Пример 1: Текстовый файл состоит не более чем из 106 символов X, Y и Z. Определите максимальное количество идущих подряд символов, среди которых каждые два соседних различны.
Для выполнения этого задания следует написать программу. Дан файл, который необходимо обработать с помощью данного алгоритма.
Фрагмент файла (рис.)
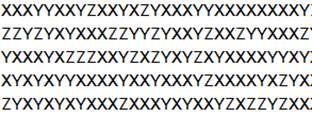
Рисунок – фрагмент файла 1
Решение: Текстовый файл следует рассматривать как последовательность, из которой будем читать элемент за элементом от первого до последнего, одновременно их обрабатывая.
Max – информация, хранимая во время обработки последовательности. K – элементы, среди которых нужно вычислить максимум, минимально_возможное_значение – начальное значение при вычислении максимума.
В данной задаче максимум вычисляется среди длин подряд идущих символов, среди которых соседние различны, то есть среди подпоследовательности символов.
Чтобы понять, что закончилась одна подпоследовательность и началась другая, нужно сравнивать текущий символ с предыдущим. Значит, необходимо хранить в информации max предыдущий символ Х1. Если новый поступивший символ Х и предыдущий Х1 отличаются, значит подпоследовательность «идущих подряд символов, среди которых каждые два соседних различны» продолжается, а если Х  Х1, то подпоследовательность закончилась символом Х, а Х1 - начало новой. Необходимо хранить величину К – текущая длина подпоследовательности и корректировать ее с учетом нового элемента Х. Если Х
Х1, то подпоследовательность закончилась символом Х, а Х1 - начало новой. Необходимо хранить величину К – текущая длина подпоследовательности и корректировать ее с учетом нового элемента Х. Если Х 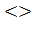 Х1, то Х1 относится к текущей подпоследовательности, значит К увеличиваем на 1, чтобы учесть Х. Если Х Х1, то началась новая подпоследовательность, длина которой 1 (элемент Х1), поэтому К
Х1, то Х1 относится к текущей подпоследовательности, значит К увеличиваем на 1, чтобы учесть Х. Если Х Х1, то началась новая подпоследовательность, длина которой 1 (элемент Х1), поэтому К  1.
1.
Но когда началась новая подпоследовательность, а старая закончилась, необходимо перед присвоением К 1 сравнить К и Max.
После завершения файла символов выполнить обработку имеющейся подпоследовательности длины К (ведь возможно именно она будет самой длинной). Для этого после цикла, обрабатывающего файл, нужно выполнить сравнение и корректировку «ЕСЛИ K 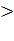 Max ТО Мах K;».
Max ТО Мах K;».
Алгоритм:
АЛГ Поиск максимума
| Поиск максимума длины подряд идущих подпоследовательностей,
в которых соседние символы различны
НАЧАЛО
Max:=0;
Х1:=’W’; любой символ который отличается от всех символов файла
К:=0; |начальное значение длины
ПОКА есть символы в файле
НЦ
Х:=очередной символ
ЕСЛИ X<>X1 ТО |подпоследовательность продолжается
К:=К+1 |увеличить длину текущей подпоследовательности
ИНАЧЕ | т.е. X=X1, это значит началась новая подпоследовательность, а старая (длины К) закончилась
| коррекция максимума
ЕСЛИ K>Max ТО Мах:=K;
ВСЕ
К:=1 | новая подпоследовательность {X}
ВСЕ
Х1:=X; | запомним символ Х, как предыдущий
КЦ
ЕСЛИ K>Max ТО Мах:=K;
ВСЕ
ВЫВОД «Ответ=», Max; |это вместо F:=Max;
КОНЕЦ
Запишем программу на языке Паскаль:
VAR f: file of char; {текущий файл}
Max, {текущий максимум среди длин подпоследовательностей}
K: integer; {длина текущей подпоследовательности}
X, X1: char; {текущий и предыдущий символы}
BEGIN
Max: =0; {начальное значение максимума (минимально возможное)}
X1: ='W'; {можно присвоить любой символ отличный от XYZ}
assign(f,'24.1.txt'); {задать имя файла}
reset(f); {открыть файл для чтения}
{пока есть символы}
while not eof(f) do begin
read(f,X); {взять очередной символ}
if X<>X1 then {подпоследовательность продолжается}
K:=K+1
Else begin
{т.е. X=X1, это значит началась новая подпоследовательность,
а старая (длины К) закончилась}
if K>Max then Max:=K; {коррекция максимума}
K:=1; {новая подпоследовательность}
end;
X1:=X; {запомним символ Х, как предыдущий }
end;{while}
close(f); {закроем файл,.т.к. он обработан}
{файл закончился, К=длина последней подпоследовательности. Необходимо ее учесть, то есть скорректировать максимум}
if K>Max then Max:=K; {коррекция максимума с учетом последней подпоследовательности}
writeln (Max); {Вывод результата}
END.
Результат будет «35». Если файл пуст, результат «0». Файл из одного символа «Х» дает результат 1. Для файла ХХ результат тоже 1, для файла XY результат 2.
Пример 2: текстовый файл состоит не более чем из 106 символов X, Y и Z. Определите длину самой длинной последовательности, состоящей из символов X. Хотя бы один символ X находится в последовательности.
Для выполнения этого задания следует написать программу. Дан файл, который необходимо обработать с помощью данного алгоритма.
Фрагмент файла (рис.)
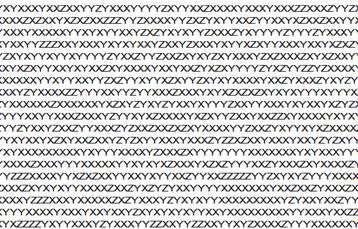
Рисунок – фрагмент файла 2
Решение: Текстовый файл следует рассматривать как последовательность, из которой будем читать элемент за элементом от первого до последнего, одновременно их обрабатывая.
Информация, хранимая во время обработки последовательности:
Max – длина наибольшей последовательности из Х в обработанной части файла; K – длина текущей последовательности из Х;
Необходимо корректировать величину К с учетом нового элемента Х. А после этого корректировать Max с учетом нового значения К.
Подпоследовательность из Х закончилась, если встретился символ Y или Z (не Х). Подпоследовательность началась, когда встретился символ Х, а до него был не Х. Если же очередной и предыдущий символы равны Х, то это продолжение текущей подпоследовательности.
Необходимо хранить предыдущий символ А1, который будем сравнивать с текущим символом А. Если А=А1=’Х’, то продолжается подпоследовательность из Х, увеличиваем ее длину на 1 (К:=К+1). Если А1=’Х’, но А  ’Х’, то подпоследовательность кончилась, необходимо сравнить ее длину К с текущим максимумом Max и при необходимости откорректировать максимум. Если А1 ’Х’, но А ’Х’, то началась новая подпоследовательность, необходимо поставить ее длину K 1.
’Х’, то подпоследовательность кончилась, необходимо сравнить ее длину К с текущим максимумом Max и при необходимости откорректировать максимум. Если А1 ’Х’, но А ’Х’, то началась новая подпоследовательность, необходимо поставить ее длину K 1.
После завершения файла символов нужно выполнить обработку имеющейся подпоследовательности длины К (возможно именно она будет самой длинной). Для этого после цикла, обрабатывающего файл, нужно выполнить сравнение и корректировку максимума.
Алгоритм:
АЛГ Поиск максимума
| Поиск самой длинной последовательности из символов Х
НАЧАЛО
Max:=0; |начальное значение максимума берем наименьшим
А1:=’Z’; |символ который отличается от Х
К:=0; |начальное значение длины
ПОКА есть символы в файле
НЦ
А:=очередной символ
ЕСЛИ А=’Х‘ ТО
ЕСЛИ А=А1 ТО |подпоследовательность продолжается
К:=К+1 |увеличим ее длину
ИНАЧЕ | А<>А1 и А=’X’ (началась новая)
К:=1 | в новой пока только 1 символ
ВСЕ
ИНАЧЕ | А<>’Х’
ЕСЛИ А1=’X’ ТО | последовательность кончилась
| коррекция максимума
ЕСЛИ K>Max ТО Мах:=K ВСЕ
К:=0
ВСЕ
| а если А и А1 не ’X’, то ничего не делаем
ВСЕ
А1:=А; | запомним символ А, как предыдущий
КЦ
|обработка последней последовательности
ЕСЛИ K>Max ТО Мах:=K; ВСЕ
ВЫВОД «Ответ=», Max;
КОНЕЦ
Напишем программу на языке Паскаль:
PROGRAM MaxX;
VAR f: file of char; {текущий файл}
Max, {текущий максимум среди длин подпоследовательностей}
K: integer; {длина текущей подпоследовательности}
A, A1:char; {текущий и предыдущий символы}
BEGIN
Max:=0; {начальное значение максимума (минимально возможное)}
A1:='Z'; {можно присвоить любой символ отличный от X}
assign(f,'24.2.txt');{задать имя файла}
reset(f);{открыть файл для чтения}
{пока есть символы}
while not eof(f) do begin
read(f,A); {взять очередной символ}
if A='Х' then begin
if A=A1 then {подпоследовательность продолжается}
K:=K+1{увеличим ее длину}
else { А<>А1 и А=’X’ (началась новая)}
K:=1; { в новой пока только 1 символ}
End
else { А<>’Х’}
if A1='X' then begin {последовательность кончилась}
{коррекция максимума}
if K>Max then Max:=K;
K:=0
end;
{ а если А и А1 не ’X’, то ничего не делаем}
A1:=A; {запомним символ А, как предыдущий }
end;{while}
close(f); {закроем файл,.т.к. он обработан}
{файл закончился, К=длина последней подпоследовательности. Необходимо ее учесть, то есть скорректировать максимум}
if K>Max then Max:=K; {коррекция максимума с учетом последней подпоследовательности}
writeln(Max); {Вывод результата}
END.
Для файла 24.2.txt получается ответ 19.
Пример 3: текстовый файл содержит только заглавные буквы латинского алфавита (ABC…Z). Определите символ, который чаще всего встречается в файле сразу после буквы E.
Например, в тексте EBCEEBEDDD после буквы E два раза стоит B, по одному разу — E и D. Для этого текста ответом будет B.
Для выполнения этого задания следует написать программу. Дан файл, который необходимо обработать с помощью данного алгоритма.
Фрагмент файла (рис.)

Рисунок – фрагмент файла 3
Решение: заведем массив счетчиков для каждой буквы А-Z. В этом массиве будем для каждой буквы считать, сколько раз она встречается, когда идет после символа Е. В начале программы все элементы массива нужно обнулить.
Последовательно будем читать из файла по одному символу, если предыдущий символ был Е, то увеличим счетчик текущего символа на 1. Если предыдущий символ не был Е, то счетчики не меняем. На каждой итерации цикла, нужно знать какой символ был до этого. Поэтому в переменной А1 в конце итерации запоминаем текущий символ, чтобы знать на следующей итерации, какой был предыдущий.
После перебора всех символов в файле, нужно найти максимум в массиве счетчиков Count. Это делается с помощью поиска максимума. Последовательность А-Z явно не пуста, за начальное значение максимума примем первый элемент, то есть счетчик для буквы ‘A’. Соответственно, за символ, соответствующий этому максимуму, возьмем MaxA=’A’. После этого перебираем счетчики всех оставшихся символов и корректируем Max и MaxA, если очередной счетчик превышает максимум. В задании не сказано, какой должен быть ответ, если несколько символов имеют одинаковое максимальное число повторений. Выведем в этом случае первый по алфавиту из таких символов. Это получается из-за строго условия:
if Count[A]>Max then
Если бы нужно было из таких символов выдать последний по алфавиту, можно было бы поставить нестрогое условие:
if Count[A]>=Max then
Ответом является символ MaxA.
АЛГ Поиск символа
| Поиск символа, который чаще других встречается после Е
НАЧАЛО
|обнуление счетчиков Count[‘A’:’Z’]
ЦИКЛ А:=’A’ ДО ‘Z’ НЦ Count[A]:=0 КЦ
А1:=’А’; |любой символ который отличается от Е
ПОКА есть символы в файле
НЦ
А:=очередной символ
ЕСЛИ А1=’E‘ ТО |если предыдущий Е
Count[A]:= Count[A]+1;|увеличим счетчик буквы
ВСЕ
А1:=А; | запомним символ А, как предыдущий
КЦ
Max:=Count[‘A’]; |начальное значение максимума
MaxA:= 'A'; | соответствующий максимуму символ
|цикл по всем остальным элементам массива
ЦИКЛ А:=’B’ ДО ‘Z’
НЦ
| коррекция максимума
ЕСЛИ Сount[A]>Max ТО
Мах:=Count[A]; {новый максимум}
MaxA:=A; {новый символ, соответствующий максимуму}
ВСЕ
КЦ
ВЫВОД «Ответ=», А;
КОНЕЦ
Запишем программу на языке Паскаль:
VAR f: file of char; {текущий файл}
{счетчик букв, стоящих после Е}
Count: array ['A'..'Z'] of integer;
Max: integer; {текущий максимум среди счетчиков букв}
MaxA: char; {символ, соответствующий максимуму}
A, A1:char; {текущий и предыдущий символы}
BEGIN
{обнуление счетчиков}
for A:='A' to 'Z' do Count[A]:=0;
A1:='A'; {можно присвоить любой символ отличный от E}
assign(f,'24.3.txt');{задать имя файла}
reset(f);{открыть файл для чтения}
{пока есть символы}
while not eof(f) do begin
read(f,A); {взять очередной символ}
if A1='E' then {предыдущий Е}
Count[A]:=Count[A]+1; {увеличить счетчик этой буквы на 1}
A1:=A; {запомним символ А, как предыдущий }
end;{while}
close(f); {закроем файл,.т.к. он обработан}
{файл закончился,
в массиве Count - количество повторений каждого символа, идущего после Е}
{найдем максимум в массиве Count}
Max:=Count['A'];{начальное значение максимума возьмем равным 1-му элементу}
MaxA:='A'; {соответствующий максимуму символ}
{цикл по остальным элементам}
for A:='B' to 'Z' do {коррекция максимума}
if Count[A]>Max then begin
Max:=Count[A]; {новый максимум}
MaxA:=A; {запоминаем символ для максимума}
end;
{ Max - максимальное число повторений, MaxA - соответствующий символ.
Если есть несколько символов с повторениями Max, то меньший по алфавиту.}
writeln(MaxA); {Вывод результата}
END.
Для файла 24.3.txt программа выдает ответ Y. Это значит, что чаще всего после Е встречается Y.