Параметры т и b линейной модели y = тх + b можно определить при помощи функций НАКЛОН (SLOPE) и ОТРЕЗОК (INTERCEPT).
Функция НАКЛОН (SLOPE) определяет коэффициент наклона линейного тренда, а функция ОТРЕЗОК (INTERCEPT) – точку пересечения линии линейного тренда с осью ординат.
Синтаксис:
НАКЛОН (изв_знач_у; изв_знач_х)
ОТРЕЗОК (изв_знач_у; изв_знач_х)
изв_знач_у – массив известных значений зависимой наблюдаемой величи ны;
изв_знач_х – массив известных значений независимой наблюдаемой величины.
Если изв_знач_х опущены, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и изв_знач_у.
Функции НАКЛОН и ОТРЕЗОК вычисляют результат по следующим формулам:

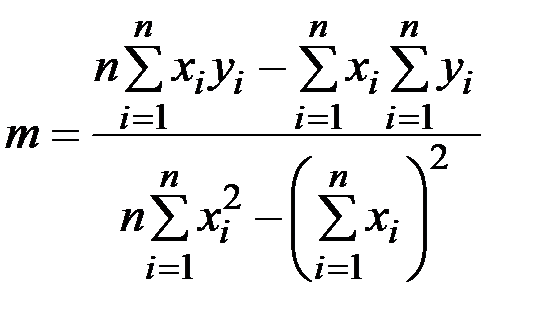 ,
,
 ,
,
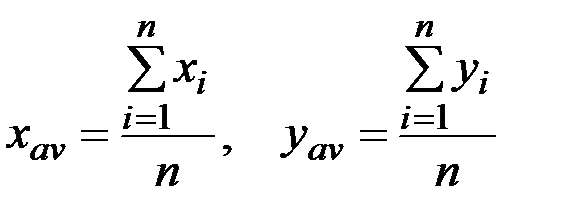 .
.
В ячейках D3 и Е3 (рис. 7.9) найдены значения т и b, соответственно, по формулам
=НАКЛОН (B2:B7;A2:A7)
=ОТРЕ3ОК(B2:B7;A2:A7)
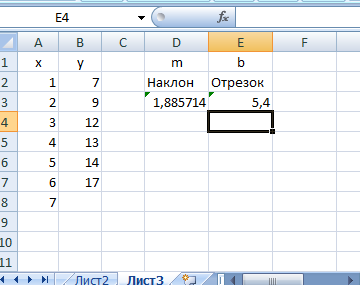
Рис. 7.9. Коэффициенты уравнения регрессии
Найдя коэффициенты уравнения регрессии, на их основе легко определить теоретические значения наблюдаемой величины, для этого:
1. Введите в ячейку С2 формулу
=$D$3*A2+$E$3
2. Выберите ячейку С2, расположите указатель мыши на маркере заполнения и протяните его на диапазон C3:C7 (рис. 7.10).
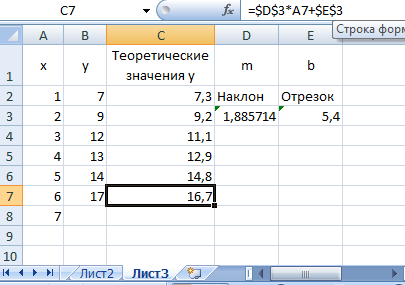
Рис. 7.10. Теоретические значения линейной регрессии,
вычисленные по функциям рабочего листа
Теоретическое значение можно вычислить с помощью функции ПРЕДСКАЗ (FORECAST), не определяя предварительно коэффициенты линейной модели, в фиксированной точке.
Синтаксис:
ПРЕДСКАЗ (х; изв_знач_у; изв_знач_х)
§ х точка данных, для которой предсказывается значение;
§ изв_знач_у – массив известных значений зависимой наблюдаемой величины;
§ изв_знач_х – массив известных значений независимой наблюдаемой величины. Если изв_знач_х опущены то предполагается, что это массив {1; 2; 3;...} такого же размера, как и изв зна ч_у.
Например теоретическое значение в ячейке С2 можно было бы также определить по формуле
=ПРЕДСКАЗ(А2;$B$2:$B$7;$A$2:$A$7).
Введем эту формулу в ячейку F2 и протянем ее на диапазон F3:F7 (рис. 7.11).

Рис. 7.11.
Функция ТЕНДЕНЦИЯ (TREND) вычисляет значения уравнения линейной регрессии для целого диапазона значений независимой переменной как для случая одномерного, так и многомерного уравнения регрессии. Многомерная линейная модель регрессии имеет вид:
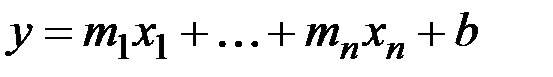 .
.
Синтаксис:
ТЕНДЕНЦИЯ (изв зна чу; иэв_зна ч_х; нов зна чх; константа)
§ изв_знач_у – массив известных значений зависимой наблюдаемой величины;
§ изв_знач_х – массив известных значений независимой наблюдаемой величины. Если изв_знач_х опущены, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и изв_знач_у;
§ нов_знач_х – новые значения х, для которых ТЕНДЕНЦИЯ возвращает соот. ветствуюшие значения у;
§ константа – логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущена, то b вычисляется обычным образом. Если константа имеет значение ЛОЖЬ, то b полагается равным 0.
Если строится многомерная линейная модель, то изв_знач_х и нов_знач_х должны содержать столбец (или строку) для каждой независимой переменной. Если нов_знач_х опущены, то предполагается, что они совпадают с изв_знач_х.
В ячейку С7 введем формулу массива
={ТЕНДЕНЦИЯ($B$2:$B$7;$A$2:$A$7;A10:A12)}
(не забудьте ее ввод завершить нажатием комбинации клавиш <Shift>+<Ctrl>+<Enter>) (рис. 7.12).

Рис. 7.12.
Функция ЛИНЕЙН(LINEST) возвращает массив { mn, …, m1, b }значений параметров уравнения многомерной линейной регрессии.
Синтаксис:
ЛИНЕЙН(изв_знач_у; изв_знач_х; константа; стат)
v изв_знач_у – массив известных значений зависимой наблюдаемой величины;
v изв_знач_х – массив известных значений независимой наблюдаемой величины. Если изв_знач_х опущены, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и изв_знач_у;
v константа – логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА, или опущена, то b вычисляется обычным образом. Если константа имеет значение ЛОЖЬ, то b полагается равным 0;
v стат – логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии, например коэффициент корреляции. Если стат имеет значение ИСТИНА, то функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Если стат имеет значение ЛОЖЬ или опущена, то функция ЛИНЕЙН возвращает только значения коэффициентов.
Теперь настало время построить его диаграмму. В MS Excel уравнения регрессии называется линией тренда, которая показывает тенденцию изменения данных и служит для составления прогнозов. Для создания линии тренда на основе диаграммы используется один из пяти типов аппроксимации или линейная фильтрация (табл. 7.2).
Таблица 7.2. Типы аппроксимаций
| Тип | Описание |
| Линейная | y = mx + b где т – тангенс угла наклона, b – точка пересечения с осью ординат |
| Логарифмическая | y= c ln x + b где c и b – константы |
| Полиномиальная | y = c6 x6 + … + c1 x + b где с6,..., с1 и b – константы |
| Степенная | y = c xb где с и b – константы |
| Экспоненциальная | у = c e bx где с и b – константы |
| Линейная фильтрация | Каждая точка данных на линии тренда строится на основе среднего указанного числа точек данных (периодов). Чем больше число периодов устанавливается, тем более гладкой, но менее точной, становится линия тренда |
На диаграмме можно выделить любой ряд данных и добавить к нему линию тренда. Когда линия тренда добавляется к ряду данных, она связывается с ним, и поэтому при изменении значений любых точек ряда данных линия тренда автоматически пересчитывается и обновляется на диаграмме.
Кроме того, имеется возможность выбирать точку, в которой линия тренда пересекает ось ординат, добавлять к диаграмме уравнение регрессии и величину достоверности аппроксимации.
Покажем на нашем примере по продажам автомобилей, как строится линия тренда. Для этого:
1. При помощи Мастера Диаграмм постройте по диапазону ячеек А2:В7 точечный график.
2. Выберите диаграмму или график, а затем команду Диаграмма → Добавить линию тренда. На экране отобразится диалоговое окно Линия тренда.
3. На вкладке Тип диалогового окна Линия тренда выберите тип линии тренда. В данном случае – Линейная (рис. 7.13).
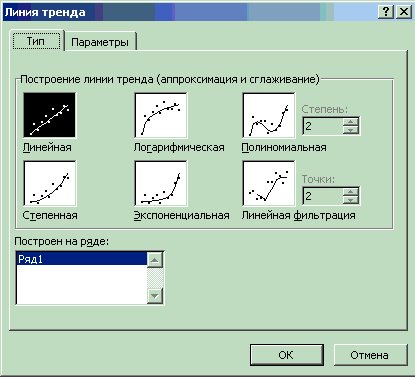
Рис. 7.13. Вкладка Тип диалогового окна Линия тренда
4. На вкладке Параметры диалогового окна Линия тренда можно установить параметры линии тренда (рис. 7.14). В группе Прогноз можно указать число периодов, на которые линия тренда либо составляет прогноз, либо определяет историю процесса. Если вы отметите флажок показывать уравнение на диаграмме, то уравнение линии тренда отобразится на диаграмме. Если установите флажок поместить на диаграмму величину достоверности аппроксимации (R^2), то на диаграмме отобразится величина достоверности аппроксимации, т.е. квадрат коэффициента корреляции. По коэффициенту корреляции можно судить о правомерности использования линейного уравнения регрессии. Если он лежит в диапазоне от 0,9 до 1, то данную зависимость можно использовать для предсказания результата. Чем коэффициент корреляции ближе к единице, тем он более обосновано указывает на линейную зависимость между наблюдаемыми величинами. Если коэффициент корреляции лежит близко к –1, то это говорит об обратной зависимости между ними. Флажок пересечение кривой с осью Y в точке устанавливается только в том случае, когда эта точка известна. Например, если данный флажок включен и в соответствующее поле введено значение 0, то это означает, что ищется модель y = bx.
5. Нажмите на кнопку ОК.
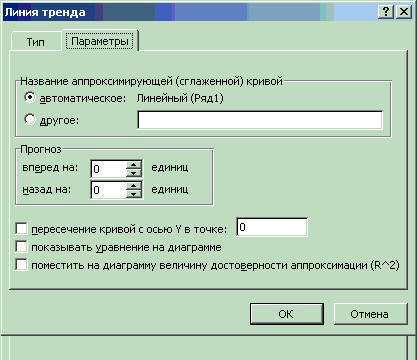
Рис. 7.14. Вкладка Параметры диалогового окна Линия тренда
Результат выполнения команды Добавить линию тренда приведен на рис. 7.15. Квадрат коэффициента корреляции равен 0.9723. Следовательно, линейная модель может быть использована для предсказания результатов.
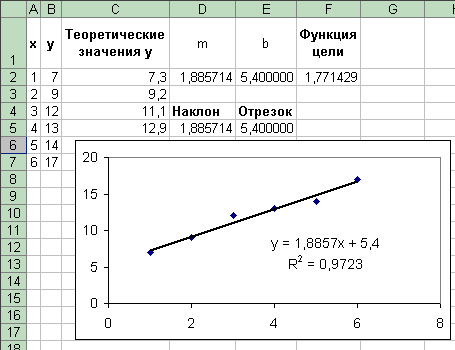
Рис. 7.15. Линия тренда
Экспоненциальная модель
Другой часто встречающейся на практике регрессионной моделью является экспоненциальная, описываемая уравнением
у = c ebx.
Значения экспоненциального тренда можно предсказывать при помощи функции РОСТ(GROWTH).
Синтаксис:
РОСТ (изв_знач_у; изв_знач_х; нов_знач_х; константа)
изв_знач_у – массив известных значений зависимой наблюдаемой вели. чи ны;
изв_знач_х – массив известных значений независимой наблюдаемой величины. Если изв_знач_х опущены, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и изв_знач_у;
нов_знач_х – новые значения х, для которых рост возвращает соответствующие значения у;
константа – логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущена, то b вычисляется обычным образом. Если константа имеет значение ЛОЖЬ, то b полагается равным 0 (рис. 7.16).

Рис. 7.16. Связь между линейной и экспоненциальной линиями тренда
Значения параметров экспоненциальной модели определяются при помощи, функции ЛГРФПРИБЛ (LOGEST).
Синтаксис:
ЛГРФПРИБЛ (изв_знач_у; изв_знач_х; константа; стат)
изв_знач_у – массив известных значений зависимой наблюдаемой вели. чи ны;
изв_знач_х – массив известных значений независимой наблюдаемой величины. Если изв_знач_х опущены, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и изв_знач_у;
нов_знач_х – новые значения х, для которых рост возвращает соответствующие значения у;
константа – логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущена, то b вычисляется обычным образом. Если константа имеет значение ЛОЖЬ, то b полагается равным 0;
стат – логическое значение, которое указывает, требуется ли, вернуть дополнительную статистику по регрессии, например коэффициент корреляции. Если стат имеет значение ИСТИНА, то функция ЛГРФПРИБЛ возвращает дополнительную регрессионную статистику. Если стат имеет значение ЛОЖЬ или опущена, то функция ЛГРФПРИБЛ возвращает только значения коэффициентов.
Одномерную экспоненциальную модель также можно построить графически, как это было описано в разд. “Построение уравнения регрессии” ранее в этом разделе.
Линейный и экспоненциальный тренды тесно связаны между собой. Покажем это на рассматриваемом в данном разделе примере с продажами автомобилей.
Квадрат коэффициента корреляции экспоненциальной модели равен 0.947 и меньше квадрата коэффициента корреляции линейной модели. Таким образом, в данном случае линейная модель более достоверно описывает зависимость между наблюдаемыми величинами.
В Excel 2007 после построения графика зависимости продаж от недели (рис. 7.17) построение линии тренда осуществляется следующим образом.
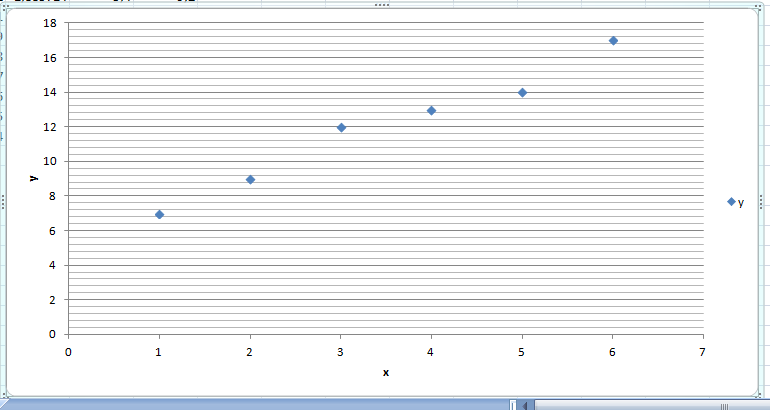
Рис. 7.17.
После щелчка правой кнопкой мыши по одному из маркеров данных выбираем из появившегося меню пункт Добавить линию тренда (рис. 7.18).
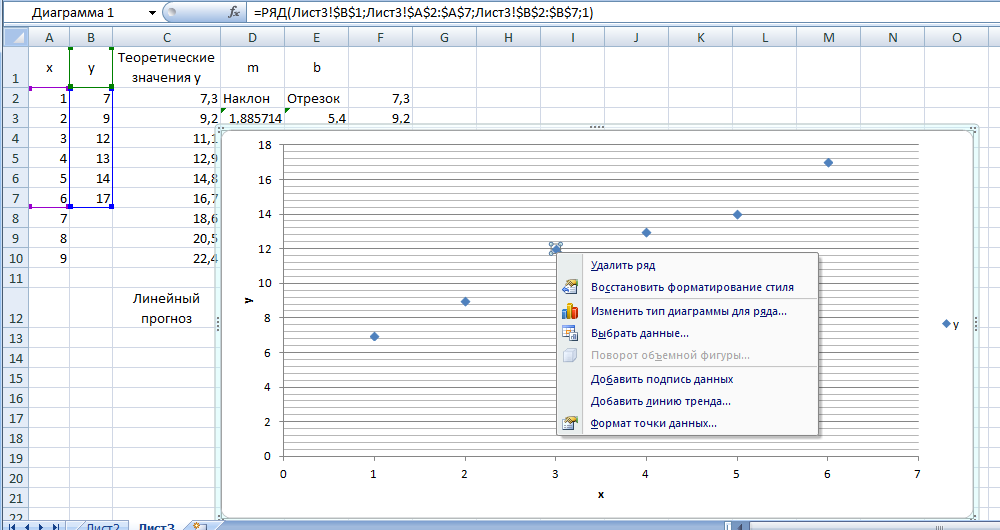
Рис. 7.18.
В появившемся окне выбираем тип линии тренда (Линейная), Показать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации (рис. 7.19).
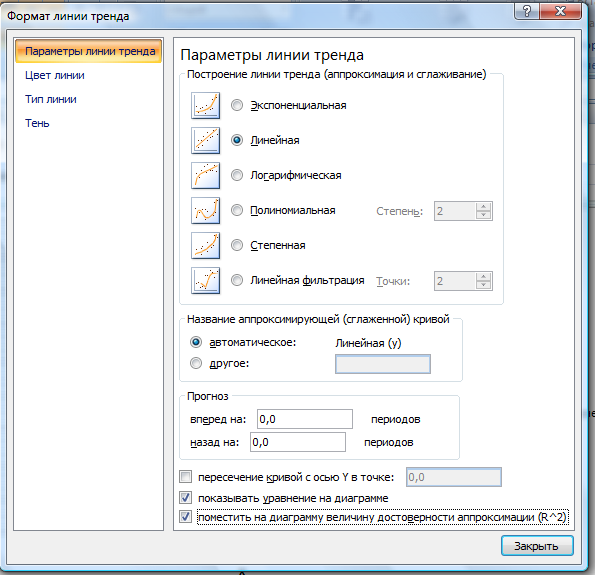
Рис. 7.19.
Результат показан на рис. 7.20.

Рис. 7.20.
Аналогичным образом строим экспоненциальную модель (рис. 7.21).

Рис. 7.21.