Хеширование
Рассматриваемый ниже метод хеширования (hashing – перемешивание) использует при поиске целочисленный образ ключа элемента. Этот прием позволяет сократить вычислительную сложность поиска при возможном увеличении используемой для этого памяти. Хеширование – эффективный способ представления данных, позволяющий быстро выполнять операции вставки, поиска и удаления элемента. Данные в этом случае хранятся в специальным образом заполненных массивах M размера m – хеш-таблицах. Размещение элементов в таких таблицах производится в соответствии с некоторой целочисленной функцией H (k) – хеш-функцией, определенной на множестве ключей K:
H: K → {0, 1, 2, …, m –1}.
В худшем случае поиск в такой таблице занимает столько же операций, как и поиск в списке – O (n). При определенных способе заполнения таблицы и выборе вида хеш-функции среднее время поиска элемента в хеш-таблице может определяться величиной O (1).
Алгоритмы поиска, которые используют хеширование, состоят из двух этапов.
Первый этап – вычисление хеш-функции H, которая преобразует ключ поиска в адрес в хеш-таблице.
В идеале различные ключи должны отображаться на различные адреса, но часто два и более различных ключей k ≠ k* могут преобразовываться в один и тот же адрес в таблице, т.е. H (k) = H (k*). Эта ситуация называется коллизией, а ключи с одинаковыми значениями хеш-функции – синонимами.
Второй этап поиска методом хеширования – процесс разрешения конфликтов (коллизий), в ходе которого обрабатываются ключи-синонимы.
В одном из рассматриваемых методов для разрешения коллизий используются связные списки, поэтому он находит непосредственное применение в динамических ситуациях, когда заранее трудно предвидеть количество синонимов. В другом методе разрешения коллизий высокая производительность поиска обеспечивается для элементов, хранящихся в массиве.
Хеширование является хорошим примером компромисса между вычислительной сложностью алгоритма и объёмом требуемой памяти. Если бы не было ограничений на объем памяти, можно было бы использовать ключ (при условии его целочисленности) в качестве адреса элемента. При условии, что все ключи различны, вставка и поиск осуществлялись бы за O (1) операций. Однако в практической деятельности возникают длинные ключи, и такой подход становится неприемлемым из-за большого объема требуемой памяти. В случае, когда нет ограничений на вычислительную сложность, можно использовать тотальный перебор, минимум памяти и получить O (n) операций. Хеширование предоставляет собой способ,
сочетающий как использование приемлемого объёма памяти, так и приемлемого времени поиска. Причём все это можно делать, изменяя размер таблицы и не меняя, в принципе, метода поиска.
Хеш-функции
Перед тем, как рассматривать основные способы построения хеш-функции, определим требования, которым она должна удовлетворять.
Во-первых, для любого ключа k хеш-функция H (k) c равной вероятностью принимает любое из m возможных значений. Пусть P – распределение вероятностей ключей на множестве K, и ключи выбираются независимо друг от друга. Тогда при выполнении условия

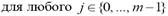
будем говорить, что функция удовлетворяет предположениям равномерного хеширования.
К сожалению, в практических задачах заранее не известно распределение ключей. К тому же, их выбор может не быть независимым. Поэтому при выборе хеш-функции пользуются различными эвристиками, основанными на специфике задачи. Основной целью при этом будет сведение к минимуму числа коллизий.
Во-вторых, значения хеш-функции должны быстро вычисляться. Если вычислительная сложность вычислений будет O (n), то применять метод хеширования вовсе не имеет смысла.
Известны различные способы построения хеш-функций, рассмотрим наиболее распространенные.
Метод деления с остатком (модульная хеш-функция)
Этот метод используется наиболее часто. Построение хеш-функции методом деления с остатком состоит в том, что ключу k ставится в соответствие остаток от деления k на m, где m – число возможных хеш-значений:
H (k) = k mod m.
Следует отметить, что значений m, равных степени основания счисления, стоит избегать. Например, в случае, когда m = 2 t, H (k) – это t младших битов числа и значение хеш-функции определяется не всем ключом, а его частью. Хорошие результаты обычно получаются, если выбрать в качестве m простое число, далеко отстоящее от степеней двойки.
Рассмотрим пример, как и ранее предполагая, что имеем дело с целочисленными значениями ключей. Пусть дана последовательность ключевых элементов 18, 14, 9, 20, 19, 12, 5, 27, 16, 34. Для задания хеш-функции воспользуемся методом деления с остатком. Пусть m = 11. Значения хеш-функции при этом будут равны:
H (18) = 7, H (12) = 1,
H (14) = 3, H (5) = 5,
H (9) = 9, H (27) = 5,
H (20) = 9, H (16) = 5,
H (19) = 8, H (34) = 1.
Мультипликативный метод
Вторым способом построения хеш-функции является мультипликативный метод. Пусть количество хеш-значений равно m. Зафиксируем константу A в интервале 0 < A < 1 и положим

Где kAmod1 – дробная часть kA, []означает целую часть.
В отличие от предыдущего метода качество хеш-функции не сильно зависит от m. Обычно в качестве m выбирают степень двойки, так как умножение в этом случае реализуется простым сдвигом. Метод умножения работает при любом выборе константы A, но некоторые значения A могут быть лучше других. Оптимальный выбор зависит от того, какого рода данные подвергаются хешированию. Д.Кнут пришел к выводу, что довольно удачным является значение A ≈ (–1)/2 = 0,6180339887… (золотое сечение). 5
Рассмотрим пример: A = 0,61, k = 34, m = 16, тогда
H (34) = [16·(34·0,61 mod 1)] = [16·0,74] = [11,84] = 11.
Универсальное хеширование
Если известна хеш-функция H (k), то можно подобрать вводимые ключи так, что она принимает на них одно и то же значение. В результате время поиска нужного ключа будет O (n). Чтобы избежать такой ситуации, надо выбирать хеш-функцию из некоторого класса функций случайным образом, не зависящим от входных данных. Такой подход называется универсальным хешированием. В этом случае мы не имеем информации о выбранной функции, а, следовательно, не можем искусственно создать описанную выше ситуацию. В итоге среднее время поиска будет порядка O (1).
Как отмечалось выше, с помощью хеш-функций ключи преобразуются в адреса таблицы в заданном диапазоне. После того как выбрана функция хеширования, необходимо определиться со способом разрешения коллизий. Прежде чем использовать таблицу для поиска, в неё надо занести ключи с учетом способа разрешения коллизий.
Рассмотрим классические подходы к решению этой проблемы.
Разрешение коллизий с помощью метода цепочек
Рассмотрим способ разрешения коллизий с помощью метода цепочек (иногда его называют открытым хешированием). Пусть задана хеш-функциия H (k), определенная на множестве ключей K:
H: K → {0,1,2,…, m –1}.
Зададим массив (таблицу) списков M размером m. Элемент k размещаем в список M [ H (k)]. Элементы, для которых значения хеш-функции совпадают, хранятся в одном и том же списке. В M [ j ] хранится указатель на список тех элементов, для которых значение хеш-функции равно j; если таких элементов нет, то список M [ j ] пуст.
Если новый элемент размещается в начало списка, то это требует O (1) операций. Максимальное время работы операции поиска пропорционально длине списка синонимов. Удаление найденного элемента можно провести также за O (1) операций.
Рассмотрим пример разрешения коллизий с помощью метода цепочек для последовательности 18, 14, 9, 20, 19, 12, 5, 27, 16, 34. Результат вставки элементов в пустую хеш-таблицу в соответствии со значениями хеш-функции H (k) = k mod 11 приведен ниже. Элемент 18 размещается в списке 7, 14 – в списке 3, 9 и 20 – в списке 9 и т.д. Очередной элемент вставляется в начало списка с целью минимизации времени вставки. В итоге хеш-таблица будет выглядеть так:
| Элементы списка | |
| Пусто | |
| 34→12 | |
| Пусто | |
| Пусто | |
| 16→27→5 | |
| Пусто | |
| 20→9 | |
| Пусто |
Оценка вычислительной сложности
Оценим число операций, необходимых для работы алгоритма хеширования с разрешением коллизий методом цепочек. Пусть в таблицу занесено n элементов. Назовем коэффициентом заполнения таблицы число α=n/m
Коэффициент α может быть как меньше, так и больше единицы.
В худшем случае, когда все n элементов попадают в один список синонимов, на поиск элемента может понадобиться O (n) операций. Средняя вычислительная сложность поиска зависит от вида хеш-функции, а, следовательно, и от размещения элементов по спискам. Далее будем полагать, что размещение элементов происходит независимо друг от друга (равномерное хеширование).
Теорема 1. При равномерном хешировании и разрешении коллизий методом цепочек среднее число операций при поиске элемента,
отсутствующего в хеш-таблице, включая вычисление хеш-функции, будет равно O (1+ α), где α – коэффициент заполнения таблицы.
Без доказательства.
Теорема 2. При равномерном хешировании среднее число операций при успешном поиске в хеш-таблице с цепочками есть O (1+ α), где α – коэффициент заполнения.
Без доказательства.
Из теорем следует, что если размер хеш-таблицы m пропорционален числу хранящихся в ней элементов n, то alfa=n/m=O(1). Следовательно, среднее число операций при поиске элемента в предположении равномерного хеширования равно O(1+alfa)=O(1)