Отчет
о выполнении технического задания на тему
«Классификация грибов с использованием системы RapidMiner»
по дисциплине «Введение в интеллектуальный анализ данных»
Выполнила:
студентка группы № 147 БИ
_________ Д. И. Мангыр
Проверил:
Заведующий кафедрой
д-р техн.наук профессор
___________А. В. Замятин ___________________
зачтено /не зачтено
Содержание
1. Введение
2. Визуализация данных
3. DecisionTree
4. RandomForest
5. 5. Заключение
Введение
В данной работе приводится бинарная классификация грибов как съедобные или нет с использованием программы RapidMiner. Также попытаемся ответить на вопрос: каковы основные характеристики съедобного гриба?Данные были взяты из сайта Центра Машинного обучения и Интеллектуальных систем (https://archive.ics.uci.edu/ml/datasets/Mushroom).Дано множество видов грибов −Xи множество ответов, является ли гриб съедобным или нет – Y. Оно представлено в виде таблицы (см. label). И существует целевая функцияy∗: X→ Y, со значениями yi=y*(xi). Причём значения известны только на конечномподмножестве объектов
x1, x2, …, xn⊂X. Пару (xi, yi) называют парой «объект-ответ». Совокупность пар D= (xi, yi)ni=1 называется обучающей выборкой.
Таблица, включающая описание 8124 наблюдений грибов. И каждое наблюдение состоит из 23 переменных (признаков). Каждый объект обладает определённым количеством номинальных признаков, который описывают объект.
Из таблицы (label)понятно, чтопеременнаяveil_type имеет только один фактор. И в основном она не несет никакой информации, поэтому ее можно убрать.
Визуализация данных
Это один из самых важных шагов в процессе DS. Этот этап может дать нам неожиданную информацию и часто позволяет нам задавать правильные вопросы.
 Видно, что лучше брать грибы с волокнистой поверхностью. И не брать грибы с гладкой поверхностью, за исключением случаев, когда они фиолетовые или зеленые.
Видно, что лучше брать грибы с волокнистой поверхностью. И не брать грибы с гладкой поверхностью, за исключением случаев, когда они фиолетовые или зеленые.
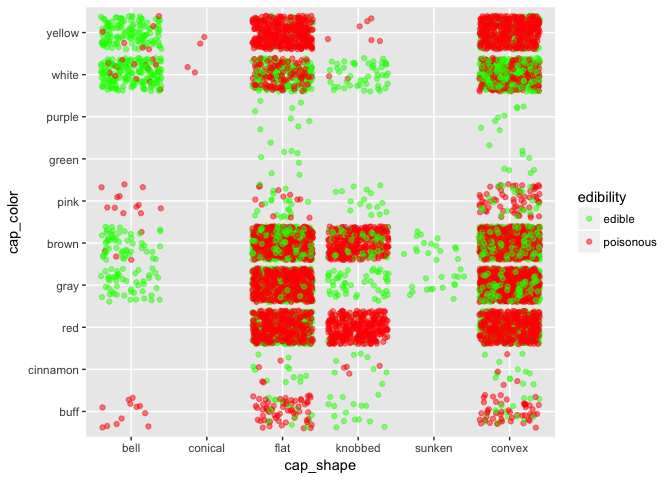
Если вы не знаете умеете определять гриб, то лучше стоит брать грибы с колоколообразной формой шляп.

Запах является наиболее информативным признаком. Если гриб пахнет рыбой, острым просто держитесь от таких грибов подальше. Если пахнет анисом или миндалем, вы можете смело их есть. Если гриб не пахнет, у вас есть больше шансов, что это съедобный гриб, чем ядовитый.
Прежде чемпродолжить, необходимо разбить данные на обучающую и тестовую выборку.
Использование DecisionTree
Поскольку у нас категориальные переменные, дерево является идеальным инструментом классификации для такой ситуации.
Дерево решений это скорее перевёрнутое дерево решений, потому что корень дерево находится сверху и растёт оно вниз. Такой способ представление данных имеет преимущество по сравнению с другими способами представления данных, так как наиболее наглядно интерпретирует логику результатов. Цель данного оператора – создать модель классификации, которая будет прогнозировать значения целевого атрибута, на основании значений входных атрибутов.
1. Импортируем данные, получаем исходную выборку для дальнейшего обучения;
2. Разделяем данные на обучающие и проверочные данные идентичные по структуре. Стоит отметить, что эти проверочные данные не должны участвовать на этапе обучения;
3. На основе полученной обучающейся выборки получаем обученную модель (в данном случае дерево решений);
4. Применяем модель к проверочным данным, полученным. В результате получаем так называемый вектор производительности.
PerformanceVector:
accuracy: 100.00%
ConfusionMatrix:
True: p e
p: 1175 0
e: 0 1262
precision: 100.00% (positive class: e)
ConfusionMatrix:
True: p e
p: 1175 0
e: 0 1262
recall: 100.00% (positive class: e)
Использование RandomForest
Обычно RandomForestиспользуют, если дерева недостаточно. В этом случае, поскольку у нас есть идеальное предсказание с использованием одного дерева, на самом деле нет необходимости использовать алгоритм RandomForest. Мы просто используем для обучения, не настраивая ни один из параметров.
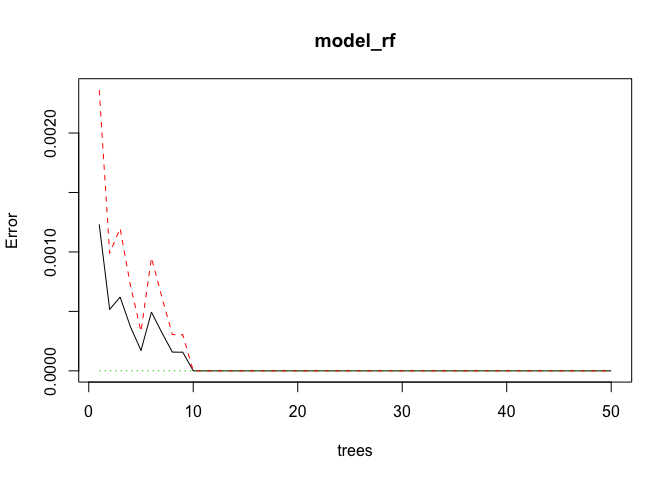 По умолчанию количество деревьев для случайного леса равно 500; мы просто используем здесь 50. Как мы можем видеть на сюжете, выше 20 деревьев, ошибка больше не уменьшается. И на самом деле, ошибка кажется 0 или почти 0.
По умолчанию количество деревьев для случайного леса равно 500; мы просто используем здесь 50. Как мы можем видеть на сюжете, выше 20 деревьев, ошибка больше не уменьшается. И на самом деле, ошибка кажется 0 или почти 0.
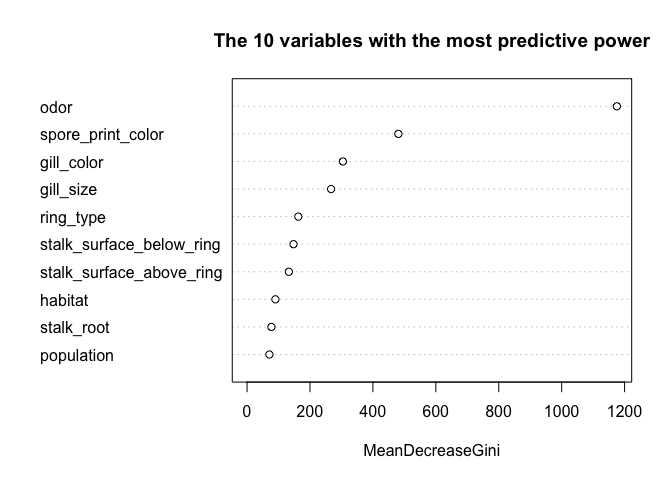
Заключение
В заключении проведём сравнительный анализ данных.Заметим, что показатель точности прогнозов у алгоритма «дерево решений» - 100% такой же как и у RandomForest. Но при этом подход TreeDecisionзначительно проще анализировать, чемRandomForest.