Рассмотрим еще пример по определению мультиколлинеарности факторов и построению адекватной модели множественной регрессии. В таблице представлены данные по Центральному федеральному округу за 2017 год.
В результате определим влияние следующих факторов на продолжительность жизни населения (Y):
Х1 – ВРП на душу населения;
Х2 – уровень безработицы, %;
Х3 – среднедушевые денежные доходы, руб.;
Х4 - коэффициент фондов;
Х5 - количество врачей на 10000 человек населения.
Используя процедуру выбора факторов, предложим и построим подходящую линейную регрессионную модель изучаемого показателя. Далее дадим экономическую интерпретацию модели с использованием коэффициентов эластичности. Получим точечные и интервальные прогнозы изучаемого показателя.
Таблица 1 Исходные данные для расчета
| Регионы | у | х1 | х2 | х3 | х4 | х5 |
| Белгородская область | 72,87 | 443,1 | 4,0 | 13,9 | 41,6 | |
| Брянская область | 70,92 | 219,6 | 4,6 | 12,7 | 39,1 | |
| Владимирская область | 70,28 | 255,4 | 5,6 | 10,6 | 33,9 | |
| Воронежская область | 72,08 | 352,9 | 4,5 | 15,1 | 50,9 | |
| Ивановская область | 70,77 | 165,5 | 5,6 | 10,9 | 43,8 | |
| Калужская область | 71,18 | 331,5 | 4,2 | 12,2 | 40,1 | |
| Костромская область | 70,87 | 241,5 | 5,5 | 10,7 | 37,1 | |
| Курская область | 70,94 | 299,7 | 4,3 | 12,4 | 48,5 | |
| Липецкая область | 71,62 | 395,5 | 4,0 | 13,2 | 42,3 | |
| Московская область | 72,50 | 441,8 | 3,3 | 14,0 | 38,0 | |
| Орловская область | 70,73 | 269,9 | 6,4 | 11,6 | 44,6 | |
| Рязанская область | 71,87 | 279,0 | 4,4 | 11,8 | 51,8 | |
| Смоленская область | 69,98 | 267,3 | 6,1 | 11,4 | 50,9 | |
| Тамбовская область | 72,11 | 326,5 | 4,5 | 12,8 | 37,0 | |
| Тверская область | 69,24 | 260,5 | 5,8 | 9,4 | 44,1 | |
| Тульская область | 70,56 | 315,7 | 4,1 | 11,7 | 36,2 | |
| Ярославская область | 71,21 | 339,7 | 6,7 | 12,8 | 53,0 | |
| г. Москва | 77,08 | 1103,5 | 1,8 | 16,6 | 55,4 |
Построим линейную регрессионную модель с использованием всех пяти объясняющих переменных с помощью функции Регрессия.
Таблица 2 Регрессионная статистика
| Регрессионная статистика | |
| Множественный R | 0,957500374 |
| R-квадрат | 0,916806966 |
| Нормированный R-квадрат | 0,882143202 |
| Стандартная ошибка | 0,570946651 |
| Наблюдения |
Таблица 3 Дисперсионный анализ
| df | SS | MS | F | Значимость F | |
| Регрессия | 43,108 | 8,621706702 | 26,44856937 | 4,35085E-06 | |
| Остаток | 3,912 | 0,325980078 | |||
| Итого | 47,020 |
Таблица 4 Параметры модели
| Коэффи-циенты | Стандартная ошибка | t-стати-стика | P-Зна-чение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 66,599 | 2,321 | 28,692 | 1,996E-12 | 61,542 | 71,656 |
| Х1 – ВРП на душу населения | 0,005 | 0,003 | 2,038 | 0,064 | -0,0003 | 0,011 |
| Х2 – Уровень безработицы, % | -0,166 | 0,219 | -0,759 | 0,462 | -0,644 | 0,311 |
| Х3 – Среднедушевые денежные доходы, руб | -1,217E-05 | 6,123E-05 | -0,199 | 0,846 | -0,0001 | 0,000121 |
| Х4 - Коэффициент фондов | 0,345 | 0,147 | 2,345 | 0,037 | 0,0244 | 0,665 |
| Х5 - Количество врачей на 10000 человек населения | -0,001 | 0,027 | -0,041 | 0,968 | -0,061 | 0,059 |
Анализируя выходные данные, приходим к выводу, что за исключением Х4 фактора (коэффициента фондов) остальные коэффициенты регрессии незначимы при уровне значимости 0,05 (P-значения больше 0,05).
С другой стороны, высокое значение R2=0,917 и значимость уравнения в целом (F-значение, равное 4,35085E-06 меньше 0,05), указывают на то, что в модели присутствуют значимые переменные.
Для отбора факторов в модель регрессии и оценки их мультиколлинеарности, найдем матрицу парных коэффициентов корреляции с помощью функции Корреляция.
Таблица 5 Матрица парных коэффициентов корреляции
| (Y) | Х1 | Х2 | Х3 | Х4 | Х5 | |
| продолжительность жизни населения (Y) | ||||||
| Х1 – ВРП на душу населения | 0,920766831 | |||||
| Х2 – Уровень безработицы, % | -0,785939045 | -0,736233447 | ||||
| Х3 – Среднедушевые денежные доходы, руб | 0,904417495 | 0,957871205 | -0,777283564 | |||
| Х4 - Коэффициент фондов | 0,870441089 | 0,771214387 | -0,725161787 | 0,791207281 | ||
| Х5 - Количество врачей на 10000 человек населения | 0,370369621 | 0,407432303 | -0,03452217 | 0,344968715 | 0,392423205 |
Анализируя вышеуказанную матрицу, замечаем, что наиболее существенное влияние на фактор Y оказывают переменные:
X1 ( ),
),
X3 ( ),
),
X4 ( )
)
X2 ( ).
).
Кроме этого, существует тесная корреляционная связь между переменными:
X1 и X3 (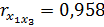 ),
),
X3 и X4 ( ),
),
X2 и X3 (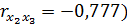 ,
,
X1 и X4 ( ,
,
X2 и X4 ( .
.
Поэтому при построении регрессии с использованием всех объясняющих переменных будет иметь место мультиколлинеарность.
Для устранения мультиколлинеарности применим процедуру пошагового отбора наиболее информативных переменных.
1-й шаг.
Из объясняющих переменных X1 – X5 выделяется переменная X1, имеющая с зависимой переменной Y наибольший коэффициент детерминации.
Воспользуемся функцией Регрессия для получения парной регрессии с участием переменных Y и X1. Ограничимся при этом выводом Регрессионной статистики:
Таблица 6 Регрессионная статистика
| Регрессионная статистика | |
| Множественный R | 0,920767 |
| R-квадрат | 0,847812 |
| Нормированный R-квадрат | 0,8383 |
| Стандартная ошибка | 0,668765 |
| Наблюдения |
Скорректированный коэффициент детерминации равен 0,838
2 шаг.
Среди всевозможных пар объясняющих переменных выбирается пара (X1,Х4), имеющая с зависимой переменной Y наиболее высокий скорректированный коэффициент детерминации, равный 0,899. Результаты расчетов приводятся ниже.
Таблица 7 Регрессионная статистика
| Регрессионная статистика | х1х2 | х1х3 | х1х4 | х1х5 |
| Множественный R | 0,93450508 | 0,924076 | 0,954593 | 0,920782 |
| R-квадрат | 0,873299745 | 0,853917 | 0,911249 | 0,847839 |
| Нормированный R-квадрат | 0,856406378 | 0,83444 | 0,899415 | 0,827551 |
| Стандартная ошибка | 0,630210721 | 0,6767 | 0,527454 | 0,690635 |
| Наблюдения |
3 шаг.
Среди всевозможных пар объясняющих переменных выбирается тройка переменных (х1х4х2), имеющая с зависимой переменной Y наиболее высокий скорректированный коэффициент детерминации, равный 0,899. Результаты расчетов приводятся ниже.
Таблица 8 Регрессионная статистика
| Регрессионная статистика | Х1Х4Х2 | Х1Х4Х3 | Х1Х4Х5 |
| Множественный R | 0,957355078 | 0,954612872 | 0,95540933 |
| R-квадрат | 0,916528745 | 0,911285735 | 0,912806987 |
| Нормированный R-квадрат | 0,898642048 | 0,892275535 | 0,89412277 |
| Стандартная ошибка | 0,529477031 | 0,545852601 | 0,541152285 |
| Наблюдения |
Шаг 4:
Так как скорректированный коэффициент детерминации на 3-м шаге не увеличился, то продолжать добавление факторов уже не нужно.
Среди всевозможных четверок объясняющих переменных, наиболее информативной оказалась та, которая имеет максимальный скорректированный коэффициент детерминации. НО! Если скорректированный коэффициент детерминации на 4-м шаге не увеличился, то в регрессионной модели достаточно ограничиться лишь тремя ранее объясняющими переменными X1Х4Х2.
Построим эту линейную регрессионную модель с помощью функции Регрессия:
Таблица 10 Регрессионная статистика
| Регрессионная статистика | |
| Множественный R | 0,957355078 |
| R-квадрат | 0,916528745 |
| Нормированный R-квадрат | 0,898642048 |
| Стандартная ошибка | 0,529477031 |
| Наблюдения |
Таблица 11 Дисперсионный анализ
| df | SS | MS | F | Значимость F | |
| Регрессия | 43,09545 | 14,36515 | 51,2408 | 8,54E-08 | |
| Остаток | 3,924843 | 0,280346 | |||
| Итого | 47,02029 |
Таблица 12 Параметры модели
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 66,4086036 | 1,949629 | 34,06218 | 7,21E-15 | 62,22707 | 70,59014 |
| х1 | 0,004667141 | 0,001095 | 4,263298 | 0,000788 | 0,002319 | 0,007015 |
| х4 | 0,337959129 | 0,125511 | 2,69267 | 0,017506 | 0,068765 | 0,607153 |
| х2 | -0,159522783 | 0,169514 | -0,94106 | 0,362629 | -0,52309 | 0,204048 |
Оцененное уравнение имеет вид:
 x1 + 0,338X4 - 0,16 Х2
x1 + 0,338X4 - 0,16 Х2
Проверим наличие гетероскедастичности остатков. Для получения результатов в диалоговом окне ввода параметров инструмента Регрессия нужно поставить флажок напротив «Остатки» и в Excel дополнительно будет выведены сведения:
Таблица 13 ВЫВОД ОСТАТКА
| Наблюдение | Предсказанное у | Остатки |
| 72,53615468 | 0,333845315 | |
| 70,99178397 | -0,071783972 | |
| 70,28963068 | -0,009630678 | |
| 72,4409681 | -0,3609681 | |
| 69,97144241 | 0,798557589 | |
| 71,40886664 | -0,228866636 | |
| 70,27450561 | 0,595494395 | |
| 71,31209109 | -0,372091089 | |
| 72,07742737 | -0,457427367 | |
| 72,67554926 | -0,175549262 | |
| 70,56764513 | 0,162354869 | |
| 70,99675351 | 0,873246492 | |
| 70,53577557 | -0,555775572 | |
| 71,54044957 | 0,569550428 | |
| 69,87597759 | -0,635977588 | |
| 71,18209852 | -0,622098517 | |
| 71,25110572 | -0,041105716 | |
| 76,88177459 | 0,198225409 |
Предсказанное  – это теоретические значения
– это теоретические значения 
Таким образом, во вспомогательных таблицах можно не рассчитывать столбцы  и
и  а использовать результаты регрессионного анализа.
а использовать результаты регрессионного анализа.
Из рис. 1, 2 и 3, на которых получены графики остатков  ,х4 и х2, видим, что расположение остатков не имеет направленности. Остаточные величины
,х4 и х2, видим, что расположение остатков не имеет направленности. Остаточные величины  не обнаруживают тенденцию по мере увеличения
не обнаруживают тенденцию по мере увеличения  и
и  Следовательно, есть равенство дисперсий остаточных величин, т.е. не наблюдается гетероскедастичности остатков. Следовательно, они независимы от значений
Следовательно, есть равенство дисперсий остаточных величин, т.е. не наблюдается гетероскедастичности остатков. Следовательно, они независимы от значений  значит построенная модель адекватна.
значит построенная модель адекватна.

Рис. 1. Результат применения инструмента Регрессия
(график остатков для переменной Х1)

Рис. 2. Результат применения инструмента Регрессия
(график остатков для переменной Х4)
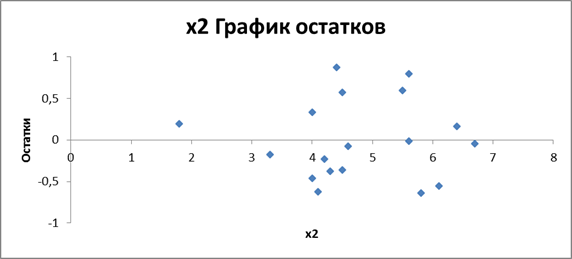
Рис. 3. Результат применения инструмента Регрессия
(график остатков для переменной Х2)
Кроме графического способа можно применить расчетный метод для определения наличия гетероскедастичности остатков.
Для применения теста Гольдфельда-Квандта упорядочим данные по фактору  Исключим из рассмотрения
Исключим из рассмотрения  = 8 центральных наблюдений. Разделим оставшуюся совокупность из 18-8=10 наблюдений на две группы (по 5) и определим по каждой из групп уравнение регрессии. Это легко сделать, используя результаты регрессионного анализа (в главном меню выбрать Сервис / Анализ данных / Регрессия и установить флажок напротив «Остатки»).
= 8 центральных наблюдений. Разделим оставшуюся совокупность из 18-8=10 наблюдений на две группы (по 5) и определим по каждой из групп уравнение регрессии. Это легко сделать, используя результаты регрессионного анализа (в главном меню выбрать Сервис / Анализ данных / Регрессия и установить флажок напротив «Остатки»).
Таблица 14 Расчет параметров теста Гольдфельда-Квандта
| Уравнения регрессии | у | х1 |
|
| 
|
Первая группа с первыми 5 наблюдениями: =72,798 - 0,01042 
| 70,77 | 165,5 | 71,0727 | -0,3027 | 0,09162635 |
| 70,92 | 219,6 | 70,50877 | 0,411228 | 0,16910873 | |
| 70,87 | 241,5 | 70,28049 | 0,589509 | 0,3475211 | |
| 70,28 | 255,4 | 70,1356 | 0,1444 | 0,02085131 | |
| 69,24 | 260,5 | 70,08244 | -0,84244 | 0,70970328 | |
Сумма 
| 1,34 | ||||
| Вторая группа с последними 5 наблюдениями: =69,428+0,007
| 72,08 | 352,9 | 71,8794 | 0,200603 | 0,040242 |
| 71,62 | 395,5 | 72,17527 | -0,55527 | 0,308326 | |
| 72,5 | 441,8 | 72,49684 | 0,003157 | 9,97E-06 | |
| 72,87 | 443,1 | 72,50587 | 0,364128 | 0,132589 | |
| 77,08 | 1103,5 | 77,09262 | -0,01262 | 0,000159 | |
Сумма 
| 0,5 |
Результаты расчетов сведем в табл. 14, вычислив  и суммы по каждой группе.
и суммы по каждой группе.
Величина  =
= 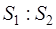 =0,5:1,34=0,36
=0,5:1,34=0,36  =19, при уровне значимости 0,05и числе степеней свободы
=19, при уровне значимости 0,05и числе степеней свободы  . Так как
. Так как  то гетероскедастичность остатков отсутствует.
то гетероскедастичность остатков отсутствует.
Таблица 15 Расчет параметров теста Гольдфельда-Квандта
| Уравнения регрессии | у | х3 |
|
|
|
| Первая группа с первыми 5 наблюдениями: =74,73 - 0,00018
| 70,28 | 70,50221 | -0,22221 | 0,049376 | |
| 70,73 | 70,43117 | 0,298832 | 0,089301 | ||
| 70,77 | 70,3494 | 0,4206 | 0,176905 | ||
| 69,24 | 70,31166 | -1,07166 | 1,148456 | ||
| 70,87 | 70,29557 | 0,574434 | 0,329975 | ||
| Сумма
| 1,794012 | ||||
| Вторая группа с последними 5 наблюдениями: =67,035+0,0001
| 71,18 | 71,69256 | -0,51256 | 0,262718 | |
| 72,08 | 71,8517 | 0,228299 | 0,05212 | ||
| 72,87 | 71,85333 | 1,01667 | 1,033617 | ||
| 72,5 | 73,63369 | -1,13369 | 1,285259 | ||
| 77,08 | 76,67872 | 0,401284 | 0,161029 | ||
| Сумма
| 2,794744 |
Результаты расчетов сведем в табл. 15, вычислив и суммы по каждой группе.
Величина = =2,79:1,79=1,56 =19, при уровне значимости 0,05и числе степеней свободы
Так как  то гетероскедастичность остатков отсутствует.
то гетероскедастичность остатков отсутствует.
Таблица 16 Расчет параметров теста Гольдфельда-Квандта
| Уравнения регрессии | у | х5 |
| 
| 
|
| Первая группа с первыми 5 наблюдениями: =53,179 + 0,496
| 70,28 | 33,9 | 70,00338 | 0,276618 | 0,076517 |
| 70,56 | 36,2 | 71,14489 | -0,58489 | 0,342092 | |
| 72,11 | 71,54193 | 0,568069 | 0,322702 | ||
| 70,87 | 37,1 | 71,59156 | -0,72156 | 0,520652 | |
| 72,5 | 72,03824 | 0,461762 | 0,213224 | ||
Сумма 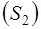
| 1,475188 | ||||
| Вторая группа с последними 5 наблюдениями: =7,021+ 1,249
| 72,08 | 50,9 | 70,57122 | 1,508785 | 2,276432 |
| 69,98 | 50,9 | 70,57122 | -0,59122 | 0,349535 | |
| 71,87 | 51,8 | 71,69489 | 0,175114 | 0,030665 | |
| 71,21 | 73,19311 | -1,98311 | 3,932741 | ||
| 77,08 | 55,4 | 76,18957 | 0,89043 | 0,792866 | |
Сумма 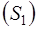
| 7,382239 |
Результаты расчетов сведем в табл. 16, вычислив  и суммы по каждой группе.
и суммы по каждой группе.
Величина = =7,38:1,48=4,99 =19, при уровне значимости 0,05и числе степеней свободы
Так как то гетероскедастичность остатков отсутствует.
Т.е. получили следующее уравнение множественной регрессии:
 x1 - 5,33E-05X3 + 0,002 Х5
x1 - 5,33E-05X3 + 0,002 Х5
Оно показывает, что при увеличении только ВРП на душу населения x1 (при неизменном x3 и х5) продолжительность жизни населения увеличивается на 0,005 года (≈2 дня), влияние среднедушевых денежных доходов на продолжительность жизни не измеримо мало, при этом количество врачей позволяет увеличить продолжительность жизни на 0,002 года ((≈1 день).
Найдем уравнение множественной регрессии в стандартизованном масштабе:

при этом стандартизованные коэффициенты регрессии будут
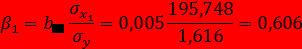


Т.е. уравнение будет выглядеть следующим образом:

Так как стандартизированные коэффициенты регрессии можно сравнивать между собой, то можно сказать, что ВРП на душу населения оказывает наибольшее влияние на продолжительность жизни.
Определим средние коэффициенты эластичности:

Находим по данным уравнения средние коэффициенты эластичности:



Т.е. при увеличении ВРП на 1% продолжительность жизни увеличивается на 0,025%, рост среднедушевых доходов на 1% приводит к росту продолжительности жизни 0,021% и рост количество врачей на 10000 человек населения на 1% способствует росту продолжительности жизни на 0,001%.
Из расчетов в таблице 10 следует, что совокупный коэффициент корреляции равен 0,924115. Т.е. можно сказать, что 85,4% (коэффициент детерминации R2=0,9242=0,854) вариации продолжительности возраста населения объясняется вариацией представленных в уравнении признаков, что указывает на весьма тесную связь признаков с результатом.
Оценим надежность уравнения регрессии в целом и показателя связи с помощью F-критерия Фишера. Фактическое значение F-критерия=27,2941 (табл.11). Табличное значение F -критерия при уровне значимости (α= 0,05, k1 = 3, k2 = 10-3-1 = 6): Fтабл=4,76. Так как Fфакт=127,29>Fтабл=4,76, то уравнение признается статистически значимым.