Глядя на компьютер, стоящий на столе, пользователь обычно видит монитор, клавиатуру, мышь и системный блок, под крышкой которого спрятаны узлы, обеспечивающие функционирование машины. Структура типичного ПК представлена на рисунке 1:

Рисунок 1. Структура ПК
Далее мы подробно разберем каждый из компонентов ПК. Начнем с материнской платы:

Рисунок 2. Структура материнской платы
Материнская плата
Материнская плата – это печатная плата с набором чипов, на которой осуществляется монтаж большинства компонентов компьютерной системы посредством различных разъёмов. Название происходит от английского motherboard, иногда используется сокращение MB или словосочетание main board — главная плата. Обычно на материнской плате располагаются разъёмы для подключения центрального процессора, графической платы, звуковой платы, жёстких дисков, оперативной памяти и других дополнительных периферийных устройств.
Все основные электронные схемы компьютера и необходимые дополнительные устройства встраиваются в материнскую плату, или подключаются к ней с помощью слотов расширения. Наиболее важной частью материнской платы является чипсет, состоящий, как правило, из двух частей — северного моста (Northbridge) и южного моста (Southbridge). Почему «северный» и «южный»? Потому, что на структурной схеме материнской платы процессор, как правило, изображают сверху, там, где на географических картах находится север. Процессор осуществляет всю работу с остальными устройствами именно через северный мост, который располагается рядом с ним. Южный мост отвечает за работу с «второстепенной» периферией и изображается снизу. Обычно северный и южный мосты выполнены в виде отдельных микросхем. Именно северный и южный мосты определяют, в значительной степени, особенности материнской платы и то, какие устройства могут подключаться к ней.
Современная материнская плата ПК, как правило, включает в себя чипсет, согласующий работу центрального процессора и составных частей компьютера (ОЗУ, ПЗУ и портов ввода/вывода), слоты расширения форматов PCI Express, PCI, AGP, ISA а также, обычно, USB, SATA и IDE/ATA контроллеры. Большинство устройств, которые могут присоединяться к материнской плате, присоединяются с помощью одного или нескольких слотов расширения или сокетов, а некоторые современные материнские платы поддерживают беспроводные устройства, использующие протоколы IrDA, Bluetooth, или 802.11 (Wi-Fi).
Форм-фактор материнской платы — стандарт, определяющий размеры материнской платы для персонального компьютера, места ее крепления к корпусу; расположение на ней интерфейсов шин, портов ввода/вывода, сокета центрального процессора (если он есть) и слотов для оперативной памяти, а также тип разъема для подключения блока питания. Форм-фактор (как и любые другие стандарты) носит рекомендательный характер, однако подавляющее большинство производителей предпочитают его соблюдать, поскольку ценой соответствия существующим стандартам является совместимость материнской платы и стандартизированного оборудования (периферии, карт расширения) других производителей. Существует довольно большое количество разнообразных форм-факторов материнских плат, некоторые из них уже вышли из употребления, а некоторые только начинают применяться.
· Устаревшими считаются форм-факторы: Baby-AT; Mini-ATX; полноразмерная плата AT; LPX.
· Современными считаются: АТХ; microATX; Flex-АТХ; NLX; WTX.
· Внедряемыми считаются: Mini-ITX и Nano-ITX; Pico-ITX; BTX, MicroBTX и PicoBTX
Существуют материнские платы, не соответствующие никаким из существующих форм-факторов. Обычно это обусловлено либо тем, что производимый компьютер узко специализирован, либо желанием производителя материнской платы самостоятельно производить и периферийные устройства к ней, либо невозможностью использования стандартных компонентов (так называемый «брэнд», например Apple Computer, Commodore, Silicon Graphics, Hewlett Packard, Compaq чаще других игнорировали стандарты; кроме того, в нынешнем виде распределённый рынок производства сформировался только к 1987 г., когда многие производители уже создали собственные платформы).
Центральный процессор
CPU – Central Processing unit – центральный процессор – «сердце» ЭВМ. Он осуществляет вычисления по хранящейся в ОЗУ программе и обеспечивает общее управление компьютером.
Эволюция процессоров Intel, применяемых в ПК, происходила следующим образом. Процессор i8088, родоначальник большинства процессоров для персональных компьютеров, состоял из 29 тысяч транзисторов, производился по 3-микронной технологии и имел общую площадь подложки 33 мм2.
Улучшение технологии производства микропроцессоров позволило значительно повысить их тактовую частоту. Каждое новое поколение процессоров имеет более низкое напряжение питания и меньшие токи, что способствует уменьшению выделяемого ими тепла. Но самым главным достижением явилось то, что при уменьшении нормы технологического процесса появилась возможность значительно увеличить количество транзисторов на одном кристалле. Большее количество транзисторов, входящих в состав процессора, позволяет усовершенствовать архитектуру процессора с целью достижения еще большей производительности. Даже разрядность процессоров очень быстро увеличилась с 4 в первом процессоре (i4004, первый процессор Intel, не применялся в ПК, а был разработан по заказу фирмы Busycom для производимого ей программируемого калькулятора) до 32 в процессоре i386.
Значительной вехой в истории развития архитектуры процессоров персональных компьютеров стало появление процессора i486. Производственный техпроцесс к тому времени достиг отметки в 1 мкм, благодаря чему удалось расположить в ядре процессора 1,5 млн. транзисторов, что было почти в 6 раз больше, чем у CPU предыдущего 386-го поколения. Это позволило внедрить в архитектуру процессора поистине революционные изменения:
· В архитектуре процессора персонального компьютера впервые появился конвейер на пять стадий. Конвейерные вычисления были, конечно, известны задолго до появления персональных компьютеров, но высокая степень интеграции теперь позволила применить этот эффективный способ вычислений и в персональном компьютере.
· На одном кристалле Intel разместила и собственно процессор, и математический сопроцессор, и кэш-память L1 (подробнее о кэш-памяти см. далее), которые до этого располагались в отдельных микросхемах.
Эта революция произошла спустя 20 лет после появления первого микропроцессора, в октябре 1989 года.
486-й микропроцессор обладал достаточным для того времени быстродействием. Компьютеры с такими процессорами в некоторых случаях используются и в настоящее время. Тактовая частота процессора даже превысила тактовую частоту системной шины.
С момента выпуска 486-го процессора технологический процесс производства микропроцессоров начал развиваться бурными темпами.
Процессор следующего поколения, Pentium, появился уже не через десятилетия, а меньше чем через 4 года, в марте 1993.
Создание процессора следующего поколения стало возможным благодаря переходу на новый техпроцесс – 0,8 мкм, следствием чего явилось увеличение числа транзисторов до 3,1 млн. Основные особенности процессора:
· Ядро нового CPU включало уже два 5-стадийных конвейера для операций над целыми числами, позволяющих выполнить две инструкции за такт, и 8-стадийный конвейер для операций с плавающей запятой, что почти удваивало его вычислительные возможности по сравнению с 486-м процессором аналогичной частоты.
· Удлинение конвейера позволило увеличить тактовую частоту, хотя и создало некоторые проблемы, связанные с предсказанием ветвления выполняемых команд. Для решения этих проблем на кристалле расположили специальный буфер, Branch Target Buffer, с помощью которого реализован механизм динамического предсказания ветвления. Когда по мере исполнения внутренних инструкций встречалось ветвление (IF...ELSE или CASE 1...CASE N), в буфере запоминалась эта команда и адрес перехода. Эти данные использовались для предсказания перехода при повторном выполнении данной инструкции.
Таким образом, Pentium по всем параметрам превосходил своего предшественника – 486-й, что и предопределило применение архитектуры Pentium в процессорах до настоящего времени.
Следующей моделью, выпущенной Intel, стал процессор Pentium Pro. Его основные отличия от процессоров предыдущих поколений:
· Количество стадий конвейера для целочисленных операций увеличено с 5 до 14.
· Реализован механизм выполнения инструкций с нарушением очередности их следования (так называемое спекулятивное ветвление), что позволило Pentium Pro просматривать до 18 инструкций вперед и обрабатывать их в зависимости от их готовности, а не от порядка следования в программе.
· В одном корпусе с процессором реализован кэш второго уровня
Процессор Pentium Pro стал родоначальником процессоров Pentium шестого поколения. Однако изготовление процессоров такой архитектуры по технологии 0,5 мкм было очень дорого, поэтому процессор Pentium Pro использовался практически только в высокопроизводительных серверах.
Только с переходом на технологию 0,35 мкм процессоры шестого поколения нашли широкое применение. Первым в этой серии был процессор Pentium II. Правда, кэш второго уровня так и остался в виде отдельной микросхемы (хотя находился внутри корпуса процессора). Более того, кэш работал на частоте в два раза меньшей, чем ядро процессора. Тем не менее, это был серьёзный шаг в повышении производительности, и к тому же цена процессора оказалась доступной для большинства покупателей.
При переходе на 0,25-микронный техпроцесс появился новый процессор, Pentium III, в котором было достаточно много усовершенствований, однако кэш второго уровня всё ещё работал на половинной частоте ядра процессора.
Только с появлением процессора Pentium III Coppermine, изготавливаемого по 0,18-микронной технологии, кэш второго уровня переместился в ядро процессора и стал работать на частоте ядра. Самый совершенный на сегодняшний день процессор семейства Pentium, Pentium 4, изготавливается по 0,09-микронной технологии.
Ядро нового процессора было практически полностью переработано. Совокупность технических решений, применённых в процессоре Pentium 4, даже получила собственное название: «архитектура NetBurst».
Таким образом, со времени появления первого микропроцессора норма технологического процесса уменьшилась примерно в 33 раза. За это же время количество транзисторов в процессоре увеличилась в 18 000 раз, а тактовая частота – почти в 14 000 раз.
Внутреннее устройство микропроцессора. На рисунке 3 в качестве примера изображена структурная схема микропроцессора Intel Pentium II. Ее полный анализ выходит за рамки этого курса, однако на некоторых блоках следует остановиться подробнее.
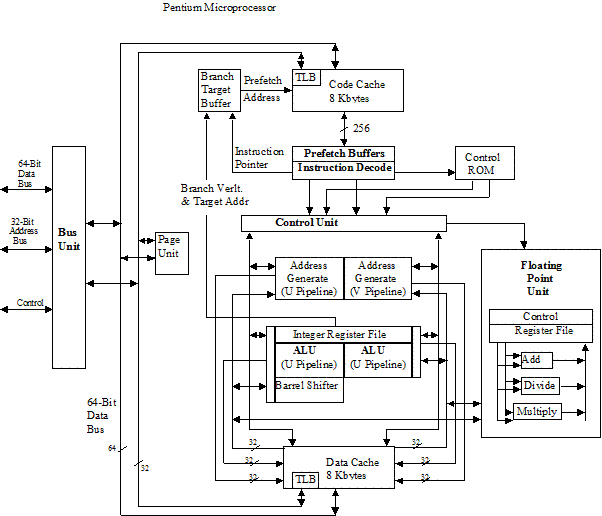
Рисунок 3. Структурная схема процессора Pentium II
· Bus Unit. Этот модуль отвечает за взаимодействие процессора с чипсетом. Он согласовывает интерфейс FSB (Front Side Bus – наружная шина процессора) с внутренними линиями передачи данных, адреса и управляющих сигналов.
· Code Cache и Data Cache – внутренние кэши команд и данных. Все обращения к подсистеме основной памяти проходят через эти два блока. Подробнее о том, что такое кэш и зачем он нужен см. раздел «Основная память»
· Prefetch Buffers – очереди буферов предварительной выборки команд и Instruction Decode – блок декодирования команд. Этот блок отвечает за конвейеризацию выполнения программы.
· Control Unit – устройство управления. Именно в нем выполняются команды.
· ALU – арифметико-логическое устройство для выполнения операций над целыми числами.Pentium II содержит два целочисленных АЛУ – по одному на каждый целочисленный конвейер.
· Floating Point Unit – математический сопроцессор – устройство для выполнения операций над числами с плавающей запятой.
Большая часть структурной схемы (все, что находится справа от блока Bus Unit) называется процессорным ядром. Процессоры Intel, начиная с модели Pentium 4, могут содержать на одном кристалле несколько ядер, что позволяет распараллеливать вычисления на более высоком уровне, чем это позволяют делать несколько конвейеров в пределах одного ядра.
Основная память
Main memory – RAM – Random Access Memory – оперативная память, запоминающее устройство, непосредственно связанное с процессором и хранящее программы, выполняемые в текущий момент и данные, необходимые для их выполнения.
Сейчас в персональных компьютерах в качестве оперативной памяти применяются в основном различные разновидности так называемой динамической памяти (DRAM). Ячейки памяти в микросхеме DRAM - это крошечные конденсаторы, которые удерживают заряды. Именно наличием или отсутствием заряда кодируются биты. Основная проблема такой организации памяти в том, что ее содержимое нуждается в постоянной регенерации, так как в противном случае заряды с конденсаторов "стекают" и данные теряются. Регенерация происходит, когда контроллер памяти системы (встроенный обычно в чипсет) берет перерыв и обращается ко всем строкам данных в микросхеме памяти. Регенерация, естественно, занимает время, когда происходит регенерация памяти, процессор фактически ждет, ничего полезного не делая. Чем быстрее происходит регенерация, тем меньше процессорного времени теряется и тем производительнее работает система.
В DRAM для хранения одного бита данных используется только один транзистор и один конденсатор, поэтому по технологии DRAM возможно производить достаточно компактные чипы с немалой емкостью. Например, сегодня существуют чипы, базирующиеся на технологии DRAM емкостью 512 Мбит, т.е. они содержат 1/2 миллиарда транзисторов (Вы помните, что количество транзисторов в современных процессорах измеряется десятками миллионов). Но структура чипа DRAM весьма проста, представляя собой двумерную матрицу, в отличие от сложной архитектуры современного процессора. Итак, основное достоинство динамической памяти - немалая емкость при малых физических размерах чипа и небольшая цена. Применяемые в первых компьютерах и применяемые сегодня архитектуры памяти базируются в основном на динамической памяти. Давайте рассмотрим разновидности DRAM, нашедшие применение в PC, их достоинства и недостатки.

Рисунок 4. Внутренняя организация DRAM
Ячейки памяти организованы в матрицу, состоящую из строк и столбцов. Полный адрес ячейки данных включает два компонента — адрес строки (row Адрес, бит) и адрес столбца (column Адрес, бит). На рисунке представлена матрица, состоящая из 32 строк и 32 столбцов, то есть из 1024 ячеек.
Когда CPU (или устройство, использующее канал прямого доступа к памяти) обращается к памяти для чтения информации, на входы микросхемы поступает строб вывода данных ОЕ (Output Enabled), затем подается адрес строки и одновременно с ним (или с задержкой) сигнал RAS (Row Адрес, бит Strobe). Это означает, что каждая шина столбца соединяется с ячейкой памяти выбранной строки. Адрес ячейки поступает по адресным линиям (в нашем случае их десять) на дешифратор, который преобразует поступивший набор нулей и единиц в номер строки. Емкость конденсатора очень мала (доли пикофарады) и его заряд тоже мал, поэтому используется усилитель, подключенный к каждой шине столбца динамической памяти. Информация считывается со всей строки запоминающих элементов одновременно и помешается в буфер ввода-вывода.
С незначительной задержкой после сигнала RAS на входы динамической памяти подается адрес столбца и сигнал CAS (Column Адрес, бит Strobe). При чтении данные выбираются из буфера ввода-вывода и поступают на выход динамической памяти в соответствии с адресом столбца.
При считывании информации из ячеек памяти происходит ее разрушение, поэтому производится перезапись считанной информации: выходы регистра строки снова соединяются с общими шинами столбцов памяти, чтобы перезаписать считанную информацию из строки. Если ячейка имела заряд, то она снова будет заряжена еще до завершения цикла чтения. На ячейки, которые не имели заряда, напряжение не подается.
Если выполняется запись в память, то подается строб записи WE (Write Enable) и информация поступает на соответствующую шину столбца не из буфера, а с входа памяти в соответствии с адресом столбца. Таким образом, прохождение данных при записи задается комбинацией сигналов, определяющих адрес столбца и строки, а также сигналом разрешения записи данных в память.
FPM DRAM. Следующей нашедшей применение в PC модификацией DRAM, была память, которая работала в так называемом быстром страничном режиме и ее принято называть FPM DRAM (Fast Page Mode DRAM) или просто FPM. Чтобы сократить время ожидания на выборку данных (на доступ), стандартная DRAM разбивается на страницы. Обычно для доступа к данным в памяти требуется указать строку и столбец адреса, что занимает некоторое время. Разбиение на страницы обеспечивает более быстрый доступ ко всем данным в пределах данной строки памяти, т.е. если изменяется лишь номер столбца, но не номер строки.
Страничная организация памяти - простая схема повышения эффективности, в соответствии с которой память разбивается на страницы от 512 байт до нескольких килобайт. Соответствующая схема обращения позволяет в пределах страницы уменьшить количество состояний ожидания.
Чтобы увеличить скорость доступа к памяти, был разработан так называемый пакетный (burst) режим доступа. Преимущества пакетного режима доступа проявляются тогда, когда доступ к памяти является последовательным (т.е. считывание происходит последовательно одно за другим из соседних ячеек). После задания строки и столбца и считывания информации, к следующим трем соседним адресам можно обращаться без дополнительных циклов ожидания. Однако доступ в таком пакетном режиме ограничивается лишь четырьмя операциями чтения-записи, затем необходимо снова полностью адресоваться к строке и столбцу.
Принято говорить о схеме синхронизации доступа в пакетном режиме в виде x-y-y-y, где х - количество тактов ожидания для произведения чтения первого адреса, а затем y - количество тактов ожидания для чтения каждого следующего адреса в пакетном режиме.
Архитектура DRAM такова, что для получения доступа в первый раз необходимо 5 тактов ожидания. Если не разбивать память на страницы и не пользоваться пакетным режимом доступа, то каждая следующая операция получения доступа к следующей ячейке памяти тоже будет занимать 5 тактов ожидания. Однако если пользоваться разбиением на страницы и режимом burst, то, получив доступ первый раз, потратив на это 5 тактов ожидания, содержимое следующих ячеек можно считать, потратив на это лишь по три такта ожидания, т.е. в режиме FPM схема доступа имеет вид не 5-5-5-5, как у обычной DRAM, а 5-3-3-3. В этом и состоит преимущество памяти типа FPM перед обычной DRAM. Т.е. использование памяти типа FPM позволяет при той же частоте работы чипов памяти увеличить производительность обмена за счет сокращения времени на получение доступа к памяти.
EDO DRAM. Начиная с 1995 года, в PC используется новый тип оперативной памяти - EDO (Extended Data Out). Это усовершенствованный тип памяти FPM, у него было еще одно название, которое сейчас не используется – Hyper Page Mode. Микросхемы памяти EDO учитывают перекрытие синхронизации между очередными операциями доступа. За счет этого удается частично совместить по времени следующий цикл чтения с предыдущим, т.е. чипсет при работе с EDO памятью может начать выполнение новой команды выборки столбца, пока данные считываются по текущему адресу, за счет чего еще уменьшаются задержки на получение доступа.
Для оперативной памяти EDO схема синхронизации в пакетном режиме имеет вид 5-2-2-2, т.е. на четырех операциях считывания тратится не 14, а 11 тактов. Т.е. налицо явный прирост производительности, в то время как стоимость чипов типа EDO лишь немного отличалась от чипов FPM.
Пока что все рассмотренные нами архитектуры были лишь вариантами оригинальной DRAM, отличаясь схемой доступа в пакетном режиме, что, конечно, давало соответствующий прирост производительности. Частоты, на которых функционировала память перечисленных типов примерно таковы: DRAM функционировала с частотой от 4,77 МГц (в первых PC) до 10-12 МГц. Затем начала применяться память типа FPM, ее частота функционирования составляла 10-40 МГц в 386 системах, 25-50 МГц в 486 системах и 50-66 МГц в Pentium системах. Память типа EDO применялась наряду с FPM в 486 и Pentium системах на аналогичных частотах.
SDRAM. Уже начиная с 1997 года на смену памяти типа FPM и EDO приходит новый тип оперативной памяти: SDRAM (Synchronous DRAM) - синхронная DRAM. Эффективность SDRAM намного выше, чем у ее предшественников. Во-первых, дело в том, что схема пакетного чтения у SDRAM намного эффективнее, чем у EDO или FPM и описывается формулой 5-1-1-1. Т.е. для считывания четырех значений подряд задержка для памяти типа FPM составит 5+3+3+3=14 тактов, у EDO 5+2+2+2=11 тактов, а у SDRAM 5+1+1+1=8 тактов.
Но это еще не все. Дело в том, что SDRAM более технологична, чем ее предшественники, и ее проще изготовить для работы на более высоких частотах. И если впервые SDRAM применяли в PC на частоте 66 МГц (как и EDO и FPM в то время), то затем были разработаны чипы SDRAM, работающие на частоте 100 МГц, а после и 133 МГц.
DR DRAM (Rambus). Начиная с 1999 года, Intel продвигает на рынок принципиально новый тип памяти - DR DRAM(Direct Rambus DRAM), который был разработан по их заказу небольшой исследовательской фирмой Rambus.
Обычные типы памяти (FPM/RDO и SDRAM) иногда называют системами с широким каналом. Ширина канала памяти равна ширине шины данных процессора (в системах Pentium 64-бит). Максимальная производительность памяти DIMM SDRAM PC100 составляет 100x8 (частота х количество передаваемых данных за один такт), или 800 Мбайт/с. Микросхемы RDRAM увеличивают пропускную способность памяти — в них предусмотрена 16-разрядная шина передачи данных, частота увеличена до 800 МГц. а пропускная способность равна 1,6 Гбайт/с. Для увеличения производительности используются двух- и четырехканальные RDRAM. которые позволяют увеличить скорость передачи данных до 3,2 или 6,4 Гбайт/с соответственно.
Один канал памяти Rambus принципиально может поддерживать до 32 отдельных устройств RDRAM (микросхем RDRAM), которые устанавливаются в модули RIMM (Rambus Inline Memory Modules). Вся работа с памятью организуется между контроллером памяти и отдельным (а не всеми) устройством. Каждые 10нс (100МГц) одна микросхема RDRAM может передавать 16 байт. RDRAM работает быстрее SDRAM приблизительно в три раза. Для увеличения производительности было предложено еще одно конструктивное решение: передача управляющей информации отделена от передачи данных по шине. Для этого предусмотрены независимые схемы управления, а на адресной шине выделены две группы контактов: для команд выбора строки и столбца и для передачи данных по фронтам тактового сигнала, т.е. дважды в тактовом импульсе (практически в режиме DDR). Правая граница тактового импульса называется четным циклом, а левая — нечетным. Синхронизация осуществляется с помощью передачи пакетов данных в начале четного цикла. Максимальное время ожидания составляет 2,5 нс.
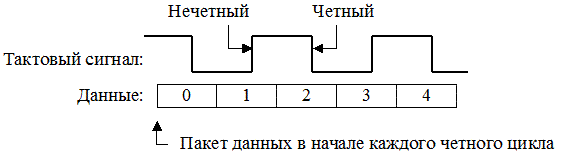
Рисунок 5. DDR
На рисунке показано отношение между тактовым сигналом и циклами передачи данных. Пять полных циклов тактового сигнала соответствуют десяти циклам данных. Однако в настоящее время применение этого типа памяти в ПК прекращено, он вытеснен следующим:
DDR SDRAM. DDR (Double Data Rate) SDRAM по многим параметрам и способам изготовления мало чем отличается от обычной SDRAM: та же синхронизация шины памяти с системной шиной, практически то же производственное оборудование, энергопотребление, почти не отличающееся от SDRAM, площадь чипа больше лишь на несколько процентов. Это позволило сразу без значительных материальных и временных издержек создать новую быстродействующую память, причем по цене, мало отличающейся от обычной SDRAM (кстати, DDR SDRAM раньше иногда именовали SDRAM-II). От RDRAM этот тип памяти унаследовал способность передавать данные, пользуясь обоими фронтами тактового сигнала.
Так как DDR SDRAM основывается на обычной SDRAM, то она имеет сопоставимые характеристики задержек, и поэтому зачастую работает быстрее RDRAM, у которой как раз имелись ощутимые проблемы с латентностью.
Увеличение быстродействия микросхем памяти – не единственный способ увеличения быстродействия подсистемы памяти вообще. Для ускорения обмена с RAM может применяться, в частности, метод чередования банков. Сущность этого метода состоит в том, что вся оперативная память компьютера разбивается на некоторое количество (четное) банков, доступ к которым осуществляется параллельно и независимо. Так, например, во время чтения данных из первого банка во втором может происходить операция установки адреса. Другой способ существенно повысить скорость обмена данными с RAM заключается в использовании кэша.
Что такое кэш и зачем он нужен? Cache (запас) обозначает быстродействующую буферную память (обычно статического типа) между процессором и основной памятью. Поскольку скорость работы CPU традиционно превышает скорость работы подсистемы памяти, процессор при выборке из памяти команд и данных вынужден был простаивать, ожидая, когда контроллер RAM выставит на шине содержимое необходимой ячейки или запишет данные в память.
Кэш служит для частичной компенсации разницы в скорости процессора и основной памяти - туда попадают наиболее часто используемые данные. Когда процессор первый раз обращается к ячейке памяти, ее содержимое параллельно копируется в кэш, и в случае повторного обращения в скором времени может быть с гораздо большей скоростью выбрано из кэша. При записи в память значение попадает в кэш, и либо одновременно копируется в память (схема Write Through - прямая или сквозная запись), либо копируется через некоторое время (схема Write Back - отложенная или обратная запись). При обратной записи, называемой также буферизованной сквозной записью, значение копируется в память в первом же свободном такте, а при отложенной (Delayed Write) - когда для помещения в кэш нового значения не оказывается свободной области. При этом в память вытесняются наименее используемая область кэша. Вторая схема более эффективна, но и более сложна за счет необходимости поддержания соответствия содержимого кэша и основной памяти. Сейчас под термином Write Back в основном понимается отложенная запись, однако это может означать и буферизованную сквозную. Память для кэша состоит из собственно области данных, разбитой на блоки (строки), которые являются элементарными единицами информации при работе кэша, и области признаков (tag), описывающей состояние строк (свободна, занята, помечена для дозаписи и т.п.). В основном используются две схемы организации кэша: с прямым отображением (direct mapped), когда каждый адрес памяти может кэшироваться только одной строкой (в этом случае номер строки определяется младшими разрядами адреса), и n-связный ассоциативный (n-way associative), когда каждый адрес может кэшироваться несколькими строками. Ассоциативный кэш более сложен, однако позволяет более гибко кэшировать данные; наиболее распространены 4-связные системы кэширования. Процессоры 486 и выше имеют также внутренний (Internal) кэш объемом 8-16 Кб. Он также обозначается как Primary (первичный) или L1 (Level 1 - первый уровень) в отличие от внешнего (External), расположенного на плате и обозначаемого Secondary (вторичный) или L2. В большинстве старых процессоров внутренний кэш (если он был) работал по схеме с прямой записью. Начиная с i486 (последние DX4-100, AMD DX4-120, 5x86) он может работать и с отложенной записью (последнее требует специальной поддержки со стороны системной платы, чтобы при обмене по DMA можно было поддерживать согласованность данных в памяти и внутреннем кэше). Начиная с Pentium Pro, процессоры Intel имеют также встроенный кэш второго уровня объемом от 256 Кб.
BIOS
BIOS – Base Input-Output System – базовая система ввода-вывода – программное обеспечение, хранящееся в ROM – Read Only Memory – постоянном запоминающем устройстве. BIOS содержит программу начальной проверки оборудования компьютера и загрузки операционной системы. Также в ROM хранятся подпрограммы обслуживания клавиатуры, дисплея, дисковых накопителей, стандартных портов и остальной базовой периферии. Эти подпрограммы предоставляют программному обеспечению более высокого уровня стандартный интерфейс для перечисленных устройств.
Внешние шины
IBM PC, появившийся в 1981 году, во многом обязан своим успехом одной особенности, отличавшей его от большинства других ПК того времени. Речь идет об открытой архитектуре компьютера: материнская плата базового ПК содержала лишь процессор, память и тот минимум периферии, без которого компьютер просто не мог функционировать. Для подключения всех остальных устройств на плате имелись восемь разъемов внешней шины, в которые пользователь мог вставлять необходимые ему дополнительные платы: контроллер дисплея, дисковых накопителей, параллельных и последовательных портов и т.д.

Рисунок 6. Разъемы внешних шин на материнской плате
Эта шина была восьмиразрядной, называлась Multibus I, ее разъем был стандартизован, а спецификация – открыта для сторонних производителей периферии. В 1984 году, при создании архитектуры АТ, разрядность этой шины была расширена до 16 бит, новая спецификация получила название ISA, и в таком виде она и дожила до нынешних времен, в течение 15 лет являясь отраслевым стандартом (ISA – Industry Standard Architecture). Шина представляла собой синхронную 16-битную шину с раздельными линиями адреса и данных, работающую на частоте 8,33 Мгц, с контролем четности и двухуровневыми прерываниями (trigger-edge interrupts), при использовании которых устройства запрашивают прерывания по переднему или заднему фронтам сигнала на линии соответствующего IRQ. Такая организация запросов прерываний позволяет использовать каждое прерывание только одному устройству. Основной особенностью шины ISA является простота ее реализации и, как ни странно это звучит, низкая рабочая частота, что позволяет до сих пор использовать ее при создании нестандартных периферийных устройств самого различного назначения. До самого последнего времени шина ISA была единственной, для которой изготовлялись внутренние модемы с аппаратной реализацией управляющих схем, да и многие недорогие SCSI-сканеры комплектовались интерфейсными картами, рассчитанными именно под эту шину. Но, тем не менее, в настоящий момент ISA практически закончила существование, передав свои функции более современным шинам.
EISA. С появлением процессоров i386, i486 и Pentium шина ISA стала узким местом персональных компьютеров на их основе. Новая системная шина EISA (Extended Industry Standard Architecture), появившаяся в конце 1988 года, обеспечивала адресное пространство в 4 Гбайта, 32-битовую передачу данных (в том числе и в режиме DMA), улучшенную систему прерываний и арбитраж DMA, автоматическую конфигурацию системы и плат расширения. Устройства шины ISA могли работать на шине EISA.
Шина EISA предусматривала централизованное управление доступом к шине за счет наличия специального устройства - арбитра шины. Поэтому к ней могли подключаться несколько главных устройств шины (Bus Masters). Улучшенная система прерываний позволяла подключать к каждой физической линии запроса на прерывание несколько устройств, что снимало проблему количества линий прерывания. Шина EISA работала на частоте около 8 МГц и имела максимальную теоретическую скорость передачи данных 33 Мбайт/с.
MCA. Шина MCA (Micro Channel Architecture) также обеспечивала 32-разрядную передачу данных, тактировалась частотой 10 МГц, имела средства автоматического конфигурирования и арбитража запросов. В отличие от EISA она не была совместима с шиной ISA и использовалась относительно недолго и только в компьютерах семейства PS/2 компании IBM.
VL-BUS. Шина VL-bus, предложенная ассоциацией VESA (Video Electronics Standard Association), предназначалась для увеличения быстродействия видеоадаптеров и контроллеров дисковых накопителей для того, чтобы они могли работать с тактовой частотой до 40 МГц. Шина VL-bus имела 32 линии данных и позволяла подключать до трех периферийных устройств, в качестве которых наряду с видеоадаптерами и дисковыми контроллерами могли выступать и сетевые адаптеры. Максимальная скорость передачи данных по шине VL-bus могла составлять около 130 Мбайт/с. Основная особенность этой шины заключалась в том, что она рассчитана на совместную работу с процессором i486 и только с ним – всего три устройства на шине это еще и следствие ограниченной нагрузочной способности выводов процессора. После появления процессора Pentium ассоциация VESA приступила к работе над новым стандартом VL-bus версии 2, который предусматривает использование 64-битовой шины данных и увеличение количества разъемов расширения, однако новым стандартом суждено было стать следующей шине:
PCI. Появившаяся в 1992 году шина PCI имела несколько особенностей, позволивших ей за короткое время занять господствующее положение в наших ПК, оттеснив многочисленных конкурентов. Главными из них были ее открытая, доступная всем и каждому, архитектура и независимость от процессорной шины. Шина PCI является синхронной 32-х разрядной (кроме этого, существуют ее 64-разрядные версии) и работает на частоте 33 Мгц, обеспечивая пропускную способность (с использованием пакетного режима пересылки данных) 133 Мб/с. Процессор через так называемые мосты (PCI Bridge) может быть подключен к нескольким каналам PCI, обеспечивая возможность одновременной передачи данных между независимыми каналами PCI. Важной особенностью шины является реализация принципа Bus-master, что позволяет картам расширения производить обмен данными с памятью без обращения к процессору. Для уменьшения количества проводников в шине PCI используется принцип мультиплексирования данных, то есть адрес и данные передаются по одним и тем же физическим линиям поочередно. PCI-устройства оборудованы таймером, определяющим максимальный период времени, когда устройство может занимать шину.
Автоматическое конфигурирование устройств PCI (выбор запросов прерывания, каналов DMA) поддерживается средствами BIOS материнской платы в соответствие со стандартом Plug&Play. Спецификация PCI 2.2 обеспечивает поддержку плат расширения с напряжениями питания как 3,3, так и 5 вольт, причем тип платы определяется расположением ключей в разъеме. Если у карты PCI есть две ключевые выемки, то она поддерживает любой из вариантов слота, если же на ней только одна выемка ближе к передней части платы, то эта карта только на 3,3 вольта. При расположении выемки ближе к задней части - карта пятивольтовая.
AGP. В результате широкого распространения 3D-графики и поддерживающих ее видеокарт, нагрузка на шину PCI достигла предельных для нее значений, превратив участок процессор - PCI-видеокарта в очередное "узкое место" системы. Для разрешения возникшей проблемы с наименьшими затратами специалистами Intel была предложена новая спецификация шины, ориентированной исключительно для обмена данными с видеоадаптером: AGP 1.0, являющейся, по сути дела, расширением старой доброй шины PCI. С целью ускорения обмена данными было устранено мультиплексирование линий адреса и данных (напомним, что в PCI для удешевления конструкции адрес и данные передавались по одним и тем же линиям), удвоена тактовая частота и реализована (в режиме AGP 2x) схема DDR, когда по шине передается 2 блока данных за один цикл. В результате предельная пропускная способность шины составила 533 Мбайт/с. Но очень скоро и этого стало не хватать, поэтому в новой спецификации AGP 2.0 (режим 4x), благодаря снижению напряжения питания видеокарт с 5 до 3,3 V, а, значит, и амплитуды сигналов в шине, появилась возможность осуществлять не 2, а 4 транзакции (пересылки блока данных) за один такт, что удвоило пропускную способность шины, доведя ее до 1066 Мбайт/с. Для автоматического распознавания видеокарт разных спецификаций используются различные конфигурации их разъемов
Шина AGP имеет два осно