Сконструируйте файл данных, соответствующий этой многомерной таблице сопряженности. Он содержит три переменные: sex: 1. мужчины, 2. женщины; age: 1. моложе 30 лет, 2. от 30 до 44 лет, 3. от 45 до 59 лет, 4. 60 лет и старше; sleep: 1. легко, 2. довольно хорошо, 3. с трудом.
Файл data.sav и является уже сконструированным файлом данных.
2.
Проанализируйте зависимость между полом и уровнем засыпаемости. Постройте таблицу сопряженности между переменными sex и sleep, проверьте гипотезу об их независимости и проведите корреляционный анализ....
Оценить зависимость мы можем благодаря критерию Пирсона, а проверить гипотезу о независимости благодаря критерию хи-квадрат. Всё это СПСС умеет вычислять по щелчку галочки, а нам остаётся только объяснить, что они значат.
Строим таблицу сопряженности для sex и sleep:
1) Анализ – Описательная стастистика – Таблица сопряженности...
2) В Rows(Строки) добавляем sleep, а в Columns (Колонки) sex.
3) Есть внутри окошечка кнопочка Statistics. Нажимаем. Поскольку мы хотим проверить гипотезу о независимости и посмотреть на зависимость (корреляцию), то отмечаем Хи-квадрат(Chi-square) и Корреляции (Correlations).
4) Нажимаем ОК.
Получаем что-то типа того (язык может быть русским):
| sex * sleep Crosstabulation | |||||
| Count | |||||
| sleep | Total | ||||
| easy | quite well | difficult | |||
| sex | man | ||||
| woman | |||||
| Total |
Это таблица сопряженности.
| Chi-Square Tests | |||
| Value | df | Asymp. Sig. (2-sided) | |
| Pearson Chi-Square | 24.178a | .000 | |
| Likelihood Ratio | 24.381 | .000 | |
| Linear-by-Linear Association | 24.113 | .000 | |
| N of Valid Cases | |||
| a. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 192.99. |
Это тест на хи-квадрат. Здесь было бы полезно почитать учебник А. Крыштановского “Анализ социологических данных”, поскольку его сам Бог написал – нет ничего понятней и яснее про статистику в СПСС на русском языке.
Еще раз – если вы хотите понять, что такое хи-квадрат, скачайте и прочитайте про это, и вы поймётё, я гарантирую это.
Коротко говоря, критерий хи-квадрат нужен для того, чтобы проверить, насколько связаны две переменные. Эта связанность характеризуется расхождением ожидаемых и реальных частот. Реальные частоты – те, которые есть в таблице сопряженности, ожидаемые – те, которые должны быть в клетке таблицы в случае полной независимости переменных. Если хи-квадрат равен нулю, то переменные полностью независимые. В данном случае мы можем сказать, что расхождения реальных и ожидаемых частот незначительны (поскольку асимптотическая значимость – крайняя справа ячейка напротив Pearson Chi-Square – близка к нулю), поэтому можно сказать, что переменные независимы. На английском это объяснено лучше:
“The test of independence hypothesizes that Labor force status and Marital status are unrelated--that is, that the column proportions are the same across columns, and any observed discrepancies are due to chance variation. The chi-square statistic measures the overall discrepancy between the observed cell counts and the counts you would expect if the column proportions were the same across columns. A larger chi-square statistic indicates a greater discrepancy between the observed and expected cell counts--greater evidence that the column proportions are not equal, that the hypothesis of independence is incorrect, and, therefore, that Labor force status and Marital status are related.
The computed chi-square statistic has a value of 729.242. In order to determine whether this is enough evidence to reject the hypothesis of independence, the significance value of the statistic is computed. The significance value is the probability that a random variate drawn from a chi-square distribution with 28 degrees of freedom is greater than 729.242. Since this value is less than the alpha level specified on the Test Statistics tab, you can reject the hypothesis of independence at the 0.05 level. Thus, Labor force status and Marital status are in fact related.”
Когда мы будем анализировать хи-квадрат на разных возрастах, то там асимпотическая значимость будет близка к единице, что будет говорить о наличии зависимости.
| Symmetric Measures | |||||
| Value | Asymp. Std. Errora | Approx. Tb | Approx. Sig. | ||
| Interval by Interval | Pearson's R | .109 | .022 | 4.939 | .000c |
| Ordinal by Ordinal | Spearman Correlation | .108 | .022 | 4.870 | .000c |
| N of Valid Cases | |||||
| a. Not assuming the null hypothesis. | |||||
| b. Using the asymptotic standard error assuming the null hypothesis. | |||||
| c. Based on normal approximation. |
Это – таблица с двумя рассчитанными коэффициентами корреляции, R Пирсона и коэффициент Спирмена. Значение обоих на уровне 0,1, что говорит об очень слабой корреляции (грубо говоря, в 10% процентах случаев).
И график. У вас может быть с другими цветами.
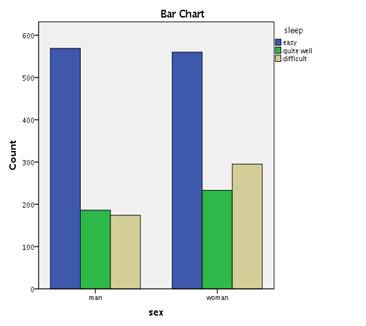
Посмотрите, как возраст влияет на эту зависимость. Для этого постройте таблицы сопряженности между sex и sleep для каждой возрастной группы и рассчитайте необходимые коэффициенты корреляции.
Чтобы посмотреть на то, как возраст влияет, мы должны сделать такой же анализ, но уже для каждой возрастной группы отдельно. Для этого выполним следующее.
1. Анализ – Описательная стастистика – Таблица сопряженности...
2. В Rows(Строки) добавляем sleep, а в Columns (Колонки) sex.
3. Есть внутри окошечка кнопочка Statistics. Нажимаем. Поскольку мы хотим проверить гипотезу о независимости и посмотреть на зависимость (корреляцию), то отмечаем Хи-квадрат(Chi-square) и Корреляции (Correlations).
4. Выделяем в левом окошке Age и переносим его в Layers(Слои). Отмечаем внизу окошечка галку “Display clustered bar charts”(Показывать графики по кластерам (?)).
Получается то же самое, что и раньше, просто по каждой возрастной группе отдельно. На графиках наглядно показано, как возраст влияет на зависимость между полом и качеством сна.
| sex * sleep * age Crosstabulation | ||||||
| Count | ||||||
| age | sleep | Total | ||||
| easy | quite well | difficult | ||||
| yonger than 30 | sex | man | ||||
| woman | ||||||
| Total | ||||||
| from 30 to 44 | sex | man | ||||
| woman | ||||||
| Total | ||||||
| from 45 to 59 | sex | man | ||||
| woman | ||||||
| Total | ||||||
| from 60 | sex | man | ||||
| woman | ||||||
| Total | ||||||
| Total | sex | man | ||||
| woman | ||||||
| Total |
| Chi-Square Tests | ||||
| age | Value | df | Asymp. Sig. (2-sided) | |
| yonger than 30 | Pearson Chi-Square | 2.887b | .236 | |
| Likelihood Ratio | 2.894 | .235 | ||
| Linear-by-Linear Association | 2.683 | .101 | ||
| N of Valid Cases | ||||
| from 30 to 44 | Pearson Chi-Square | .096c | .953 | |
| Likelihood Ratio | .096 | .953 | ||
| Linear-by-Linear Association | .007 | .935 | ||
| N of Valid Cases | ||||
| from 45 to 59 | Pearson Chi-Square | 13.455d | .001 | |
| Likelihood Ratio | 13.560 | .001 | ||
| Linear-by-Linear Association | 13.137 | .000 | ||
| N of Valid Cases | ||||
| from 60 | Pearson Chi-Square | 38.933e | .000 | |
| Likelihood Ratio | 39.324 | .000 | ||
| Linear-by-Linear Association | 37.729 | .000 | ||
| N of Valid Cases | ||||
| Total | Pearson Chi-Square | 24.178a | .000 | |
| Likelihood Ratio | 24.381 | .000 | ||
| Linear-by-Linear Association | 24.113 | .000 | ||
| N of Valid Cases | ||||
| a. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 192.99. | ||||
| b. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 30.23. | ||||
| c. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 36.66. | ||||
| d. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 58.35. | ||||
| e. 0 cells (0.0%) have expected count less than 5. The minimum expected count is 43.82. |
| Symmetric Measures | ||||||
| age | Value | Asymp. Std. Errora | Approx. Tb | Approx. Sig. | ||
| yonger than 30 | Interval by Interval | Pearson's R | -.069 | .042 | -1.641 | .101c |
| Ordinal by Ordinal | Spearman Correlation | -.071 | .042 | -1.700 | .090c | |
| N of Valid Cases | ||||||
| from 30 to 44 | Interval by Interval | Pearson's R | .004 | .046 | .082 | .935c |
| Ordinal by Ordinal | Spearman Correlation | .006 | .046 | .133 | .894c | |
| N of Valid Cases | ||||||
| from 45 to 59 | Interval by Interval | Pearson's R | .154 | .041 | 3.665 | .000c |
| Ordinal by Ordinal | Spearman Correlation | .155 | .042 | 3.700 | .000c | |
| N of Valid Cases | ||||||
| from 60 | Interval by Interval | Pearson's R | .302 | .047 | 6.434 | .000c |
| Ordinal by Ordinal | Spearman Correlation | .299 | .047 | 6.381 | .000c | |
| N of Valid Cases | ||||||
| Total | Interval by Interval | Pearson's R | .109 | .022 | 4.939 | .000c |
| Ordinal by Ordinal | Spearman Correlation | .108 | .022 | 4.870 | .000c | |
| N of Valid Cases | ||||||
| a. Not assuming the null hypothesis. | ||||||
| b. Using the asymptotic standard error assuming the null hypothesis. | ||||||
| c. Based on normal approximation. |




Тоже самое, что в пункте 2, построить для переменных age и sleep.
Делаете все те же операции, но меняете age и sleep местами.