входным вектором. При высоких значениях r сеть относит к одному классу только очень слабо отличающиеся образы. С другой стороны, малое значение r заставляет сеть группировать образы, которые имеют слабое сходство между собой.
2. Распознавание.
Появление на входе сети входного вектора X инициализирует фазу распознавания. Так как вначале выходной вектор слоя распознавания отсутствует, сигнал G1 устанавливается в 1 функцией ИЛИ вектора X, обеспечивая все нейроны слоя сравнения одним из двух входов, необходимых для их возбуждения (как требует правило двух третей). В результате любая компонента вектора X, равная единице, обеспечивает второй единичный вход, тем самым заставляя соответствующий нейрон слоя сравнения возбуждаться и устанавливая его выход в единицу. Таким образом, на данном этапе вектор С идентичен вектору X.
Распознавание реализуется вычислением свертки для каждого нейрона слоя распознавания, определяемой следующим выражением:
NETj = (Bj • C),
где Вj – весовой вектор, соответствующий нейрону j в слое распознавания; С – выходной вектор нейронов слоя сравнения; в этот момент С равно X; NETj – возбуждение нейрона j в слое распознавания.
F является пороговой функцией, определяемой следующим образом:
OUTj = 1, если NETj> Θ,
OUTj = 0 в противном случае,
где Θпредставляет собой порог.
Принято, что латеральное торможение существует, но игнорируется здесь для сохранения простоты выражений. Оно обеспечивает тот факт, что только нейрон с максимальным значением NETj будет иметь выход, равный единице; все остальные нейроны будут иметь нулевой выход.
3. Сравнение.
На этой фазе сигнал обратной связи от слоя распознавания устанавливает G1 в нуль; в соответствии с правилом двух третей возбуждаются только те нейроны, которые имеют равные единице соответствующие компоненты векторов Р и X.
Блок сброса сравнивает вектор С и входной вектор X, вырабатывая сигнал сброса, когда их сходство S ниже порога сходства. Для вычисления сходства векторов выполняется следующая процедура:
Вычислить D – количество единиц в векторе X.
Вычислить N – количество единиц в векторе С.
Затем вычислить сходство S следующим образом:
S=N/D
Например, примем, что
Х = 1 0 1 1 1 0 1 D = 5
С = 0 0 1 1 1 0 1 N = 4
S=N/D=0,8
S может изменяться от 1 (наилучшее соответствие) до 0 (наихудшее соответствие).
Заметим, что правило двух третей делает С логическим произведением входного вектора Х и вектора Р. Однако Р равен Тj, весовому вектору выигравшего соревнование нейрона. Таким образом, D может быть определено как количество единиц в логическом произведении векторов Тj и X.
4. Поиск.
Если сходство S выигравшего нейрона превышает параметр сходства (S>r), то поиск не требуется. Однако если сеть предварительно была обучена, появление на входе вектора, не идентичного ни одному из предъявленных ранее, может возбудить в слое распознавания нейрон со сходством ниже требуемого уровня. В соответствии с алгоритмом обучения, возможно, что другой нейрон в слое распознавания будет обеспечивать лучшее соответствие, превышая требуемый уровень сходства, несмотря на то, что свертка между его весовым вектором и входным вектором может иметь меньшее значение.
Если сходство ниже требуемого уровня, запомненные образы просматриваются с целью поиска наиболее соответствующего входному вектору образа. Если такой образ отсутствует, вводится новый несвязанный нейрон, который в дальнейшем обучается. Для инициализации поиска сигнал сброса тормозит возбужденный нейрон в слое распознавания на время проведения поиска, сигнал G1 устанавливается в единицу и другой нейрон в слое распознавания выигрывает соревнование. Его запомненный образ затем проверяется на сходство, и процесс повторяется до тех пор, пока соревнование не выиграет нейрон из слоя распознавания со сходством, большим требуемого уровня (успешный поиск), либо пока все связанные нейроны не будут проверены и заторможены (неудачный поиск).
Неудачный поиск будет автоматически завершаться на несвязанном нейроне, так как его веса все равны единице, своему начальному значению. Поэтому правило двух третей приведет к идентичности вектора С входному вектору X, сходство S примет значение единицы и критерий сходства будет удовлетворен.
5. Обучение.
Обучение представляет собой процесс, в котором набор входных векторов подается последовательно на вход сети, и веса сети изменяются при этом таким образом, чтобы сходные векторы активизировали соответствующие нейроны. Заметим, что это – неуправляемое обучение, нет учителя и нет целевого вектора, определяющего требуемый ответ.
Различают два вида обучения: медленное и быстрое. При медленном обучении входной вектор предъявляется настолько кратковременно, что веса сети не имеют достаточного времени для достижения своих асимптотических значений в результате одного предъявления. В этом случае значения весов будут определяться скорее статистическими характеристиками входных векторов, чем характеристиками какого-то одного входного вектора. Динамика сети в процессе медленного обучения описывается дифференциальными уравнениями.
Быстрое обучение является специальным случаем медленного обучения, когда входной вектор прикладывается на достаточно длительный промежуток времени, чтобы позволить весам приблизиться к их окончательным значениям. В этом случае процесс обучения описывается только алгебраическими выражениями. Кроме того, компоненты весовых векторов Тj принимают двоичные значения, в отличие от непрерывного диапазона значений, требуемого в случае медленного обучения.
Рассмотренный далее алгоритм «быстрого обучения» используется как в случае успешного, так и неуспешного поиска.
Компоненты вектора весов Bj вычисляются следующим образом:
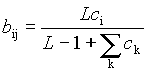
где с i – i-я компонента выходного вектора слоя сравнения; j – номер выигравшего нейрона в слое распознавания; b ij – вес связи, соединяющей нейрон i в слое сравнения с нейроном j в слое распознавания; L – константа > 1 (обычно 2).
Компоненты вектора весов Тj, связанного с новым запомненным вектором, изменяются таким образом, что они становятся равны соответствующим двоичным величинам вектора С:
t ij = с i для всех i,
где t ij – вес связи между выигравшим нейроном j в слое распознавания и нейроном i в слое сравнения.
Пример
Постановка задачи моделирования и составление входного файла.
Создать нейронную сеть, реализующую функции распознавания графических изображений с применением модели сети АРТ.
Изображения представим в виде двоичных векторов, закодированных следующим образом:
Табл. 1. Первый входной образ «0».
Табл. 2. Второй входной образ «1».
Табл. 3. Третий входной образ «4».
Табл. 4. Четвертый входной образ«7».
Табл. 5. Пятый входной образ«9».
На основании этих таблиц получаем входные последовательности - пять двоичных векторов:
1. 1 1 1 1 1 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1 1 1 1 1 1
2. 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0
3. 1 0 0 0 1 1 0 0 0 1 1 1 1 1 1 0 0 0 0 1 0 0 0 0 1
4. 1 1 1 1 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0
5. 0 1 1 1 0 1 0 0 0 1 0 1 1 1 0 0 0 1 0 0 0 1 0 0 0
Таким образом, файл с обучающей выборкой будет иметь вид:
! (chat.nni)
i 1. 1. 1. 1. 1. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1. 1. 1. 1. 1. 1.
i 0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 1. 0. 0.
i 1. 0. 0. 0. 1. 1. 0. 0. 0.1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 1. 0. 0. 0. 0. 1.
i 1. 1. 1. 1. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 0.
i 0. 1. 1. 1. 0. 1. 0. 0. 0. 1. 0. 1. 1. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0.