| N |
| N2 |
| N1 |
| N12 |
| Рисунок 3. |
| E |
Где N – неизвестное количество ошибок, присутствовавших в программе до начала тестирования;
N1 – количество ошибок найденных первой группой тестеров;
N2 – количество ошибок найденных второй группой тестеров;
N12 – ошибки обнаруженные дважды (обеими группами);
Е – эффективность тестирования;
Эффективность тестирования каждой из групп можно определить как
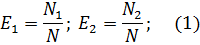
Предполагая, что возможность обнаружения всех ошибок одинакова для обеих групп можно допустить, что если первая группа обнаружила определенно количество всех ошибок, она могла бы определить то ж0е количество любого случайным образом выбранного подмножества. В частности, можно допустить
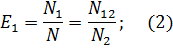
из формулы (2) получим
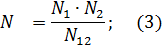
Число оставшихся ошибок можно найти как
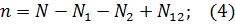
Вероятность обнаружения общих ошибок:
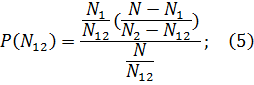
Модель Миллса
Использование этой модели предполагает необходимость перед началом тестирования искусственно «засорять» программу, т.е. вносить в нее некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в проколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как естественные, так и искусственные внесены) имеют равную вероятность быть найденными в процессе тестирования.
Тестируя программу в течение некоторого времени, собирают статистику об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные. Соотношение, называемое формулой Миллса, дает возможность оценить первоначальное число ошибок в программе N.
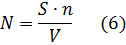
Где: S – количество искусственно внесенных ошибок;
n – число найденных собственных ошибок;
V – число обнаруженных к моменту оценки искусственных ошибок.
Вторая часть модели связана с проверкой гипотезы от N. Предположим, что в программе имеется К собственных ошибок, и внесем в нее еще S ошибок. В процессе тестирования были обнаружены все S внесенных ошибок и п собственных ошибок.
Тогда по формуле Миллса мы предполагаем, что первоначально в программе было N = п ошибок. Вероятность, с которой можно высказать такое предположение, возможно рассчитать по следующему соотношению:
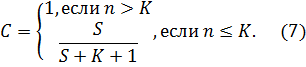
Таким образом, величина С является мерой доверия к модели и показывает вероятность того, насколько правильно найдено значение N.
Эти две формулы образуют полезную модель ошибок
· первая предсказывает их количество
· вторая позволяет определить достоверность прогноза [7].
Недостаток модели Миллса:
1. Предполагается, что собственные и внесенные ошибки обнаруживаются с одинаковой вероятностью, поэтому внесенные ошибки должны быть типичнымидля данной программы.
2. Количество внесенных ошибок должно быть в 10 раз больше, чем собственных.
3. Сложность – неизвестно, какой должна быть типичная ошибка, если тестирование проводит не тот, кто писал программу.
Примеры решения задач