Рис.8. PX при различных уровнях обнаружимости стимула
Сделать Z-преобразование можно по обычной таблице нормального распределения. Если есть таблица, показывающая для каждого C значение интеграла (12), то нужно попросту отыскать в таблице значение интеграла, наиболее близкое к P, и посмотреть слева, какому C оно соответствует. Легко показать, что уравнение (11) в терминах Z-преобразования имеет решение:
C = -Z [p(FA)]. (14)
Теперь допустим, что C найдено. Как, зная p(H), найти величину d'? Рассмотрим теоретическую картинку, из которой удалено распределение, соответствующее N (оно уже не понадобится, см. рис. 9а). Сдвинем все распределение вдоль оси Z вместе с критерием C влево так, чтобы центр совместился с точкой 0. Критерий С при этом, очевидно, займет позицию (С - d'), а заштрихованная область не изменится и останется равной по площади p(H) (см. рис. 9б). Но наше сдвинутое распределение имеет центр в нуле и единичную дисперсию. Следовательно:
 |
(15)
С - d' = z[p(H)]. (16)
Сопоставив (14) и (16), получим:
d' = z[p(H)] - z[p(FA)]. (17)
Допустим теперь, что проведен новый эксперимент с измененными параметрами, так что получена новая пара p(FA) и p(H). Если наше предположение относительно f(Z/S) и f(Z/N) верно (т.е. они оба нормальны и имеют одну и ту же дисперсию), то, несмотря на изменение величины С,
 | |||
 | |||
Рис.9. Теоретическое распределение ощущений при действии значащего стимула:
а -.сдвинутое на величину d' относительно "шумового" распределения; б - с центром, смещенным влево до точки 0; ось X - величина единичного среднеквадратичного отклонения; ось Y - плотность вероятности величины сенсорного эффекта; точка С - положение критерия
прямо определяемой по формуле (14), величина d', определяемая по формуле (17), должна оставаться постоянной. Мы приходим к важному заключению: если по оси абсцисс откладывать величины Z[p(FA)], а по оси ординат — z[p(H)], то точки PX должны выстроиться в прямую линию, описываемую уравнением (17): z[p(H)] = z[p(FA)] + d', и наклоненную под 45 к оси абсцисс. График зависимости Z[p(H)] от Z[p(FA)] (см. рис. 10) называется PX в двойных нормальных координатах. Из соотношения (17) вытекает способ экспериментальной проверки предположений, принятых о нормальности распределений и равенстве дисперсий. Пусть мы провели K экспериментов и получили K точек PX (K ³ 2).
Построим РХ в двойных нормальных координатах: z[p(FA)] и z [p(H)]. Поскольку вероятности p(H) и p(FA) оценивались по частотам (т.е. мы имеем лишь их приблизительные значения), то точки, соответствующие z-преобразованиям, будут отклоняться от теоретической прямой (с наклоном 45 градусов) даже в том случае, если проверяемые предположения верны. Следовательно, надо провести прямую наилучшего приближения и проверить с помощью стандартных статистических средств, значимо или не значимо ее наклон отличается от 45°. Если отличие не значимо, исходные предположения могут считаться верными, а величина свободного члена в формуле прямой дает нам статистическую оценку d'. Разумеется, всем этим выводам должна предшествовать проверка того, является ли расположение экспериментальных точек хорошим приближением к прямой линии, т.е. необходимо провести статистический тест на линейность.
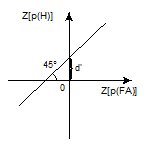 |
Рис.10. PX в двойных нормальных координатах, sS=sN
Допустим теперь, что удалось показать, что z-преобразованная PX не является прямой с наклоном в 45 градусов. Тогда мы можем обратиться к более общему варианту нашей теоретической схемы: допустить, что sSраспределения f(z/S) произвольна, но оба распределения нормальны. Очевидно, формула (14) сохраняет свою силу, так как C определяется только по p(FA). Изменения по отношению к случаю с ss,n= 1 появляются лишь в том месте, где распределение f(z/S) вместе с критерием C сдвигается влево до совмещения центра с нулевой точкой. Теперь мы уже не можем написать формулы (15) и (16), так как сдвинутое распределение описывается формулой:
 |
Однако, если мы вдобавок к сдвигу сожмем ось Z ровно в раз, то распределение приобретет нужную нам табличную форму. При этом критерий C, который после сдвига занял позицию C - a (мы уже не напишем d' вместо a), займет позицию. Итак:
 |
(18)
 |
(19)
Сопоставляя (14) и (19) имеем:
 |
(20)
Итак, если оба распределения нормальны, то график PX в двойных нормальных координатах должен быть прямой линией с наклоном 1/s (см. рис.11). Для проверки предположения о нормальности нужно оценить возможность описания экспериментальных точек линейной функцией или, (другими словами) “хорошесть” подгонки прямой линии к экспериментальным точкам.
На основании статистических оценок предположение о нормальности отвергается, если даже наилучшая (в смысле метода наименьших квадратов, например) прямая плохо подходит к данным.
Предположим, что распределения f(z/S) и f(z/N) имеют одинаковые дисперсии, то есть PX в двойных нормальных координатах является прямой линией с наклоном 1. Положение каждой отдельной точки на PX соответствует некоторому положению критерия C.
Можно показать, что при сделанных нами допущениях о нормальности распределений и равенстве дисперсий каждому положению C взаимно однозначно соответствует так называемое отношение правдоподобия (в точке C) – b, которое определяется как:
 .
.
Рис.11. PX в двойных нормальных координатах, sS¹sN.
 (21)
(21)
Здесь f(C/S) и f(C/N) представляют собой значения функций плотности вероятности f(X/S) и f(X/N), взятые в критической точке C. Отношение правдоподобия b характеризует то, во сколько раз правдоподобнее, что сенсорная репрезентация, равная по величине значению C, будет вызвана значащим стимулом, чем стимулом пустым.
По некоторым теоретическим соображениям положение критерия принято характеризовать именно этим значением b, а не самой величиной C.
Значения f(C/S) и f(C/N) легко найти, зная p(H) и p(FA). Для этого необходимо воспользоваться таблицей плотности нормального распределения: найти значения плотностей, соответствующие Z[p(H)] и Z[p(FA)] (что мы уже умеем делать). Эти значения обозначаются через f[p(H)] и f[p(FA)]. Таким образом:
 |
(22)
Оказывается, однако, что не обязательно искать f-преобразования для того, чтобы вычислить b. Вместо этого проще (и полезнее) вычислить lnb прямо по z-преобразованным вероятностям. Дело в том, что в формулы, выражающие p(H) и p(FA) через d' и b, последняя входит только в форме lnb(попытайтесь сами вывести эти соотношения):
 |
(23)
 |
(24)
Отсюда легко вывести формулу для вычисления lnβ:
 |
(25)
§ 3. Метод двухальтернативного вынужденного выбора (2АВВ)
В методе 2АВВ предъявления всегда осуществляются парами, причем предъявления в одной паре либо следуют друг за другом во времени, либо осуществляются одновременно, но ясно разделены пространственно. Одна пара всегда состоит из <S> и <N>, и это испытуемому известно, но какое именно из предъявлений (первое или второе, правое или левое и т.п.) содержит сигнал, а какое является пустым, должен определить испытуемый. Например, предъявляется пара линий, одна из которых наклонена, а другая вертикальна. Линии располагаются слева и справа от фиксационной точки и после каждого предъявления испытуемый должен решить, какая линия (слева или справа) имела наклон. Другой пример. Испытуемый слышит постоянный белый шум. Во время прослушивания дважды (скажем, с интервалом в полсекунды) загорается и гаснет (в течении 50 мс) индикатор начала и конца предъявления. В одном из двух предъявлений к шуму добавляется слабый тон частотой 1000 Гц, и задача испытуемого состоит в том, чтобы указать, в первом или во втором предъявлении присутствовала тональная добавка.
Чтобы различать варианты организации пары стимулов, условимся один из элементов пары называть “первым” и записывать на первом месте, а другой — “вторым” и записывать на втором месте. Таким образом пара может иметь либо форму <S,N>, либо форму <N,S>. Допустим, если в нашем первом примере наклонная линия находится слева, мы имеем <H,B>, а если справа — <B,H>, где B означает “вертикальна”, H — “наклонна”. Соответственно, если испытуемый считает, что наклонная линия находится слева, то его ответ может быть записан как “<H,B>”. В общем случае матрица стимулов-ответов представима в форме:
Во всех остальных отношениях 2АВВ ничем не отличается от метода “Да-Нет”. Если условиться идентифицировать пару по ее первому элементу, то можно даже не менять обозначений. Например,
P(S) = P(<S,N>), P(N) = P(<N,S>) = 1 - P(S).
Правильный ответ 1 можно условно считать попаданием и обозначать его условную вероятность через p(H)=p("Да","Нет"/<S,N>); ошибку 2 можно условно считать ложной тревогой и использовать обозначение p(FA)=p ("Да","Нет"/<N,S>) и т.д. Аналогично методу “Да-Нет” вводятся платежные матрицы, обратная связь, предварительная информация. Укажем, однако, на одно существенное отличие. Если в методе “Да-Нет” P(S) и платежная матрица таковы, что мы допускаем, что субъективные цены обеих ошибок (FA и O) одинаковы, то вовсе не необходимо, чтобы условные вероятности этих ошибок были равны. Или, что то же самое, нет оснований, вообще говоря, ожидать, что p(H) = p(CR). В методе 2АВВ, однако, пары <S,N> и
 |
<N,S> симметричны и при сделанных предположениях условные вероятности правильных ответов 1 и 2 должны быть равны. Это интуитивное соображение подкрепляется теоретической моделью, к изложению которой мы переходим. Но прежде введем новое обозначение. Условимся через р(C) (от английского correct — правильный) обозначать суммарную вероятность правильного ответа:
р(C) = P(S)·p(H) + P(N) ·р(CR). (26)
Результаты 2АВВ называются несмещенными, если
p(H) = p(CR) или, что то же самое, p(H)+p(FA)=1.
Теоретическая модель 2АВВ является простым распространением модели, изложенной в предыдущем разделе. Мы сразу предположим, что все сделанные там допущения и упрощающие предположения сохраняют свою силу по отношению к <S> и <N> по отдельности, а когда <S> и <N> объединяются в пару, их сенсорные репрезентации независимы друг от друга, причем испытуемый никогда не путает, какому (“первому” или “второму”) члену пары соответствует данный образ. Каждый образ оценивается по интенсивности некоторого выбранного качества, так что образ пары оценивается по паре интенсивности сенсорного качества <X1,X2>, записанных в той же последовательности, что и стимулы. Если предъявляется <S,N>, то X1 имеет распределение f(X/S), X2 — распределение f(X/N). Если предъявляется <N,S>, то наоборот X1 распределяется по f(X/N), а X2 — по f(X/S). Имея <X1,X2>, испытуемый должен решить, первая или вторая интенсивность соответствует <S>. Естественным правилом решения здесь является следующее: берется разность X1-X2 и сравнивается с критическим значением C*. Если X1- X2 > C*, то дается ответ “Да, Нет”, если же X1- X2 < C*, то “Нет, Да”. Как видим, C* играет здесь ту же роль, что и критерий C в методе “Да-Нет”. Заметим, что разность берется всегда в одном и том же направлении, скажем от “первой” интенсивности ко “второй”, X1-X2, независимо от того, было ли предъявлено <S,N> или <N,S>. Начнем с рассмотрения случая предъявления <S,N>. Поскольку X1 и X2 суть случайные величины, то их разность тоже является случайной величиной, распределение которой мы обозначим через f(Δx/<S,N>). f(x/<S,N>) есть плотность вероятности того, что X1 - X2 = Δx при предъявлении <S,N>. Эта функция однозначно определяется, если известны два распределения f(X/S) и f(X/N). Пусть теперь предъявлена пара <N,S>. Очевидно, что в этом случае разность X2 - X1 распределена точно так же, как разность X1 - X2 в первом случае, т.е. плотность вероятности события X2 - X1 = Δx/<N,S> равна плотности вероятности события X1 - X2 = Δx/<S,N>; но ведь событие X1 - X2 = Δx/<S,N> равносильно событию X2 - X1 = Δx/<N,S>. Мы получаем важное соотношение:
f ( Δ x/<S,N>) = f(- Δ x/<N,S>), (27)
где разность всегда берется от “первой” интенсивности ко “второй”, X1-X2. Соотношение (27) означает, что функции распределения f(Δx/<S,N>) и f(Δx/<N,S>) являются зеркально симметричными. В этом существенное отличие теоретической схемы для 2АВВ от теоретической схемы для метода “Да-Нет”: f(X/S) и f(X/N) могут быть сколь угодно непохожими друг на друга, но f(Δx/<S,N>) и f(Δx/<N,S>) являются зеркальными копиями. Введем в теоретическое представление критерий C*. На рис. 12 заштрихованные области равны по площади вероятностям p(CR) и p(H). Легко видеть, что несмещенный 2АВВ, при котором p(CR) = p(H), будет иметь место только в случае C* = 0. При отрицательных C* испытуемый будет более часто правильно указывать сигнал, если сигнальное предъявление было “первым”, чем если оно было “вторым” (при этом говорят, что наблюдатель имеет предрасположение к “первому” стимулу). При C*>0 испытуемый имеет предрасположение ко “второму” стимулу: p(CR) > p(H). Двигая C* справа налево и фиксируя различные пары p(H), p(FA) (p(FA) = 1 - p(CR)), мы можем построить кривую PX для 2АВВ (рис. 13).
В силу зеркальной симметричности распределений кривая PX для 2АВВ всегда симметрична относительно побочной диагонали. Это следствие в принципе позволяет экспериментально проверить валидность схемы с оценкой разностей X1 - X2, но, к сожалению, строгое статистическое доказательство симметричности PX провести довольно сложно. В эксперименте различные точки PX можно получить, задавая асимметричные платежные матрицы (например, штрафуя за пропуск “первого” сигнала значительно больше, чем за пропуск “второго”), подавая одну комбинацию (например, <S,N>) чаще, чем другую и т.д. — совершенно аналогично методу “Да-Нет”.
 |
Рис.12. Геометрическая модель обнаружения стимулов в методе 2ABB: вертикальная штриховка - p(H); горизонтальная - p(CR); C* - положение критерия принятия решения
До сих пор мы не использовали предположения о возможности монотонной трансформации X в Z, при которой f(X/S) и f(X/N) переходят в нормальные распределения f(Z/N) и f(Z/S).
 |
Рис.13. PX для эксперимента по методу 2ABB
 Если теперь это предположение принять и использовать разности Z1 - Z2, то можно показать следующее: если f(Z/N) имеет центр равным 0 и дисперисию равной 1, а f(Z/S) - центр в точке а и дисперсию равной Δ, то f(ΔZ/<S,N>) и f(ΔZ/<N,S>) являются тоже нормальными распределениями с одной и той же дисперсией, равной
Если теперь это предположение принять и использовать разности Z1 - Z2, то можно показать следующее: если f(Z/N) имеет центр равным 0 и дисперисию равной 1, а f(Z/S) - центр в точке а и дисперсию равной Δ, то f(ΔZ/<S,N>) и f(ΔZ/<N,S>) являются тоже нормальными распределениями с одной и той же дисперсией, равной
и с центрами, соответственно, в точках а и -а (см. рис. 14).
 Рассмотрим, каковы соотношения между вероятностями p(H) и p(FA) при произвольном значении C*. Для этого сдвинем левое распределение вместе с критерием до совмещения его центра с нулем и сожмем ось Z ровно в раз. Распределение после этого станет табличным, а критерий займет позицию
Рассмотрим, каковы соотношения между вероятностями p(H) и p(FA) при произвольном значении C*. Для этого сдвинем левое распределение вместе с критерием до совмещения его центра с нулем и сожмем ось Z ровно в раз. Распределение после этого станет табличным, а критерий займет позицию
Отсюда:

(28)
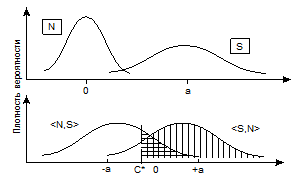 |
Рис. 14. Переход от распределений сенсорных эффектов, возникающих под действием пустого и значащего стимулов (<N> и <S>), к паре равновариативных распределений разности этих же сенсорных эффектов — <N,S> и <S,N>:ось абсцисс — интенсивность сенсорного эффекта (верхний график) или разница интенсивностей сенсорных эффектов (нижний график); ось ординат — плотность вероятности соответствующих сенсорных эффектов
 |
(29)
Вернемся теперь к исходной картинке и, сдвинув правое распределение вместе с критерием влево на а и, сжав z-ось в раз, получим:
 |
(30)
.
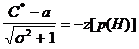 |
(31)
Откуда:

(32)
Итак, в двойных нормальных координатах PX для 2АВВ описывается прямой линией с наклоном 45 градусов (заметьте, при любой величине ). Отсюда следует способ экспериментальной проверки предположения о нормальности f(z/S) и f(z/N) в методе 2АВВ: по z-преобразованным точкам PX строится прямая наилучшего приближения, проверяется удовлетворительность приближения и незначимость отличия наклона от 45 градусов. Если дополнительно предположить, что s = 1, т.е. f(z/S) и f(z/N) имеют одинаковые дисперсии, то свободный член в формуле (32) станет равен (или, применяя стандартное обозначение,). В этом случае для разности z[p(H)] - z[p(FA)] в 2АВВ тоже иногда используют обозначение d' и пишут:
 . (33)
. (33)
Часто это соотношение (не очень корректно) читается так: чувствительность в 2АВВ в выше, чем в “Да-Нет”. Этот вывод вряд ли покажется неожиданным для психолога, поскольку почти очевидно, что в условиях, где у испытуемого имеется возможность сравнения,результаты будут выше, чем в тех условиях, где такая возможность отсутствует (метод "Да-Нет").
 В заключение мы остановимся на одном удивительном соотношении между 2АВВ и методом “Да-Нет”. Мы знаем, что чувствительность (отличимость сигнального стимула от пустого) может быть измерена числом d', если на распределении f(X/S) и f(X/N) наложено весьма жестко требование о существовании монотонной трансформации XZ, переводящей эти распределения в два нормальных с равными дисперсиями. Если это требование не выполняется, но f(X/S) и f(X/N) могут быть переведены путем монотонной трансформации в два нормальных распределения с разными дисперсиями, то в методе “Да-Нет” чувствительность характеризуется уже парой чисел (а, ), что весьма неудобно, поскольку к парам чисел неприложимы оценки “больше-меньше”, “возрастает-убывает” и т.д. Разумеется, в этом случае можно предложить какую-либо другую скалярную (т.е. выразимую одним действительным числом) меру чувствительности (на рис. 15 показана одна такая мера, называемая dyn), которая с формальной точки зрения будет являться скалярной функцией от а и s например,
В заключение мы остановимся на одном удивительном соотношении между 2АВВ и методом “Да-Нет”. Мы знаем, что чувствительность (отличимость сигнального стимула от пустого) может быть измерена числом d', если на распределении f(X/S) и f(X/N) наложено весьма жестко требование о существовании монотонной трансформации XZ, переводящей эти распределения в два нормальных с равными дисперсиями. Если это требование не выполняется, но f(X/S) и f(X/N) могут быть переведены путем монотонной трансформации в два нормальных распределения с разными дисперсиями, то в методе “Да-Нет” чувствительность характеризуется уже парой чисел (а, ), что весьма неудобно, поскольку к парам чисел неприложимы оценки “больше-меньше”, “возрастает-убывает” и т.д. Разумеется, в этом случае можно предложить какую-либо другую скалярную (т.е. выразимую одним действительным числом) меру чувствительности (на рис. 15 показана одна такая мера, называемая dyn), которая с формальной точки зрения будет являться скалярной функцией от а и s например,
Или можно обратиться к 2АВВ, взяв за меру чувствительности свободный член уравнения (32). Однако часто возникает вопрос, что делать в том случае, когда проверка отвергает предположение о нормальности? Существует ли какая-либо простая скалярная мера чувствительности, применимая при любых f(X/S) и f(X/N)? Такая мера действительно существует: площадь под кривой PX. Интуитивно эта мера представляется весьма удачной. Она универсальна (применима к любой PX) и всегда позволяет сказать, в каком сигнальном стимуле, S1 или S2, сигнал более обнаруживаем (в сопоставлении с одним и тем же N). Но у этой меры (обозначим ее U, см. рис. 16) есть существенный недостаток — для ее вычисления необходимо знать достаточно много точек PX.
Допустим, однако, что для некоторой пары <N> и <S> было проведено подробное исследование и вычислена мера U. Пусть теперь мы используем те же <S> и <N> в методе 2АВВ. Мы провели всего один эксперимент и получили (с точностью до статистических вариаций) следующий результат:
Результаты показывают, что выбор является несмещенным: p(H) = p(CR). Мы знаем, что в этом случае общая вероятность правильного ответа P(C) (см. формулу (26)) равна p. Удивительное соотношение между “Да-Нет” и 2АВВ, о котором идет речь, состоит в том, что если изложенная модель обнаружения верна, то должно быть U = p. Другими словами: в несмещенном случае P(C)2АВВ= = U"Да-Нет". Таким образом, в качестве хорошей и простой (пожалуй, самой простой) меры чувствительности в 2АВВ может использоваться процент правильных ответов P(C).
 |
Рис. 15. Графическое представление меры чувствительности dYNна РХ в двойных нормальных координатах
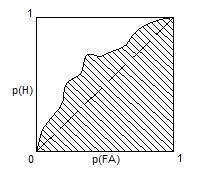 |
Рис. 16. Графическое представление меры чувствительности U на РХ в двойных нормальных координатах
§ 4. Метод оценки
Этот метод может быть использован как модификация метода “Да-Нет” и как модификация метода 2АВВ. Здесь будет изложен только первый вариант, поскольку перенесение его на случай 2АВВ является тривиальным.
 |
Как мы уже знаем, в ряде случаев (для проверки гипотез о форме распределений или для вычисления таких мер чувствительности, как U) требуется PX по достаточно большому количеству точек. Для получения нескольких точек PX методом “Да-Нет” необходимо несколько раз провести эксперимент с одной и той же парой <S> и <N>, но с различными параметрами организации эксперимента, такими как P(S), платежная матрица и т.п. Каждый эксперимент должен содержать большое количество предъявлений для того, чтобы, во-первых, можно было исключить первые пробы, в которых схема соответствия еще не установилась, и, во-вторых, чтобы частоты событий (“Да”/S) и (“Да”/N), высчитанные по оставшимся пробам (асимптотический уровень), достаточно точно соответствовали вероятностям p(H) и p(FA). Более того, поскольку от эксперимента к эксперименту чувствительность наблюдателя к данному сигналу может меняться, эксперимент с одними и теми же параметрами организации желательно повторить несколько раз на разных этапах (скажем, ближе к началу, середине и концу) всей серии экспериментов. Все это довольно громоздкая работа. Метод оценки (МО) дает нам возможность получить несколько точек PX в результате только одного эксперимента, хотя его объем, обыкновенно, превышает объем одного эксперимента “Да-Нет”.
Процедура метода оценки (МО) отличается от метода “Да-Нет” только тем, что после каждого предъявления вместо ответа “Да” или “Нет” испытуемый указывает степень его уверенности в наличии/отсутствии сигнала в этом предъявлении. Например, “совершенно уверен, что сигнал был”, “уверен, что сигнал был”, “скорее был, чем не был”, “не могу выбрать”, “скорее не был, чем был”, “уверен, что сигнала не было”, “совершенно уверен, что сигнала не было”. Эти 7 категорий естественно обозначить числами в том же порядке: 3, 2, 1, 0, -1, -2, -3. В методе оценки уверенности набор категорий всегда задается испытуемому заранее и обычно кодируется некоторой числовой системой. Иногда используется процентная шкала, когда испытуемый говорит о сигнале: “На 50% был”, “На 100% был” (точно был), “На 10% был”, “На 0% был” (точно не был). В этом случае либо испытуемого просят пользоваться только определенными (например, только круглыми: 0, 10, 20...%) числами, либо он может называть произвольные проценты (скажем, 78%), но потом ответы объединяются в несколько групп (например, все числа меньше 5% — в группу 0, все числа между 5 и 15 — в группу 10% и т.д.). Для конкретности предположим, что испытуемому заданы 7 категорий, названных в нашем примере. Обыкновенно эксперимент проводится без платежной матрицы или с симметричной платежной матрицей и с P(S) = P(N) = 0.5. Результаты эксперимента могут быть представлены в виде следующей таблицы (см. табл. 5).
Таблица 5
Теоретические результаты эксперимента с использованием метода оценки
 |
Р(n), n=-3,...+3, есть оценка условной вероятности P(n/S), получаемая путем деления числа всех случаев, когда предъявлялось <S> и был дан ответ “n”, на число всех предъявлений <S>. Аналогично q(n) есть оценка условной вероятности P(n/N). Теоретическое осмысление этих данных в рамках модели, изложенной в двух предыдущих разделах, состоит в предположении, что если испытуемому заданы K категорий (от полной уверенности в отсутствии до полной уверенности в наличии S), то он так же, как и в условиях эксперимента “Да-Нет”, базируется на интенсивности некоторого сенсорного качества, но делит ее не на две, а на K областей, как показано на рис. 17.