Рассмотрим параметры оценки построенной модели классификации.
Матрица ошибок – это матрица размера L×L, где L – число классов, ij‑й элемент матрицы (i – строка, j – столбец) равен числу объектов из i-го класса, которые были отнесены обученным классификатором к j-му. Число верно классифицированных объектов равно сумме элементов, стоящих на главной диагонали данной матрицы.
Результаты хорошо обученного классификатора покажут матрицу ошибок, в которой самые большие значения стоят на диагонали матрицы, а небольшие значения (в идеале нули) – на остальных позициях.
Рассмотрим матрицу ошибок для двух классов «да» и «нет» (табл. 2.2).
На диагонали матрицы находятся истинноположительные (true positive, TP) и истинноотрицательные (true negative, TN) экземпляры. Экземпляры, которые относятся к классу «да», но были отнесены классификатором к классу «нет» называются ложноотрицательными (false negative, FN). Экземпляры, которые относятся к классу «нет», но были отнесены классификатором к классу «да» называются ложноположительными (false positive, FP).
Таблица 2.2 – Матрица ошибок для бинарной классификации
| Предсказанный класс | ||||
| Да | Нет | |||
| Настоя-щий класс | Да | Истинноположительный (TP) | Ложноотрицательный (FN) | P=TP+FN |
| Нет | Ложноположительный (FP) | Истинноотрицательный (TN) | N=FP+TN | |
| P’=TP+FP | N’=FN+TN |
Рассмотрим выражения для расчета параметров точности классификации для каждого из классов. Для случаев классификации, в которых количество классов больше двух, в расчетах принимается, что рассматриваемый класс является классом «да», а все остальные классы объединяются и образуют класс «нет».
Параметр «TP rate » (чувствительность, sensitivity) или «recall » (эффективность) рассчитывается как:
|
|
 .
.
Для рассматриваемого класса значение данного параметра равно проценту верно классифицированных объектов класса (получается делением диагонального элемента матрицы ошибок на сумму элементов в его строке). Другими словами, параметр чувствительности (TP rate) показывает долю положительных экземпляров, которые были правильно распознаны.
Параметр «FP rate» рассчитывается по формуле:
 .
.
Его значение равно проценту объектов других классов, которые по ошибке занесены в рассматриваемый класс (если из матрицы вычеркнуть строку рассматриваемого класса, то значение равно сумме элементов столбца этого класса, деленное на сумму всех элементов).
Параметр «TN rate » (специфичность, specificity) рассчитывается по формуле:
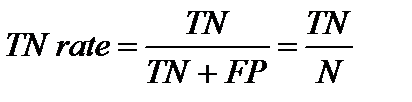 .
.
Этот параметр показывает часть отрицательных экземпляров, которые были правильно распознаны.
Параметр «precision » (точность) рассчитывается как
 .
.
Его значение равно проценту верно классифицированных объектов из объектов, отнесенных алгоритмом к рассматриваемому классу (отношение диагонального элемента к сумме элементов столбца).
Параметр «F-measure » - это среднее гармоническое Precision и Recall:
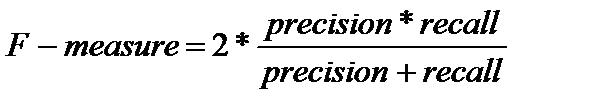 .
.
Параметры success rate (accuracy, recognition rate – доля успешных попыток, точность, коэффициент распознавания) и error rate (misclassification – доля ошибок, ошибочная классификация):
 ;
;
 .
.
Кроме того, бывает важно оценить потери и выигрыши (costs and benefits), связанные с качеством классификационной модели. Потери, связанные с ложноположительными предсказаниям (как например, неправильное предсказание, что больной пациент является здоровым) гораздо больше, чем ложноотрицательными предсказаниями (здоровый пациент отнесен к больным). В таких случаях мы можем отдать предпочтение одному типу ошибки над другим путем назначения им различных значений потерь связанных с переименованием классов.
|
|
К примеру, рассмотрим задачи выдачи кредита банком. Потери при выдаче кредита неплательщику гораздо выше, чем потери от невыдачи кредита лицу, сумевшему бы выплатить свой долг.
Рассмотрим теперь проблему неравномерного распределения классов, когда важный для задачи класс является редким в выборке. Это значит, что распределение набора данных отражает значительное большинство негативных экземпляров и меньшинство позитивных экземпляров. К примеру, в задаче распознавания мошенничества интересующим нас классом (позитивным) является класс «мошенничество», который появляется гораздо реже, чем негативный класс «не мошенничество». В медицинской задаче распознавания болезней к такому редкому классу может быть отнесен класс «злокачественная опухоль».
Предположим, что мы обучили классификатор классифицировать медицинский набор данных, в котором целевым атрибутом является атрибут «рак», который может принимать значения «да» и «нет». Параметр точности success rate равный 97% может показать, что классификатор довольно точен. Однако, что если во всей выборке было только 3% экземпляров, у которых класс принял значение «да»? В таком случае точность распознавания в 97% не может быть приемлемой. Классификатор может правильно распознавать большинство отрицательных экземпляров (не рак) и ошибочно классифицировать все экземпляры положительные экземпляры (рак).
|
|
Таким образом, нам необходимы другие параметры, позволяющие оценить, насколько хорошо классификатор распознает положительные и отрицательные экземпляры. Для данной задачи могут быть использованы параметры sensitivity и specificity.
Рассмотрим следующий пример обучения классификатора.
Таблица 2.3 – Пример обучения классификатора
| Классы | Да | Нет | Всего | Распознавание (%) |
| Да | 90/300=30,00 (sensitivity) | |||
| Нет | 9560/9700=98,56 (specificity) | |||
| Всего | 9650/10,000=96,50 (среднее) |
Можно заметить, что хотя классификатор показал общую высокую точность классификации, его возможности правильно распознавать позитивный (редкий) класс очень низки (что видно из величины параметра чувствительности). В то же время параметр специфичности высок, что значит, что классификатор может точно распознавать негативные классы.
Параметры precision и recall также широко используются в классификации. Precision может быть рассмотрен как мера точности/меткости (т.е. какой процент экземпляров отнесенных к положительным таковыми и являются), тогда как recall – это мера полноты (какой процент положительных экземпляров отнесены к положительным).
Идеальное значение параметра precision в 1,0 для класса С значит, что каждый экземпляр, который классификатор отнес к классу С, на самом деле принадлежит классу С. Однако, это ничего не говорит нам о количестве экземпляров класса С, который классификатор неправильно распознал. Идеальное значение параметра recall в 1,0 для класса С значит, что каждый экземпляр класса С был отнесен классификатором к классу С, но это ничего не говорит нам о том, сколько других экземпляров были неправильно классифицированы и отнесены к классу С.
Существует тенденция обратной взаимосвязи между параметрами precision и recall, т.е. существует возможность увеличить один параметр за счет уменьшения другого. К примеру, наш медицинский классификатор может достичь высокого значения параметра precision, относя все экземпляры класса рак к классу рак, но при этом может иметь низкое значение параметра recall, относя к классу рака также отрицательные экземпляры. Обычно эти два параметра рассматриваются вместе.
Альтернативный путь применения этих параметров – это их объединение в одном параметре F-measure (F1 score или F-score).
Рассмотрим еще один параметр оценки точности классификации. В табл. 2.4 представлен пример матрицы ошибок задачи классификации с тремя классами.
Таблица 2.4 – Пример №1 матрицы ошибок
| Предсказанный класс | |||||
| A | B | C | Total | ||
| Наст. класс | A | ||||
| B | |||||
| C | |||||
| Total |
В данном примере тестовая выборка содержит 200 экземпляров (сумма девяти элементов матрицы) и 88+40+12=140 из них правильно классифицированы, таким образом процент правильно классифицированных объектов равен 70%.
Данный классификатор для тестовой выборки предсказал 120 экземпляров класса A, 60 – класса B, 20 – класса C.
Что если бы на данной выборке работал случайный классификатор, который предсказал такое же количество экземпляров каждого класса. Рассмотрим таблицу 2.5.
Таблица 2.5 – Пример №2 матрицы ошибок для задачи классификации
| Предсказанный класс | |||||
| A | B | C | Total | ||
| Наст. класс | A | ||||
| B | |||||
| C | |||||
| Total |
В первой строке 100 экземпляров класса А разделены в такой же пропорции как (120:60:20). Точно так же разделены экземпляры второй и третьей строки. Общие значения в строках и столбцах не изменились, изменились значения матрицы.
Таким образом, случайный классификатор дает 60+18+4=82 правильно классифицированных экземпляра.
Параметр Каппа рассчитывает это ожидаемое значение (выводя его из успешности классификатора) и выражает результат в виде отношения: в числителе 140-82=58 экземпляров улучшения по сравнению со случайным предсказанием, а в знаменателе – все возможное улучшение 200-82=118. Для примера, приведенного выше, параметр Каппа равен 49,2%. Максимальное значение параметра Каппа 100% для идеального предсказания, а минимальное 0 – для случайного. В общем, можно сказать, что статистический параметр Каппа используется для оценки согласия между предсказанной и наблюдаемой категоризацией набора данных с поправкой на случайность.