В начале предыдущего параграфа мы отмечали, что вычислительные алгоритмы ФА основываются на ряде математических допущений о характере эмпирических данных, подвергаемых ФА. Остановимся на ряде статистических показателей, которые помогают исследователю оценить степень соответствия данных этим допущениям.
Как правило, в любой программе по ФА предусмотрен расчет показателей описательной статистики по матрице смешения. Например в статистических системах “Stadia” и SPSS для каждой переменной вычисляются общее количество наблюдений, среднее арифметическое значение и среднее квадратичное отклонение (см. табл. 3). Эти достаточно простые показатели позволяют быстро сравнить между собой все анализируемые переменные, и уже на уровне анализа исходных данных попытаться найти возможные ошибки, связанные либо с проведенными измерениями, либо с вводом данных в компьютер. Например, если при сборе данных использовалась 7-балльная шкала, то наверное вас насторожит среднее значение по какой-то переменной, равное 0.87, или резко отличающаяся от других величина среднего квадратичного отклонения.
Коэффициент сферичности Бартлета используется для оценки “хорошести” корреляционной матрицы. Если этот коэффициент достаточно большой, а соответствующий ему уровень значимости мал (например, меньше 0.05 или 0.01), то это свидетельствует о надежности вычисления корреляционной матрицы. При высоком уровне значимости исследователю стоит задуматься об адекватности использования ФА с полученными данными.
Кроме того, для оценки надежности вычислений элементов корреляционной матрицы и возможности ее описания с помощью ФА во многих статистических программах применяется так называемая мера адекватности выборки Кайзера—Мейера—Олкина(КМО). По мнению Г. Кайзера (1974), значения КМО около 0.9 оцениваются как “изумительные”, 0.8 — “достойные похвалы”, 0.7 — “средние”, 0.6 — “посредственные”, 0.5 — “плохие”, а ниже 0.5 — “неприемлемые”. Для оценки надежности вклада в корреляционную матрицу каждой переменной в отдельности также используют меру выборочной адекватности (например, коэффициент MSAiв системе SPSS). Вышеприведенные характеристики Г. Кайзера вполне справедливы и для оценки этих величин тоже. Исследование надежности каждой переменной позволяет исключить из расчетов одну или несколько переменных, и тем самым повысить результативность ФА.
Таблица 3
Данные описательной статистики для 9 переменных
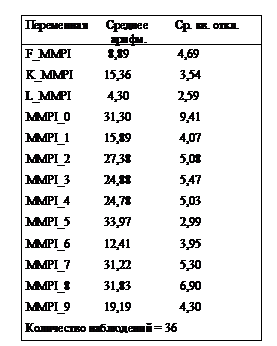 |
Работая с различными данными, Г. Кайзер установил, что величина данного коэффициента адекватности повышается при: а) увеличении количества переменных, б) возрастании числа наблюдений каждой переменной, в) уменьшении числа общих факторов и г) увеличении абсолютных значений коэффициентов корреляций. По сути дела данный автор выделил те условия, при которых повышается адекватность данных, а следовательно, и информативность ФА.
§ 5. Несколько замечаний по поводу конфирматорного ФА
Как было отмечено выше, конфирматорный ФА используется для проверки и подтверждения теоретической модели факторного типа эмпирическими данными. Предполагается, что у исследователя есть достаточно строго сформулированная модель изучаемой им реальности (например, какие психологические факторы в межкультурном исследовании мотивации достижения у школьников являются общими для всех культур, а какие специфическим образом влияют на мотивационные переменные только в одной стране).
При использовании конфирматорного ФА исследователь (в рамках своей модели) четко формулирует гипотезу о числе общих и специфических факторов. Естественно, эта гипотеза должна основываться на серьезном анализе природы исследуемых переменных и лежащих в их основе факторов. Более того, проверяя свою модель на реальных данных, исследователь может делать и количественные предположения о величине корреляции между переменными, величинах факторных нагрузок для ряда исследуемых переменных и зависимости между факторами (ортогональными или косоугольными). Имея данные эмпирических измерений, с одной стороны, и набор разнообразных теоретических гипотез — с другой, психолог с помощью ФА фактически занимается проверкой сформулированных им гипотез о свойствах изучаемой (моделируемой) реальности.
Подробное изложение исследовательских стратегий с помощью конфирматорного ФА не входит в задачу настоящего учебного пособия, поскольку представляет собой особую и достаточно специфическую задачу. Тем не менее, укажем, что в настоящее время существуют достаточно удобные компьютерные программы, где реализованы современные подходы к анализу моделей с латентными переменными, частным случаем которых и является ФА. В качестве примера мы можем привести достаточно известный статистический пакет Lisrel 8, который дает возможность обрабатывать данные методом моделирования с помощью линейных структурных уравнений. Для подробного знакомства с принципами конфирматорного ФА могут быть рекомендовано (Благуш, 1989), а также прекрасное описание статистического пакета Lisrel 81.
Методические рекомендации по выполнению учебного задания по теме
«Факторный анализ»
Основная трудность при выполнении настоящего учебного задания — это, как ни странно, выбрать подходящий предмет для исследования, т.е. определить тот набор переменных, которые необходимо или интересно изучить с помощью ФА. При решении этой проблемы можно пойти двумя путями: либо взять заведомо подходящую задачу, которая ранее уже решалась с помощью ФА, либо придумать ее самому (последнее, естественно труднее, но интереснее). В принципе и то, и другое подходит для выполнения учебного задания. Достаточно стандартный вариант выполнения работы — это провести ФА какого-либо известного опросника, в котором уже содержатся шкалы (факторы) и отражающие их вопросы (переменные). Еще лучше взять какой-либо новый (например, только что переведенный), но еще не стандартизированный опросник и провести исследование с ним. В этом случае будет интересно подумать над интерпретацией результатов ФА, и хотя бы немного побыть в роли разработчика новых психодиагностических методик. Неплохой вариант, если вы найдете в литературе данные, которые можно обработать ФА, и подумаете над их интерпретацией в контексте обсуждаемых автором работы проблем.
Для ориентировки студентов в том, что же можно сделать, мы приводим ниже список названий работ по ФА, которые были выполнены студентами 2-го курса факультета психологии Московского государственного университета им. М.В. Ломоносова в 1995—1996 гг.:
1. Оценка эмоционального состояния при прослушивании музыки разных жанров.
2. Личностные особенности деятелей тайных обществ первой трети XIX века.
3. Факторное пространство русских писателей XIX века.
4. Исследование факторов, определяющих положение человека в семье.
5. Изучение влияния различных типов стрессогенных ситуаций на интенсивность эмоционального переживания: определение специфики ситуаций для мужской и женской выборок.
6. Выделение скрытых факторов, обуславливающих привлекательность печатной рекламы.
7. Выявление факторов, оказывающих наибольшее влияние на выбор того или иного политического лидера при голосовании.
8. Факторы, способствующие заинтересованности человека той или иной пластинкой по виду ее конверта.
9. Характеристика человека, с которым мы хотим дружить.
10. Факторизация шкал опросника “16 PF”.
11. Оценка изучаемых предметов студентами 2-го курса.
12. Выявление факторной структуры шкал акцентуации характера по Леонгарду (тест Шмишека). Сравнение результатов факторизации на 2-х выборках испытуемых.
13. Исследование факторов, влияющих на выбор страны для зарубежной поездки.
14. Факторы, определяющие оценку идеального мужчины и идеальной женщины.
15. Исследование факторов, определяющих специфику национального характера.
После того, как уже выбрана адекватная исследовательская или практическая задача (предмет исследования), которая будет решаться с помощью ФА, и в основном определен набор оцениваемых переменных, стоит еще раз подумать о правильности их выбора. В первую очередь следует обратить внимание на то, чтобы переменные не повторяли друг друга, а разнообразно и всесторонне описывали предмет вашего исследования. В разведочном исследовании тщательный и вдумчивый подбор наблюдаемых переменных может обеспечить полноту описания изучаемой реальности. От этого и будет зависеть, сумеете ли вы выделить действительно важные факторы, влияющие на восприятие, оценку, понимание или действия человека в определенной ситуации, описываемой используемыми переменными. Например, если вы решили исследовать психологические факторы, которые определяют восприятие избирателями лидеров политических партий, то не следует ограничиваться оценкой только их личностных особенностей, безусловно стоит включить также и описательные характеристики их внешних данных, политических ориентаций и многое другое. Не следует забывать о том, что исследуемые вами факторы есть не более чем “экстракт” наблюдаемых переменных, и, следовательно, они не могут появиться из ничего.
Однако не стоит и чрезмерно увеличивать число используемых переменных путем включения нескольких однотипных. Если несколько выбранных вами переменных похожи друг на друга, то очевидно, что это приведет к появлению очень высоких коэффициентов корреляции между этими переменными и, таким образом, к избыточности и односторонности описания предмета вашего исследования.
В том случае, когда вы затрудняетесь или сомневаетесь в выборе необходимых переменных, полезно создать их заведомо избыточный список, а затем, воспользовавшись правилом “со стороны виднее”, попросить своих коллег поучаствовать в оценке этого списка в качестве экспертов.
Следующий важный этап в проведении исследования — сбор данных.
На этом этапе, как правило, сталкиваются с двумя вопросами: по какой группе испытуемых собирать данные и каким методом это делать? На первый вопрос ответить достаточно просто: чтобы получить статистически достоверные оценки коэффициентов корреляции, нужно по каждой переменной собрать не менее 12—15 наблюдений. Если задача состоит в построении факторного пространства для одного испытуемого, то нужно решить, каким образом лучше получить от него такое количество повторных данных.
При решении второго вопроса мы советуем обратиться к соответствующей главе настоящего пособия, посвященной методу балльной оценки. Какой процедурой сбора данных лучше воспользоваться, зависит от задачи вашего исследования, от условий, в которых проводится тестирование, от возраста и уровня образования испытуемых и т. д. При выборе конкретного варианта методики не стоит забывать и о простоте последующей обработки исходных данных, и об удобстве их считывания с бланка и ввода в компьютер.
Ввод данных и их обработка.
Остановимся кратко на некоторых важных этапах работы со статистической программой, с помощью которой собственно и реализуется процедура ФА. Для этой цели мы рекомендуем использовать либо русскоязычную статистическую систему “Stadia” или англоязычную систему обработки и анализа данных SPSS. Эти две программы достаточно широко используются, соответственно, российскими и зарубежными психологами и ориентированы на пользователя-гуманитария. Для облегчения использования этих двух программ, мы остановимся на основных моментах работы с каждой из них.
Работа в системе “Stadia”. После вызова программы (stadia.exe) вы сразу же попадаете в редактор данных и, следовательно, можете начинать ввод данных в электронную таблицу. Закончив ввод данных, не забудьте их сохранить на жестком диске — F4; практика показывает, что несоблюдение этого правила для неопытного пользователя часто заканчивается повторным вводом данных. Кроме того, обязательно проверьте правильность ввода данных (лучше эту малоприятную процедуру выполнять вдвоем: один читает — другой проверяет). В том случае, если данные уже набраны в каком-либо текстовом редакторе, вы можете загрузить их в окно редактора с дискеты, для чего используйте функцию “Чтение” — F3.
Войдя в меню статистических методов (F9), выберите в разделе “Многомерные методы” опцию “Факторный анализ”. Первый запрос программы касается типа введенных данных — что это: матрица смешения (переменные объекты) или корреляционная матрица; как правило, вы начинаете работать с матрицей смешения. После рассчета корреляционной матрицы появляется вопрос: “Записать ли рассчитанные корреляции в матрицу данных?”; чаще всего в этом нет особой необходимости. Далее на экране распечатывается таблица с показателями описательной статистики и матрица корреляций. Эта уже та информация, которую стоит записать в файл результатов — F2; в качестве имени файла (без расширения!) целесообразно ввести первые 6—8 букв своей фамилии латинскими буквами. Если выводимая на экран информация не уместилась на одной экранной странице, нажмите клавишу “Enter”. После этого на экране распечатается таблица с величинами собственных значений и процентом объясняемой дисперсии факторов (не забудьте сохранить и ее!) и появляется вопрос: “Выдать собственные векторы и новые координаты объектов?”; поскольку анализ собственных векторов используется редко, ответьте — “нет”. А вот график собственных значений посмотреть весьма полезно, поэтому на следующий вопрос программы ответьте “да” и посмотрите его на экране. Затем производится расчет первичных факторных нагрузок и соответствующая матрица распечатывается на экране. Можно ее сохранить в файле и посмотреть факторные диаграммы, а можно ответить “нет” (чаще всего так и поступают) и, нажав “Enter”, сразу перейти к вращению осей координат. Для проведения вращения нужно обязательно указать число факторов, а затем выбрать метод вращения и ответить на вопрос “Нужна ли нормализация Кайзера?”. Нормализация факторных нагрузок Кайзера выполняется для того, чтобы исключить влияние тех переменных, которые имеют по сравнению с другими переменными значительно большие значения нагрузок общих факторов. После расчета факторных нагрузок производится расчет и распечатка коэффициентов общности и специфичности для каждого фактора и, конечно, матрицы факторных нагрузок после вращения. На этом этапе имеется возможность посмотреть факторную диаграмму переменных в осях “фактор 1 — фактор 2”. После просмотра факторных диаграмм можно еще раз вернуться к выполнению процедуры вращения с новым (большим или меньшим) количеством факторов и опять проанализировать факторные диаграммы. После принятия решения о количестве факторов не забудьте сохранить в файле результатов соответствующую матрицу факторных нагрузок — F2. При необходимости любую факторную диаграмму можно распечатать на принтере или сохранить рисунок в виде файла.
Работа в системе “SPSS”. После вызова программы из Windows так же, как и при работе в “Stadia”, вы попадаете в электронную таблицу (окно редактора данных) и сразу же можете вводить данные в первую переменную (var00001). Если данные уже набраны в виде ASCII-файла, то их можно импортировать в SPSS (меню: File, подменю: Read ASCII Data). В случае импорта данных следует указать путь к файлу данных и его имя, а также выбрать тип формата данных — Freefield. Далее, нажав на кнопку Define, вы переходите в режим определения переменных, в котором необходимо каждой переменной (их столько, сколько столбцов в вашем файле данных) присвоить имя — в окошке Name, и определить ее тип — Numeric. Ввод каждой переменной в общий список анализируемых переменных (Defined Variables) осуществляется нажатием клавиши со стрелкой. После окончания определения всех переменных нажмите на клавишу OK. SPSS автоматически перейдет в окно редактора данных и осуществит ввод вашего ASCII-файла.
Переход к процедуре факторного анализа осуществляется следующим образом: меню — Statistics, подменю — Data Reduction, а в нем — Factor... После вызова процедуры ФА в правом окне выделите мышкой нужные переменные и перенесите их в окно Variables, нажав на кнопку со стрелкой.
Следующий важный этап работы — выбор параметров (опций) работы процедуры ФА. Первая группа параметров — расчет необходимых коэффициентов описательной статистики (Descriptives). В данном разделе стоит заказать расчет следующих показателей: Univariate descriptives (средние и стандартные отклонения для каждой переменной), Significance level (оценки достоверности получаемых коэффициентов корреляции), а также KMO and Bartlett‘s test of sphericity (соответственно, мера адекватности выборки Кайзера—Мейера—Олкина и коэффициент Бартлета).
Далее выбирают конкретный метод факторизации корреляционной матрицы — Extraction. В данном разделе сделайте следующий выбор: 1) в качестве метода укажите — Principal components (метод главных компонент); 2) в подразделе Extract (сколько факторов выделять) можно либо отметить критическую величину собственного значения фактора (Eigenvalues over), например: не меньше 1, либо задать некоторое ожидаемое число факторов (Number of factors); 3) в подразделе Display (какие результаты показывать) выберите пункт Scree plot, чтобы увидеть график изменения собственных значений.
После этого следует выбрать метод вращения осей координат — раздел Rotation. Выберите Varimax, а также закажите для вывода результатов ФА:Rotated solution (распечатка матрицы факторных нагрузок после вращения) и Loading plots (построение факторных диаграмм).
В разделах Scores и Options все параметры установлены оптимальным образом, поэтому никаких изменений делать не стоит. После установки всех параметров (в каждом разделе не забудьте нажимать кнопку Continue!) для начала выполнения процедуры ФА следует нажать кнопку OK.
Все текстовые результаты заносятся в окно Output, и их можно просмотреть, используя кнопки скролинга по вертикали ( и ¯). Графические результаты ФА находятся в окне Chart Carusel, куда можно попасть из головного меню (Window) или непосредственно щелкнуть мышью на соответствующей пиктограмме внизу экрана.
Литература
1. Благуш П. Факторный анализ с обобщениями. М.: Финансы и статистика, 1989. 248 с.
2. Иберла К. Факторный анализ.. М.: Статистика, 1980. 398 с.
3. Ким Дж.-О., Мьюллер Ч.У. Факторный анализ: статистические методы и практические вопросы // Факторный, дискриминантный и кластерный анализ. М.: Финансы и статистика, 1989. С. 5 — 77.
4. Окунь Я. Факторный анализ. М.: Статистика, 1974. 200 с.
5. Харман Г. Современный факторный анализ.. М.: Статистика, 1972. 486 с.
6. SPSS. SPSS Professional Statistics 6.1. Chapter 2. Factor Analysis. Maria J. Norusis: SPSS Inc., 1994. P. 47—82.