Московский Государственный Университет имени М. В. Ломоносова
Проект по эконометрике
На тему
«Исследование российского рынка банковских услуг»
выполнил:
Бачманов Сергей
(204 группа)
Г.
Введение
Целью данной работы является построение адекватной модели, описывающей образование прибыли на рынке банковских услуг в зависимости от различных параметров.
Основные предпосылки и допущения:
1. рассматривается рынок банковских услуг в РФ
2. рассматриваются банки, которые не несли существенных убытков в течение продолжительного периода времени. Предполагается, что отрицательная прибыль свидетельствует о недостаточной квалификации управляющего банка, а этот параметр невозможно учесть в модели
3. предполагается, что в выборку включены банки, не связанные с теневой экономикой: образование прибыли происходит в соответствии с законодательством РФ.
При этом основными требованиями к модели являются следующие: а) выявление факторов, влияющих на прибыль банка; б) верифицируемость модели.
Работа состоит из 5 частей:
1) описание данных;
2) предварительный анализ данных;
3) построение модели;
4) анализ устойчивости модели;
5) интерпретация результатов
Описание данных
Источники данных:
Данные по количественным признакам и способу привлечения средств получены с сайтов www.banks-rate.ru и www.fundz.ru информация об уровне надежности с www.investfunds.ru. Выборка является пространственной, информация о банках собиралась 5-25 апреля, так что наблюдения можно считать одномоментными. Все количественные параметры приведены в тысячах рублей.
Данные содержали следующую информацию:
Ø чистые активы
Ø работающие активы
Ø кредиты, выданные коммерческим организациям
Ø собственный капитал
Ø фактическая прибыль
Ø средства юридических лиц
Ø средства частных лиц
Ø уставной фонд
Ø ликвидные активы
Ø суммарные обязательства
Ø обязательства до востребования
Ø средства бюджетных организаций
Ø привлеченные средства других банков
Ø выпуск кредитных карт
Ø ориентация банка на обслуживание граждан, коммерческих организаций или бюджетных организаций
Ø уровень надежности
Всего было отобрано 210 наблюдений.
Проверка однородности данных:
Сначала была проведена сортировка данных по величине прибыли, а затем построена диаграмма.

По графику видно, что данные неоднородны, и необходимо исключить из выборки банки, прибыль которых более 2 млрд. и менее -500 млн. рублей.

Новая диаграмма отражает плавное изменение величины прибыли и указывает на однородность данных. После сортировки в выборке остались данные по 188 банкам.
Предварительный анализ данных
Комментарии к регрессорам, включенным в первоначальную модель:
Выпуск кредитных карт (kredkart). Параметр показывает, выпускает ли банк кредитные карты, и принимает значение 1 если выпускает и 0 если нет.
Ориентация банка на обслуживание граждан, коммерческих организаций или бюджетных организаций (chastn urid budjet). Каждый параметр принимает значение 1, если банк привлекает наибольшие средства от соответствующей группы клиентов. Уровень надежности (nada nadb nadc nadd). Каждый параметр принимает значение 1, если банк принадлежит к группе с соответствующей надежностью. Уровни надежности А++, А+, А приравниваются к А. Аналогично и уровнями В и С. Такое допущение необходимо для сокращения фиктивных переменных с 10 до 4.
Чистые активы (chakt)
Ликвидные активы (likvakt)
работающие активы (rabakt)
кредиты, выданные коммерческим организациям (kredkommorg)
собственный капитал (sobkap)
фактическая прибыль (factprib)
средства юридических лиц (srurlits)
средства частных лиц (srchlits)
уставной фонд (ustfond)
суммарные обязательства (sumobaz)
обязательства до востребования (obazdovos)
средства бюджетных организаций (srbudjetorg)
привлеченные средства других банков (privsrdrbank)
Построение модели.
Ожидания относительно знаков коэффициентов параметров на основе эмпирико-логических соображений:
| ожидаемые знаки коэффициентов | |||
| sobkap | + | privsrdrbank | - |
| likvakt | + | sumobaz | + |
| rabakt | + | obazdovos | - |
| kredkommorg | - | chakt | + |
| srurlits | + | ustfond | + |
| srchlits | + | nadc nadd | + |
| kredkart | + | nadb | + |
| nada | + | nadd | - |
Сначала следует рассмотреть модель, в которую включены все регрессоры:
FACTPRIB CHASTN CHAKT C KREDKART KREDKOMMORG LIKVAKT NADA NADB NADC OBAZDOVOS PRIVSRDRBANK RABAKT SOBKAP SRBUDJETORG SRCHLITS SRURLITS SUMOBAZ URID USTFOND
| Dependent Variable: FACTPRIB | ||||
| Method: Least Squares | ||||
| Date: 05/11/06 Time: 14:26 | ||||
| Sample: 1 188 | ||||
| Included observations: 188 | ||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| CHASTN | -38562.44 | 403146.5 | -0.095654 | 0.9239 |
| CHAKT | 0.000390 | 0.017444 | 0.022374 | 0.9822 |
| C | -31031.80 | 455112.7 | -0.068185 | 0.9457 |
| KREDKART | -126509.7 | 122003.9 | -1.036931 | 0.3012 |
| KREDKOMMORG | -0.043066 | 0.010004 | -4.304699 | 0.0000 |
| LIKVAKT | -0.058559 | 0.024442 | -2.395787 | 0.0177 |
| NADA | 155861.6 | 237730.7 | 0.655623 | 0.5130 |
| NADB | 37945.04 | 224776.6 | 0.168812 | 0.8661 |
| NADC | 24925.58 | 218431.4 | 0.114112 | 0.9093 |
| OBAZDOVOS | 0.021043 | 0.011016 | 1.910313 | 0.0578 |
| PRIVSRDRBANK | 0.011666 | 0.015564 | 0.749547 | 0.4546 |
| RABAKT | -0.000148 | 0.012834 | -0.011567 | 0.9908 |
| SOBKAP | 0.529484 | 0.042067 | 12.58669 | 0.0000 |
| SRBUDJETORG | -0.008079 | 0.017182 | -0.470193 | 0.6388 |
| SRCHLITS | 0.003690 | 0.020046 | 0.184087 | 0.8542 |
| SRURLITS | -0.034925 | 0.017205 | -2.029897 | 0.0439 |
| SUMOBAZ | 0.000706 | 0.002675 | 0.263889 | 0.7922 |
| URID | -17825.14 | 402456.1 | -0.044291 | 0.9647 |
| USTFOND | -0.403681 | 0.038156 | -10.57969 | 0.0000 |
| R-squared | 0.667580 | Mean dependent var | 378819.5 | |
| Adjusted R-squared | 0.632174 | S.D. dependent var | 703430.8 | |
| S.E. of regression | 426621.2 | Akaike info criterion | 28.86077 | |
| Sum squared resid | 3.08E+13 | Schwarz criterion | 29.18785 | |
| Log likelihood | -2693.912 | F-statistic | 18.85515 | |
| Durbin-Watson stat | 2.081729 | Prob(F-statistic) | 0.000000 |
Ожидания в отношении знаков коэффициентов подтвердились только для следующих параметров: SOBKAP, NADA, NADB, KREDKOMMORG, SUMOBAZ, CHAKT. Модель показывает, что собственный капитал банка важен для получения высокой прибыли; кредиты, выданные коммерческим организациям, снижают фактическую прибыль (средства, направленные на выдачу кредитов, поступают за счет сокращения прибыли в текущем периоде).
В целом же модель неудачная,  и
и  довольно малы, значение F-статистики тоже не большое. В этой модели 13 из 19 регрессоров незначимы. Велико значение Sum squared resid (3.08E+13) и стандартных ошибок модели (426621.2).
довольно малы, значение F-статистики тоже не большое. В этой модели 13 из 19 регрессоров незначимы. Велико значение Sum squared resid (3.08E+13) и стандартных ошибок модели (426621.2).
Проверим модель на гетероскедастичность:
| White Heteroskedasticity Test: | |||
| F-statistic | 5.439868 | Probability | 0.000000 |
| Obs*R-squared | 95.81897 | Probability | 0.000000 |
Тест Уайта no cross terms показывает, что гипотеза о гомоскедастичности принимается с вероятностью 0% т.е. отвергается, тем самым говоря о наличие гетероскедастичности.
Для улучшения модели надо исключить некоторые незначимые переменные: CHASTN, CHAKT, RABAKT, PRIVSRDRBANK, NADA, NADB, NADC, SUMOBAZ.
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | -37696.29 | 75414.85 | -0.499852 | 0.6178 |
| KREDKART | -142891.6 | 117257.7 | -1.218612 | 0.2246 |
| KREDKOMMORG | -0.038125 | 0.006146 | -6.202821 | 0.0000 |
| LIKVAKT | -0.075415 | 0.018988 | -3.971669 | 0.0001 |
| OBAZDOVOS | 0.028094 | 0.008035 | 3.496584 | 0.0006 |
| SOBKAP | 0.545392 | 0.035577 | 15.33007 | 0.0000 |
| SRBUDJETORG | -0.003419 | 0.001680 | -2.035163 | 0.0433 |
| SRCHLITS | 0.000826 | 0.014256 | 0.057910 | 0.9539 |
| SRURLITS | -0.034634 | 0.009259 | -3.740397 | 0.0002 |
| URID | 27537.09 | 91438.25 | 0.301155 | 0.7636 |
| USTFOND | -0.420058 | 0.032421 | -12.95644 | 0.0000 |
| R-squared | 0.659513 | Mean dependent var | 378819.5 | |
| Adjusted R-squared | 0.640277 | S.D. dependent var | 703430.8 | |
| S.E. of regression | 421896.1 | Akaike info criterion | 28.79963 | |
| Sum squared resid | 3.15E+13 | Schwarz criterion | 28.98900 | |
| Log likelihood | -2696.166 | F-statistic | 34.28444 | |
| Durbin-Watson stat | 2.050497 | Prob(F-statistic) | 0.000000 |
и уменьшились незначительно, зато значение F-статистики увеличилось вдвое. Стандартные ошибки почти не изменились.
| White Heteroskedasticity Test: | |||
| F-statistic | 7.432828 | Probability | 0.000000 |
| Obs*R-squared | 83.06950 | Probability | 0.000000 |
Тест Уайта по-прежнему показывает наличие гетероскедастичности.
Очевидно, что дальше исключать переменные бессмысленно и следует построить полулогарифмические и логарифмические модели.
Логарифмическая модель:
Даже если судить по графику, доказывающему однородность данных, видно, что эту выборку лучше отражает логарифмическая модель. Вернем в модель все исключенные регрессоры.
log(FACTPRIB) C log(CHAKT) CHASTN KREDKART log(KREDKOMMORG) log(LIKVAKT) NADA NADB NADC log(OBAZDOVOS) log(PRIVSRDRBANK) log(RABAKT) log(SOBKAP) log(SRBUDJETORG) log(SRCHLITS) log(SRURLITS) log(SUMOBAZ) URID log(USTFOND)
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | -5.860698 | 2.403132 | -2.438775 | 0.0168 |
| LOG(CHAKT) | 0.009676 | 0.818880 | 0.011816 | 0.9906 |
| CHASTN | 0.794260 | 0.914271 | 0.868736 | 0.3874 |
| KREDKART | -0.353906 | 0.260594 | -1.358074 | 0.1780 |
| LOG(KREDKOMMORG) | -0.649195 | 0.243334 | -2.667920 | 0.0091 |
| LOG(LIKVAKT) | 0.105788 | 0.149088 | 0.709568 | 0.4799 |
| NADA | 1.040718 | 0.587033 | 1.772844 | 0.0798 |
| NADB | 1.198949 | 0.557710 | 2.149770 | 0.0344 |
| NADC | 0.670819 | 0.527920 | 1.270682 | 0.2073 |
| LOG(OBAZDOVOS) | -0.206006 | 0.252990 | -0.814285 | 0.4178 |
| LOG(PRIVSRDRBANK) | -0.017250 | 0.044849 | -0.384634 | 0.7015 |
| LOG(RABAKT) | 0.295992 | 0.605443 | 0.488884 | 0.6262 |
| LOG(SOBKAP) | 1.136590 | 0.280941 | 4.045649 | 0.0001 |
| LOG(SRBUDJETORG) | -0.019563 | 0.027180 | -0.719778 | 0.4736 |
| LOG(SRCHLITS) | 0.105197 | 0.146548 | 0.717831 | 0.4748 |
| LOG(SRURLITS) | 0.301929 | 0.301222 | 1.002349 | 0.3190 |
| LOG(SUMOBAZ) | 0.179709 | 0.427042 | 0.420822 | 0.6749 |
| URID | 0.439510 | 0.907740 | 0.484181 | 0.6295 |
| LOG(USTFOND) | -0.134627 | 0.077598 | -1.734922 | 0.0864 |
| R-squared | 0.758589 | Mean dependent var | 11.91081 | |
| Adjusted R-squared | 0.707466 | S.D. dependent var | 1.371162 | |
| S.E. of regression | 0.741612 | Akaike info criterion | 2.403663 | |
| Sum squared resid | 46.74897 | Schwarz criterion | 2.886773 | |
| Log likelihood | -105.9905 | F-statistic | 14.83869 | |
| Durbin-Watson stat | 2.210531 | Prob(F-statistic) | 0.000000 |
Эта модель заметно лучше двух предыдущих. Значения и  высоки. Резко снизились значения стандартных ошибок. При этом при переходе к логарифмическому варианту стали значимы параметры NADB и NADA (близок к надежному уровню). У всех регрессоров низки их среднеквадратические ошибки.
высоки. Резко снизились значения стандартных ошибок. При этом при переходе к логарифмическому варианту стали значимы параметры NADB и NADA (близок к надежному уровню). У всех регрессоров низки их среднеквадратические ошибки.
Попробуем улучшить модель 3, убирая незначимые переменные.
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | -5.851245 | 2.251837 | -2.598432 | 0.0110 |
| LOG(CHAKT) | 0.567572 | 0.310173 | 1.829855 | 0.0706 |
| KREDKART | -0.362751 | 0.256686 | -1.413214 | 0.1611 |
| LOG(KREDKOMMORG) | -0.590479 | 0.168095 | -3.512759 | 0.0007 |
| LOG(LIKVAKT) | 0.033848 | 0.133881 | 0.252823 | 0.8010 |
| NADA | 0.986436 | 0.551014 | 1.790218 | 0.0768 |
| NADB | 1.182327 | 0.506423 | 2.334661 | 0.0218 |
| NADC | 0.664920 | 0.485634 | 1.369181 | 0.1744 |
| LOG(OBAZDOVOS) | -0.170145 | 0.213904 | -0.795424 | 0.4285 |
| LOG(PRIVSRDRBANK) | -0.033436 | 0.042468 | -0.787321 | 0.4332 |
| LOG(SOBKAP) | 1.103629 | 0.266809 | 4.136404 | 0.0001 |
| LOG(SRBUDJETORG) | -0.012144 | 0.024270 | -0.500383 | 0.6180 |
| LOG(SRCHLITS) | 0.235952 | 0.095926 | 2.459730 | 0.0158 |
| LOG(SRURLITS) | 0.122124 | 0.199038 | 0.613573 | 0.5411 |
| LOG(USTFOND) | -0.126844 | 0.075840 | -1.672528 | 0.0979 |
| R-squared | 0.753058 | Mean dependent var | 11.91081 | |
| Adjusted R-squared | 0.714213 | S.D. dependent var | 1.371162 | |
| S.E. of regression | 0.733010 | Akaike info criterion | 2.349391 | |
| Sum squared resid | 47.81997 | Schwarz criterion | 2.730794 | |
| Log likelihood | -107.1683 | F-statistic | 19.38634 | |
| Durbin-Watson stat | 2.099624 | Prob(F-statistic) | 0.000000 |
Некоторые параметры не были значимы ни в одной из 4-х моделей, так что их можно исключить из рассматриваемой модели. Очевидно, что ориентация банка на обслуживание определенных групп клиентов (URID, CHASTN, BUDJET) и величина суммарных обязательств не отражается на прибыли.
Проверим модель на гетероскедастичность:
| White Heteroskedasticity Test: | |||
| F-statistic | 1.551641 | Probability | 0.075856 |
| Obs*R-squared | 33.31828 | Probability | 0.097534 |
Тест Уайта показывает, что с вероятностью 7,5% гипотеза о гомоскедастичности принимается. В этой модели опять присутствует гетероскедастичность.
Полулогарифмическая модель:
LOG(FACTPRIB) C CHAKT KREDKART KREDKOMMORG LIKVAKT NADA NADB NADC OBAZDOVOS PRIVSRDRBANK RABAKT SOBKAP SRBUDJETORG SRCHLITS SRURLITS SUMOBAZ USTFOND
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | 10.65427 | 0.454848 | 23.42379 | 0.0000 |
| CHAKT | 6.59E-08 | 3.54E-08 | 1.860021 | 0.0646 |
| KREDKART | -0.089389 | 0.250501 | -0.356840 | 0.7216 |
| KREDKOMMORG | -3.05E-08 | 1.87E-08 | -1.625173 | 0.1060 |
| LIKVAKT | -9.53E-08 | 4.57E-08 | -2.083041 | 0.0387 |
| NADA | 1.455838 | 0.498505 | 2.920411 | 0.0040 |
| NADB | 1.020678 | 0.477091 | 2.139378 | 0.0338 |
| NADC | 0.215731 | 0.463742 | 0.465195 | 0.6424 |
| OBAZDOVOS | 1.06E-08 | 2.07E-08 | 0.510300 | 0.6105 |
| PRIVSRDRBANK | 5.96E-09 | 3.27E-08 | 0.182004 | 0.8558 |
| RABAKT | -5.15E-08 | 2.37E-08 | -2.172894 | 0.0312 |
| SOBKAP | 5.80E-07 | 8.89E-08 | 6.527722 | 0.0000 |
| SRBUDJETORG | 4.47E-08 | 2.94E-08 | 1.523607 | 0.1294 |
| SRCHLITS | -6.83E-09 | 3.64E-08 | -0.187774 | 0.8513 |
| SRURLITS | -8.05E-08 | 3.60E-08 | -2.234290 | 0.0268 |
| USTFOND | -4.88E-07 | 7.55E-08 | -6.463891 | 0.0000 |
| R-squared | 0.600377 | Mean dependent var | 11.87388 | |
| Adjusted R-squared | 0.565526 | S.D. dependent var | 1.375794 | |
| S.E. of regression | 0.906850 | Akaike info criterion | 2.723586 | |
| Sum squared resid | 141.4488 | Schwarz criterion | 2.999028 | |
| Log likelihood | -240.0171 | F-statistic | 17.22703 | |
| Durbin-Watson stat | 2.002770 | Prob(F-statistic) | 0.000000 |
Эта модель немного хуже предыдущей из-за уменьшившихся  и
и 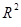 , но зато стандартные ошибки очень малы и количество незначимых параметров сократилось до пяти. Проверим модель на гетероскедастичность.
, но зато стандартные ошибки очень малы и количество незначимых параметров сократилось до пяти. Проверим модель на гетероскедастичность.
Тест Уайта:
| White Heteroskedasticity Test: | |||
| F-statistic | 0.670657 | Probability | 0.884238 |
| Obs*R-squared | 18.37158 | Probability | 0.861839 |
| White Heteroskedasticity Test: | |||
| F-statistic | 0.504944 | Probability | 0.999452 |
| Obs*R-squared | 87.11601 | Probability | 0.985155 |
моь
Тест Уайта показал хорошие результаты: с вероятностью 88% (no cross terms) и 99,9% (cross terms) в модели отсутствует гетероскедастичность. Проведем другие тесты.
Тест Голдфелда-Квандта:
Сначала упорядочим выборку по величине собственного капитала. Возьмем первые 60 и последние 60 наблюдений и найдем их RSS.
Первые 60 наблюдений
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | 9.478872 | 0.848203 | 11.17524 | 0.0000 |
| CHAKT | 6.32E-08 | 4.34E-07 | 0.145570 | 0.8851 |
| KREDKART | 0.036231 | 0.873700 | 0.041468 | 0.9672 |
| KREDKOMMORG | -1.28E-07 | 2.32E-07 | -0.551190 | 0.5851 |
| LIKVAKT | -1.57E-07 | 4.19E-07 | -0.375388 | 0.7097 |
| OBAZDOVOS | 1.80E-07 | 9.24E-08 | 1.945687 | 0.0600 |
| PRIVSRDRBANK | 2.84E-08 | 3.68E-07 | 0.077162 | 0.9389 |
| RABAKT | 8.19E-08 | 3.34E-07 | 0.245401 | 0.8076 |
| SOBKAP | 1.43E-06 | 1.19E-06 | 1.203372 | 0.2371 |
| SRBUDJETORG | -1.00E-06 | 5.39E-07 | -1.860638 | 0.0715 |
| SRCHLITS | 2.74E-07 | 3.45E-07 | 0.793853 | 0.4328 |
| SRURLITS | 4.06E-08 | 3.54E-07 | 0.114816 | 0.9093 |
| USTFOND | -1.26E-06 | 8.64E-07 | -1.460503 | 0.1533 |
| R-squared | 0.480953 | Mean dependent var | 10.72953 | |
| Adjusted R-squared | 0.251962 | S.D.dependent var | 1.054286 | |
| S.E. of regression | 0.911844 | Akaike info criterion | 2.907641 | |
| Sum squared resid | 28.26960 | Schwarz criterion | 3.519488 | |
| Log likelihood | -56.69102 | F-statistic | 2.100313 | |
| Durbin-Watson stat | 1.641794 | Prob(F-statistic) | 0.036209 |
Последние 60 наблюдений.
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | 8.188369 | 0.668328 | 12.25203 | 0.0000 |
| CHAKT | 6.28E-07 | 3.52E-07 | 1.786155 | 0.0805 |
| KREDKART | -0.193628 | 0.722050 | -0.268164 | 0.7897 |
| KREDKOMMORG | -1.46E-07 | 1.50E-07 | -0.972834 | 0.3356 |
| LIKVAKT | -6.09E-08 | 3.69E-07 | -0.164867 | 0.8698 |
| OBAZDOVOS | -8.61E-08 | 2.08E-07 | -0.413992 | 0.6808 |
| PRIVSRDRBANK | -9.58E-08 | 3.17E-07 | -0.302349 | 0.7637 |
| RABAKT | -4.60E-08 | 2.44E-07 | -0.188680 | 0.8512 |
| SOBKAP | 7.02E-07 | 3.16E-07 | 2.223895 | 0.0310 |
| SRBUDJETORG | -2.78E-07 | 5.73E-07 | -0.485100 | 0.6299 |
| SRCHLITS | 4.39E-08 | 3.04E-07 | 0.144302 | 0.8859 |
| SRURLITS | 3.53E-08 | 2.63E-07 | 0.134035 | 0.8939 |
| USTFOND | -4.27E-07 | 3.39E-07 | -1.258141 | 0.2146 |
| R-squared | 0.624625 | Mean dependent var | 10.97100 | |
| Adjusted R-squared | 0.528785 | S.D. dependent var | 1.177533 | |
| S.E. of regression | 0.808319 | Akaike info criterion | 2.601416 | |
| Sum squared resid | 30.70884 | Schwarz criterion | 3.055191 | |
| Log likelihood | -65.04249 | F-statistic | 6.517345 | |
| Durbin-Watson stat | 1.680326 | Prob(F-statistic) | 0.000001 |
RSS1=28.26960 и RSS2=30.70884
 =30.70884/28.26960=1,08628<
=30.70884/28.26960=1,08628<  , значит, предположение о гетероскедастичности отвергается
, значит, предположение о гетероскедастичности отвергается
Тест Бреуша-Пагана
Сначала надо сформировать в Excel вектор квадратов остатков  , а затем - их логарифмов
, а затем - их логарифмов  . Строим регрессию, где
. Строим регрессию, где  - объясняемая переменная.
- объясняемая переменная.
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C | -1.742633 | 0.205461 | -8.481573 | 0.0000 |
| CHAKT | 5.06E-09 | 5.23E-08 | 0.096786 | 0.9230 |
| KREDKART | -0.056200 | 0.557820 | -0.100749 | 0.9199 |
| KREDKOMMORG | 2.59E-09 | 3.18E-08 | 0.081643 | 0.9350 |
| LIKVAKT | 5.68E-08 | 5.60E-08 | 1.014630 | 0.3117 |
| OBAZDOVOS | 1.01E-08 | 3.15E-08 | 0.320031 | 0.7493 |
| PRIVSRDRBANK | 1.79E-08 | 5.69E-08 | 0.314465 | 0.7535 |
| RABAKT | 1.30E-09 | 4.29E-08 | 0.030329 | 0.9758 |
| SOBKAP | -7.73E-08 | 1.00E-07 | -0.770216 | 0.4422 |
| SRBUDJETORG | -1.43E-08 | 5.00E-08 | -0.285660 | 0.7755 |
| SRCHLITS | -7.37E-09 | 4.11E-08 | -0.179269 | 0.8579 |
| SRURLITS | -1.65E-08 | 4.77E-08 | -0.345334 | 0.7303 |
| USTFOND | 1.58E-08 | 9.13E-08 | 0.173240 | 0.8627 |
| R-squared | 0.110353 | Mean dependent var | -1.745385 | |
| Adjusted R-squared | 0.049349 | S.D. dependent var | 2.368217 | |
| S.E. of regression | 2.309043 | Akaike info criterion | 4.578185 | |
| Sum squared resid | 933.0438 | Schwarz criterion | 4.801982 | |
| Log likelihood | -417.3494 | F-statistic | 1.608940 | |
| Durbin-Watson stat | 1.934784 | Prob(F-statistic) | 0.049826 |
Полученное значение F-статистики и сравниваем его c табличным:  , значит, гипотеза о гомоскедастичности принимается.
, значит, гипотеза о гомоскедастичности принимается.
Тест Спирмена
Расчеты рангового коэффициента Спирмена между абсолютными величинами остатков и значениями величины собственного капитала банка приведены в прилагающейся таблице Excel.
 =0,642979;
=0,642979;
 =0,642979*13,674=8,7926
=0,642979*13,674=8,7926
Это значение больше чем 2,58, следовательно гипотеза об отсутствии гетероскедастичности отвергается при 1% уровне значимости.
Вывод
Три теста из четырех показали отсутствие гетероскедастичности, из чего можно сделать вывод, что модель достаточно устойчива.
Теперь приведем гистограмму и основные статистики остатков модели.

Как мы видим, гипотеза о нормальности отвергается со 100% вероятностью. Так могло произойти в результате действия факторов, не учитывающихся в математической модели, такие как репутация банка или большая известность.
Протестируем с помощью F-статистики гипотезу о том, что коэффициенты при NADB и NADC равны:
| Null Hypothesis: | C(6)=C(7) | |||
| F-statistic | 29.46654 | Probability | 0.000000 | |
| Chi-square | 29.46654 | Probability | 0.000000 |
Выясняется, что для банков с разными уровнями надежности нельзя применять одинаковые модели.